







如果仅仅只是拿到十几首歌曲的相关信息,实际上并不能满足我们的需求。
爬取很多很多歌曲,而不只是爬取十几个。
我们以歌曲《七里香》作为案例,去爬取它的歌曲评论:
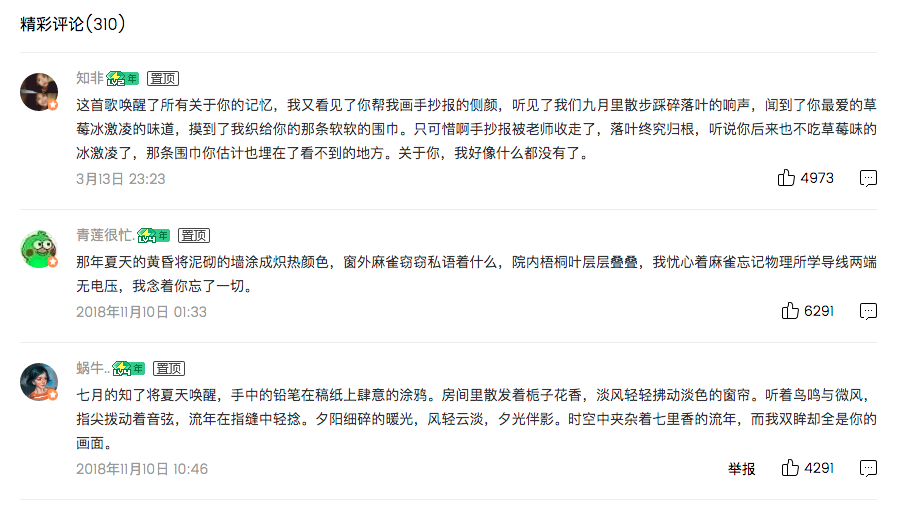
在Get到“爬取《七里香》评论”的技能后,我们会再回到爬取更多歌曲的项目当中。就好像你在玩游戏时,会先到新手村杀小怪涨经验再出村解锁新地图一样,爬取评论就是我们用来练手的“新手村”。
当然了,如果你开心,我们还可以把“爬取歌词”作为练习。
在这个过程当中,我们会学到带参数请求数据的知识,以及关于Request Headers的知识。
分析过程
你可能会疑惑,为什么不能直接爬取周杰伦的更多歌曲,来吧,先来打开偶像的qq音乐搜索链接:
如果仔细观察页面的内容,你可能会摇摇头,认为爬取更多的歌曲信息是一个不可能完成的任务,因为如今的qq音乐已经不支持更多歌曲的翻阅功能,正常访问的途径都没有了,我们的“虫”(代码)上哪爬取去?
退而求其次,咱们来看看评论这边的情况,目前qq音乐的评论页面结构是这样的:
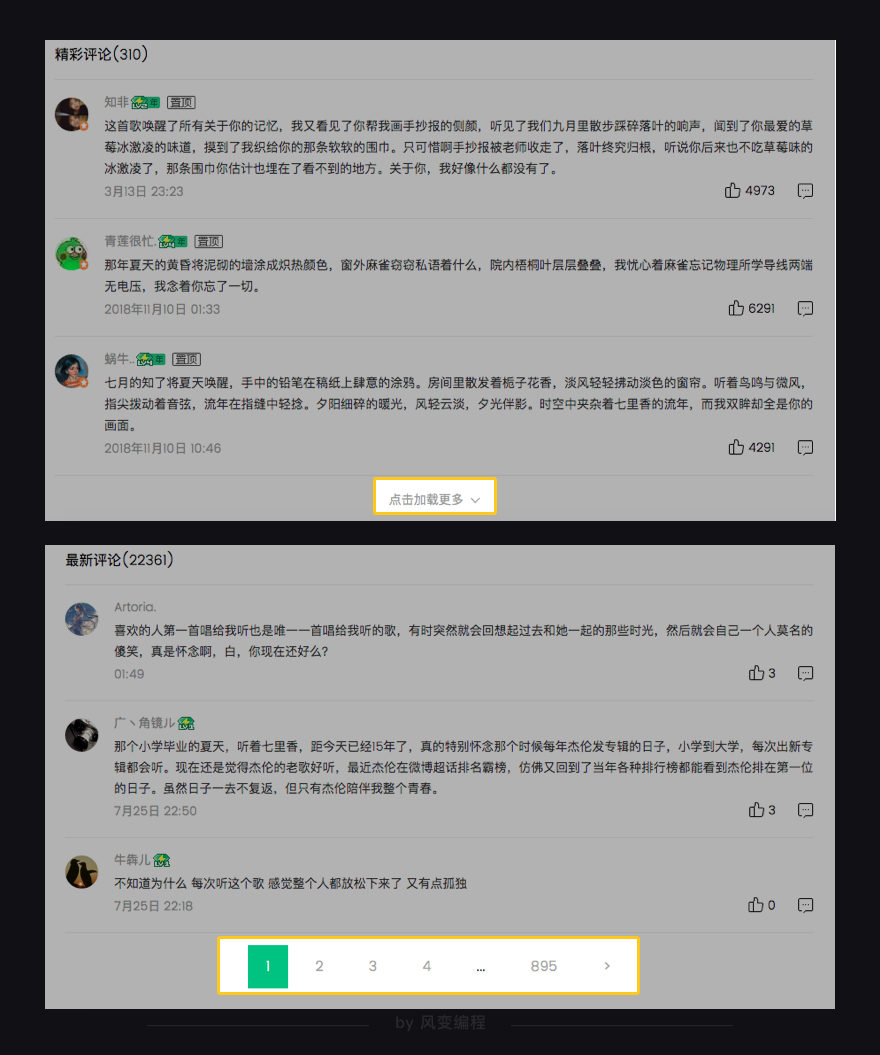
评论区分成了两部分,分别是精彩评论和最新评论,精彩评论可以通过点击加载更多获得更多数据,最新评论则需要翻页来进行数据更新。
也就是说,爬取更多的评论数据的难点似乎在翻页和点击加载更多。
显然这种数据的加载模式还是我们上一关熟悉的“动态加载”,即点击一个按钮(加载更多或者第n页),服务器就会根据新的XHR更新页面信息。
这样一来,若我们想要获得更多的评论数据,就需要:1️⃣点击按钮获得新的XHR 2️⃣根据新的XHR获得json数据 3️⃣解析json数据,如此循环往复,直至精神崩溃。
如果python有情绪,它的脸上现在肯定写满了嫌弃和拒绝。所以,看在python的面上,只要我们能找到每个请求之间的规律,这种重复的工作就交给它了好吗?
相比较爬取我们“看不见”(更多歌曲信息)的数据,评论这个能通过点击页码或加载更多按钮看到更多数据的“柿子”看起来比较软一点,就先捏它吧~
不过,解决评论的问题,需要用到“带参数请求数据”。学会这个,所有的问题都不再是问题。
什么是带参数请求数据
我不知道你有没有认真地观察过一个完整url的组成,如果没有,我们现在来试试看:
当你在豆瓣搜索“海边的卡夫卡”,它的网址会是这样:

当你在知乎搜索“宇宙大爆炸”,它的网址会是这样:

现在,我要揭晓规律:
在上面,我们能看到每个url都由两部分组成。前半部分大多形如:https://xx.xx.xxx/xxx/xxx
后半部分,多形如:xx=xx&xx=xxx&xxxxx=xx&……
两部分使用?来连接。举例刚刚的豆瓣网址,前半部分就是:
![]()
后半部分则是:q=%E6%B5%B7%E8%BE%B9%E7%9A%84%E5%8D%A1%E5%A4%AB%E5%8D%A1
它们的中间使用了?来隔开。
这前半部分是我们所请求的地址,它告诉服务器,我想访问这里。而后半部分,就是我们的请求所附带的参数,它会告诉服务器,我们想要什么样的数据。
这参数的结构,会和字典很像,有键有值,键值用=连接;每组键值之间,使用&来连接。
就像豆瓣。我们请求的地址是![]()
而我们的请求所附带的参数是“海边的卡夫卡”:q=%E6%B5%B7%E8%BE%B9%E7%9A%84%E5%8D%A1%E5%A4%AB%E5%8D%A1(那段你看不懂的代码,它是“海边的卡夫卡”使用utf-8编码的结果)。
技能点学满了吧?那现在,我们要以《七里香》为例,爬取用户的精彩评论。
首先,进入网址:
七里香 - 周杰伦 - QQ音乐-千万正版音乐海量无损曲库新歌热歌天天畅听的高品质音乐平台!
打开Network,选中All,点击刷新。

我们说到,第0个请求一般都会是html。我们点开第0个请求来看看(看Preview或Response都可以),看里面有没有我们想要的评论信息。
显然是没有的。我们现在去看XHR。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 231
231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











