







 本文详细介绍了机器学习中的关键概念,如损失函数、预测函数和梯度下降方法(包括SGD、批量梯度下降、小批量梯度下降、Momentum、NAG和Adagrad/Adadelta)。探讨了这些优化算法在训练机器学习模型、深度学习和自然语言处理中的应用,以及它们的优缺点和实际应用场景。
本文详细介绍了机器学习中的关键概念,如损失函数、预测函数和梯度下降方法(包括SGD、批量梯度下降、小批量梯度下降、Momentum、NAG和Adagrad/Adadelta)。探讨了这些优化算法在训练机器学习模型、深度学习和自然语言处理中的应用,以及它们的优缺点和实际应用场景。
相关概念
损失函数:损失函数用于评估训练出的模型的拟合程度。损失函数越大,意味着模型拟合效果越差。在机器学习中,梯度下降法的根本目是在迭代中寻找损失函数的最小值,并通过反向传播的方式调整各个权重的大小,知道模型拟合程度达到指定要求。
预测函数:在机器学习中,为了拟合样本而采用预测函数。例如线性回归表达式中Y = WiX + B(Wi=W1,W2……WN),Wi表示权重,Y表示输出值,也成为预测值。而X表示输入值,也成为样本特征值。B在此处称为截距项,目的在于防止训练出的模型必定通过原点,提升了模型的适用范围
梯度是一个向量,其方向指向函数增长最快的方向,其大小等于函数在该方向上的增长率
学习率 α是 SGD 迭代过程中用于更新Θ参数的步长
批量梯度下降法【BGD】
就是一种通过求目标函数的导数来寻找目标函数最小化的方法。每次学习都使用整个训练集,因此这些计算是冗余的,因为每次都使用完全相同的样本集。但其优点在于每次更新都会朝着正确的方向进行,最后能够保证收敛于极值点,但是其缺点在于每次学习时间过长,如果训练集很大以至于需要消耗大量的内存。
计算公式:
![]()
解释:以下山为例:J是关于Θ的函数,当前所在置高点为Θ0,要从这个点走到J的最小值点,也就是山底。首先我们先确定前进的方向,也就是梯度的反向,然后走一段距离的步长,也就是α(α在梯度下降算法中被称作为学习率或者步长),走完这个段步长,就到达了Θ1这个点
例子:

随机梯度下降法【SGD】
是一种梯度下降法的变种,用于优化损失函数并更新模型参数。与传统的梯度下降法不同,SGD每次只使用一个样本来计算梯度和更新参数,而不是使用整个数据集。这种随机性使得SGD在大型数据集上更加高效,因为它在每次迭代中只需要处理一个样本。那么计算开销就从 O(n)下降到 O(1)
SGD迭代过程:

梯度下降法与随机梯度下降法比较:
随机梯度下降法和梯度下降法是两个极端,一个采用所有数据来梯度下降,一个用一个样本来梯度下降,自然各自的优缺点都非常突出。对于训练速度来说,随机梯度下降法由于每次仅仅采用一个样本来迭代,训练速度很快,参数更新频率太快;而批量梯度下降法在样本量很大的时候,训练速度很慢。对于准确度来说,随机梯度下降法用于仅仅用一个样本决定梯度方向,导致解很有可能不是最优。对于收敛速度来说,由于随机梯度下降法一次迭代一个样本,导致迭代方向变化很大,不能很快的收敛到局部最优解。
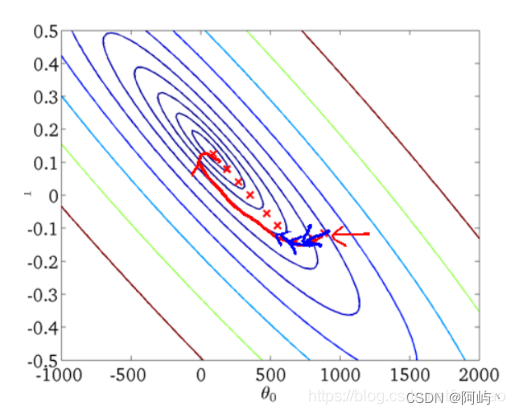
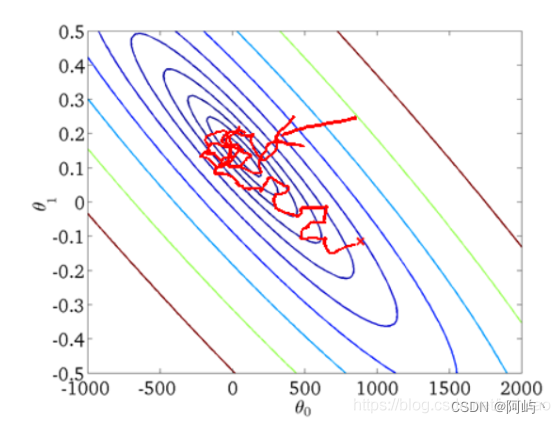
小批量梯度下降【MBGD】
小批量梯度下降(Mini-batch Gradient Descent)是介于上述两种方法之间的优化方法,即在更新参数时,只使用一部分样本(一般256以下)来更新参数,这样既可以保证训练过程更稳定,又可以利用批量训练方法中的矩阵计算的优势。MBGD在每次更新参数时使用b个样本(b一般为10)
迭代过程:

batch size越大,批次越少,训练时间会更快一点,但可能造成数据的很大浪费;而batch size越小,对数据的利用越充分,浪费的数据量越少,但批次会很大,训练会更耗时。
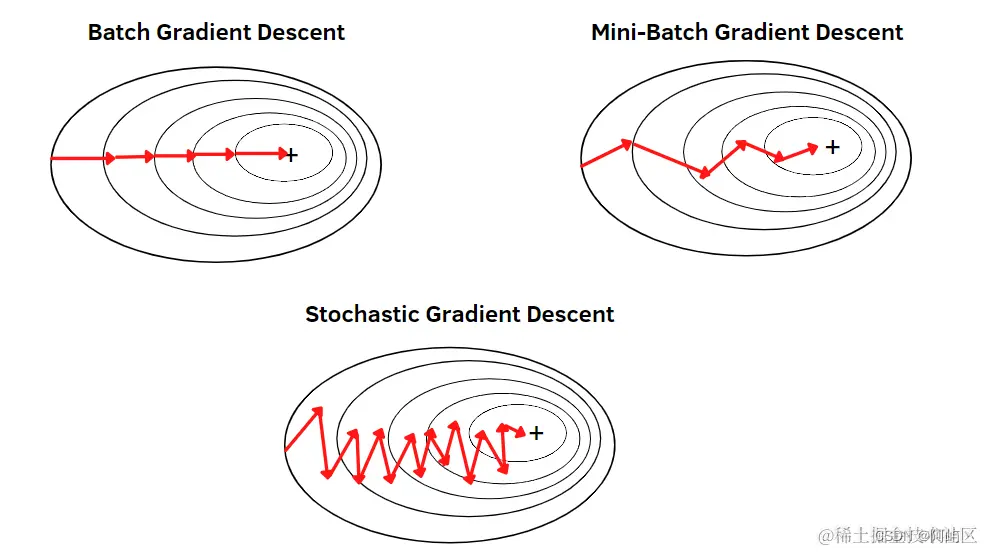
优势:
-
计算速度比批量梯度下降算法快,每次迭代时传入部分样本进行参数的更新。
-
在小批量选取样本时,我们可以将对参数更新影响效果较为相近的样本分为等价类,舍弃部分贡献较小的样本。
-
每次使用一个batch可以大大减小收敛所需要的迭代次数,同时可以使收敛到的结果更加接近梯度下降的效果。
缺点: (1)在迭代的过程中,因为噪音的存在,学习过程会出现波动。因此,它在最小值的区域徘徊,不会收敛。 (2)BATCH SIZE选择不当会影响收敛结果。
SGD进阶优化算法
Momentum 【SGDM】
为了抑制SGD的震荡,SGDM认为梯度下降过程可以加入惯性。可以简单理解为:当我们将一个小球从山上滚下来时,没有阻力的话,它的动量会越来越大,但是如果遇到了阻力,速度就会变小。SGDM全称是SGD with momentum,在SGD基础上引入了一阶动量:
vt=γvt−1+η∇J(θ)
SGD-M参数更新公式,其中η是学习率,∇J(θ)是当前参数的梯度
θ=θ−vt
一阶动量是各个时刻梯度方向的指数移动平均值,也就是说,t时刻的下降方向,不仅由当前点的梯度方向决定,而且由此前累积的下降方向决定。γ的经验值为0.9,这就意味着下降方向主要是此前累积的下降方向,并略微偏向当前时刻的下降方向。想象高速公路上汽车转弯,在高速向前的同时略微偏向,急转弯可是要出事的。 SGD 震荡且缓慢的沿着沟壑的下坡方向朝着局部最优点前进,如下图:
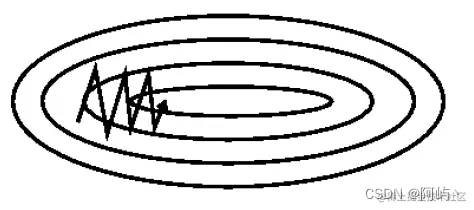
momentum能够加速SGD方法,并且能够减少震荡,如下图:

优点:因为加入了动量因素,SGD-M缓解了SGD在局部最优点梯度为0,无法持续更新的问题和振荡幅度过大的问题。
缺点:当局部沟壑比较深,动量加持用完了,依然会困在局部最优里来回振荡
NAG
NAG全称Nesterov Accelerated Gradient,是在SGD、SGD-M的基础上的进一步改进,我们知道在时刻t的主要下降方向是由累积动量决定的,自己的梯度方向说了也不算,那与其看当前梯度方向,不如先看看如果跟着累积动量走了一步,那个时候再怎么走。因此,NAG不计算当前位置的梯度方向,而是计算如果按照累积动量走了一步,那个时候的下降方向:
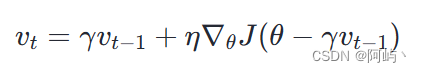
NAG参数更新公式,其中η是学习率,∇θJ(θ−γvt−1)是当前参数的梯度
![]()
然后用下一个点的梯度方向,与历史累积动量相结合,计算当前时刻的累积动量。
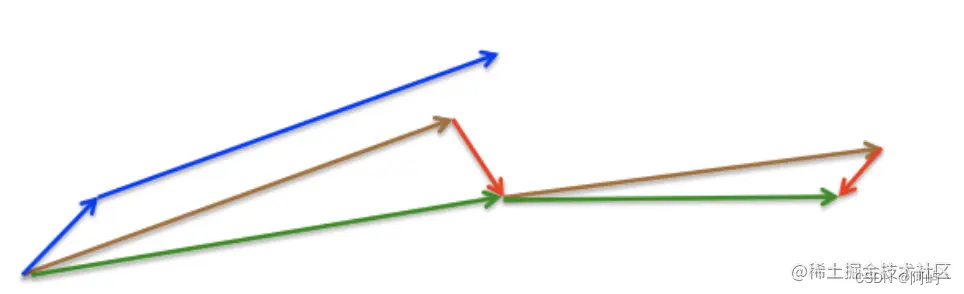
动量法首先计算当前梯度(图中的小蓝色向量),然后在更新累积梯度(updated accumulated gradient)方向上大幅度的跳跃(图中的大蓝色向量)。与此不同的是,NAG 首先在先前的累积梯度(previous accumulated gradient)方向上进行大幅度的跳跃(图中的棕色向量),评估这个梯度并做一下修正(图中的红色向量),这就构成一次完整的 NAG 更新(图中的绿色向量)。这种预期更新防止我们进行的太快,也带来了更高的相应速度,这在一些任务中非常有效的提升了 RNN 的性能。
优点:有利于跳出当前局部最优的沟壑,寻找新的最优值,但收敛速度慢
Adagrad
之前提到过这个问题:对于所有特征,我们的学习率一直没有变。怎么理解呢?假设我们用一批数据训练网络,这个数据中只有少部分数据含有某个特征,另一个特征几乎全部数据都具有,当这些数据通过训练时,对于不同特征我们假设对应于不同的神经元权重,对于都含有的特征,这些神经元对应参数更新很快,但是对于那些只有少部分数据含有的特征,对应神经元权重获得更新机会就少,但是由于学习率一样,这样可能导致神经网络训练的不充分。 adagrad算法就是为了解决这个问题,让学习率学习数据的特征自动调整其大小,adagrad算法引入了二阶动量,其表达式为:
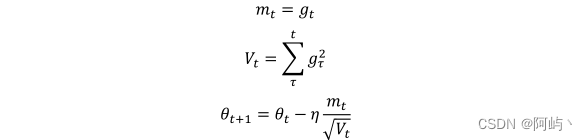
其中g(t)为t时刻参数梯度,下面来讲解为什么adagrad可以实现不同频率特征对其参数学习率改变,首先,我们看到二阶动量V(t),它是梯度平方累加和,对于训练数据少的特征,自然对应的参数更新就缓慢,也就是说他们的梯度变化平方累加和就会比较小,所以对应于上面参数更新方程中的学习速率就会变大,所以对于某个特征数据集少,相应参数更新速度就快。为了防止上述分母为0,所以往往添加一个平滑项参数ε,参数更新方程也就变成:
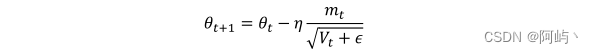
但是adagrad同样也有问题,就是其分母随着训练数增加,也会跟着增加,这样会导致学习速率越来越小,最终变的无限小,从而无法有效更新参数。
adadelta
Adadelta是 Adagrad 的扩展,旨在帮助缓解后者学习率单调下降的问题

梯度优化算法的实际应用
机器学习模型的训练: 梯度优化算法是训练机器学习模型的核心算法之一。在监督学习任务中,比如线性回归、逻辑回归、神经网络等模型的训练过程中,通常使用梯度下降法来更新模型参数。通过计算损失函数关于模型参数的梯度,并沿着梯度的反方向更新参数,模型可以逐渐减少预测误差,提高预测性能。
举例:

深度学习: 在深度学习领域,梯度优化算法被广泛用于训练神经网络。由于神经网络的复杂性,梯度下降法的不同变种,如随机梯度下降(SGD)、小批量梯度下降以及Adam等优化算法,被设计出来以提高训练的效率和稳定性。
自然语言处理: 在自然语言处理(NLP)任务中,如文本分类、机器翻译、情感分析等,梯度优化算法被用来训练语言模型和序列模型。这些模型通常包含大量的参数,梯度优化算法的使用可以有效地减少训练时间,提高模型的准确性。
举例:

控制策略优化: 在自动控制领域,梯度优化算法用于设计控制器参数,以优化系统的动态性能和稳态性能。例如,在机器人控制中,通过调整控制律以最小化跟踪误差或最大化能源效率。
说明:学习资料来源于网络















 101
101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









