







分类算法的判定依据:目标值为离散型
分类算法-k近邻算法(KNN)
基本概念:
举例:
根据特征判断:

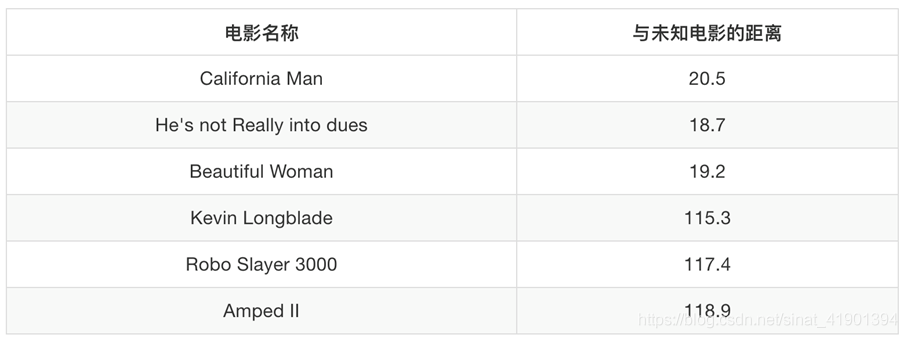
以上可以通过与未知电影的距离得出一个未知电影的类型。
k近邻算法定义: 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
来源: KNN算法最早是由Cover和Hart提出的一种分类算法
计算距离公式: 两个样本的距离可以通过如下公式计算,又叫欧式距离
比如说,a(a1,a2,a3),b(b1,b2,b3)
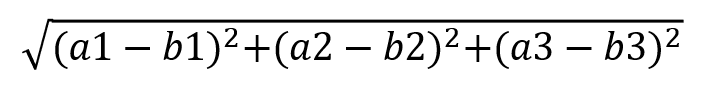
k近邻算法需要标准化
sklearn k-近邻算法API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
algorithm:{
‘auto’,‘ball_tree’,‘kd_tree’,‘brute’},可选用于
计算最近邻居的算法:‘ball_tree’将会使用 BallTree,‘kd_tree’将使
用 KDTree。‘auto’将尝试根据传递给fit方法的值来决定最合适的算法。
(不同实现方式影响效率)
K近邻算法实例–预测入住位置

数据描述:
- train.csv 、 test.csv
- row_id:登记时间的ID
- xy:坐标
- 准确性:定位准确性
- 时间:时间戳
- place_id:业务的ID,这是您预测的目标
分析过程:
这是一个分类问题
特征值:x,y坐标,定位准确性,时间
处理:
1.数据太多了,缩小数据集范围,省时间
DataFrame.query()
2.时间戳进行(年月日周时分秒),当作新的特征,处理日期数据
pd.to_datetime
pd.DatetimeIndex
3.将签到位置少于n个用户的删除
place_count =data.groupby('place_id').aggregate(np.count_nonzero)tf = place_count[place_count.row 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1503
1503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









