






一、为什么要学习神经网络
神经网络实际上是一个相对古老的算法,并且后来沉寂了一段时间,不过到了现在,它又成为许多机器学习问题的首选技术。我们已经有线性回归和逻辑回归算法了,为什么还要研究神经网络?
我们首先来看几个机器学习问题作为例子,这几个问题的解决,都依赖于研究复杂的非线性分类器考虑这个监督学习分类的问题。 我们已经有了对应的训练集,如果利用逻辑回归算法来解决这个问题。 首先需要构造一个包含很多非线性项的,逻辑回归函数这里g仍是s型函数 (即f(x)=1/(1+e^-x) ) 。我们能让函数包含很多像这样的多项式项吗?事实上,当多项式项数足够多时,那么可能你能够得到一个分开正样本和负样本的分界线。当只有两项时,比如 x1、x2,这种方法确实能得到不错的结果。因为你可以把x1和x2的所有组合都包含到多项式中。

但是对于许多复杂的机器学习问题,特征值往往多于两项。比如下图中,在计算机视觉中,图像分类显得很重要,我们需要取每个像素点都是一个特征,对于50*50的图像,特征值也有2500个。对于这类问题,如果要包含所有的二次项即使只包含二项式或多项式的计算,最终的多项式也可能有很多项。 随着特征个数n的增加,二次项的个数大约以(n^2)/2的量级增长 ,三次项更多。因此要包含所有的二次项是很困难的,所以这可能不是一个好的做法。因为在处理这么多项时,不仅存在运算量过大的问题而且由于项数过多,最后的结果很有可能是过拟合的。 因此,我们需要学习解神经网络,它在解决复杂的非线性分类问题上。即使输入的特征维数n很大也能轻松搞定。

二、神经网络简介
神经网络产生的原因,是人们想尝试设计出模仿大脑的算法。从某种意义上说,如果我们想要建立学习系统,那为什么不去模仿我们所认识的最神奇的学习机器—— 人类的大脑呢?神经网络逐渐兴起于 二十世纪八九十年代,应用得非常广泛,但由于各种原因,在90年代的后期应用减少了。但是最近,神经网络又东山再起了。其中一个原因是,神经网络是计算量有些偏大的算法,由于近些年计算机的运行速度变快,才足以真正运行起大规模的神经网络。
当你想模拟大脑时,即指想制造出与人类大脑作用效果相同的机器。大脑可以学会去以看而不是听的方式处理图像,学会处理我们的触觉,我们能学习数学、微积分等等各种不同的令人惊奇的事情。似乎如果你想要模仿它,你得写很多不同的程序来模拟所有。不过能不能假设,大脑所做的这些,不需要用上千个不同的程序去实现,而只需要一个单一的学习算法就可以了?

尽管这只是一个假设,不过也有一些这方面的证据。如上图,大脑的这一小片红色区域,是听觉皮层 ,这靠的是耳朵。耳朵接收到声音信号,并把声音信号传递给你的听觉皮层。神经系统科学家做了以下实验,把耳朵到听觉皮层的神经切断,在这种情况下,将其重新接到一个动物的大脑上,这样从眼睛到视神经的信号最终将传到听觉皮层,那么结果表明,听觉皮层将会学会“看”。

来看另一个例子,上图这块红色的脑组织是你的躯体感觉皮层,这是用来处理触觉的。如果你做一个和刚才类似的重接实验,那么躯体感觉皮层也能学会”看“ 。这个实验和其它一些类似的实验被称为神经重接实验。实验结果表明,人体有同一块脑组织可以处理光、 声或触觉信号,那么也许存在一种学习算法可以同时处理 视觉、听觉和触觉,而不是需要运行上千个不同的算法来做这些。我们可以猜想,如果我们把任何一种传感器接入到大脑的几乎任何一个部位的话,大脑都会学会处理它。
三、神经元模型
我们该如何表示神经网络呢?换句话说,当我们在运用神经网络时,我们该如何表示我们的假设或模型。神经网络是在模仿大脑中的神经元或者神经网络时发明的。因此,要解释如何表示模型假设,我们先来看单个神经元在大脑中是什么样的。

我们的大脑中充满了这样的神经元,神经元是大脑中的细胞。其中有两点值得我们注意,一是神经元有像图中这样的细胞主体,二是神经元有一定数量的输入神经,这些输入神经叫做树突,可以把它们想象成输入电线,它们接收来自其他神经元的信息。神经元的输出神经叫做轴突,这些输出神经,是用来给其他神经元传递信号的。
简而言之,神经元是一个计算单元。它从输入神经接受一定数目的信息,并做一些计算。然后将结果通过它的轴突传送到大脑中的其他神经元。神经元利用微弱的电流进行沟通,这些弱电流也称作动作电位,其实就是一些微弱的电流。
人类思考的模型: 我们的神经元把自己的收到的消息进行计算,并向其他神经元传递消息。这也是我们的感觉和肌肉运转的原理。如果你想活动一块肌肉,就会触发一个神经元给你的肌肉发送脉冲,并引起肌肉收缩。如果一些感官比如说眼睛,想要给大脑传递一个消息,那么它就像这样发送电脉冲给大脑。
在我们在电脑上,实现的人工神经网络里,我们将使用一个非常简单的模型,来模拟神经元的工作。我们将神经元模拟成一个逻辑单元,用黄色圆圈表示。然后我们通过 它的树突或者说它的输入神经传递给它一些信息,然后神经元做一些计算。并通过它的输出神经,即它的轴突,输出计算结果。 如下图所示,这是一个简单的模拟神经元的模型。它被输入 x1 x2和 x3 ,然后输出一些类似这样的结果。

当绘制一个神经网络时,通常只绘制输入节点 x1 x2 x3,但有时也会增加一个额外的节点 x0。这个 x0 节点被称作偏置单位或偏置神经元 。但因为 x0 总是等于1, 所以有时候会画出它,有时不会画出,这取决于它是否对例子有利。
现在来讨论,最后一个关于神经网络的术语。有时我们会说上图这是一个有s型函数或者逻辑函数作为激励函数的人工神经元。在神经网络术语中,激励函数是对类似非线性函数g(z)的另一个术语称呼。 我一直称θ为模型的参数,而在关于神经网络的文献里,有时你可能会看到人们谈论一个模型的权重。 权重其实和模型的参数是一样的东西。
四、神经网络模型

神经网络其实就是这些不同的神经元组合在一起的集合。从图中可以看到,我们的输入单元 x1 x2和 x3,3个神经元a(2)1 a(2)2 和a(2)3 。然后再次说明,我们可以在这里 添加一个a0 和一个额外的偏度单元,它的值永远是1 。最后,我们在最后一层有第三个节点,此节点作为输出。
再说一点关于神经网络的术语。网络中的第一层也被称为输入层,因为我们在这一层,输入我们的特征项 x1 x2 x3 。最后一层称为输出层,因为这一层的神经元输出结果。 中间的一层被称作隐藏层,直觉上,在监督学习中,能看到输入,也能看到正确的输出,而隐藏层的值,在训练集里是看不到的。它的值不是 x 也不是y ,所以我们叫它隐藏层。神经网络可以有不止一个的隐藏层,实际上任何非输入层或非输出层的层,就被称为隐藏层。

接下来,让我们逐步分析这个神经网络所呈现的计算步骤。首先,这里还有些记号要解释一下。我们规定,使用a上标 (j) 下标 i ,表示第 j 层的第 i 个神经元或单元。 比如,a上标(2) 下标1 表示第2层的 第一个激励,即隐藏层的第一个激励。所谓激励(activation) ,是指由一个具体神经元读入计算并输出的值。此外,我们的神经网络被这些矩阵参数化,θ上标(j) 它将成为一个波矩阵,控制着从一层到另一层的作用。 各个隐藏单元以及输出层的计算如上图的式子。其中,θ(j)表示从第 j 层到(j+1)层的矩阵,每层都有自己的权重矩阵θ。θ(j)的尺寸是一个s_(j+1)*(s_j + 1)矩阵。因为输出节点将不包括偏置节点,而输入节点将包括偏置节点。比如,权重矩阵θ(1)控制着从输入层到隐藏层的传递。
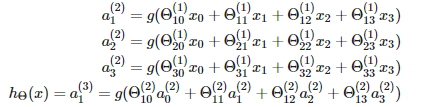
接下来,我们按照神经网络的计算顺序,对上述函数进行矢量化实现。我们将定义一个新变量z_k。在前面的示例中,如果将变量z替换为所有参数,则会得到:
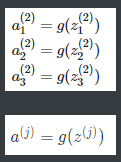
换句话说,对于层j = 2和节点k,变量z将为:
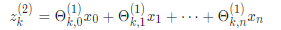
x和 z ^ {j}可以表示为向量形式:

请注意,在最后一步中,在第j层和第j + 1层之间,我们所做的事情与在逻辑回归中所做的完全相同。在神经网络中添加所有这些中间层,使我们能够更优雅地产生有趣且更复杂的非线性假设。
五、神经网络的具体计算
接下来,我们通过讲解一个具体的例子来解释神经网络是如何计算?关于输入的复杂的非线性函数,希望下面这个例子可以让你了解为什么神经网络可以用来学习复杂的非线性假设。

如上图所示,我们有二进制的输入特征 x1 x2 ,要么取0,要么取1 。所以x1和x2只能有两种取值。在这个例子中,我只画出了两个正样本和两个负样本。但你可以认为这是一个更复杂的学习问题的简化版本。在复杂问题中,我们可能在右上角有一堆正样本,在右下方有一堆用圆圈表示的负样本。我们需要学习一种非线性的决策边界来区分正负样本。
那么,神经网络是如何做到的呢?为了描述方便我用左边这个例子,这样更容易说明。我们取目标函数y为x1异或非x2,当它们同时为真或者同时为假的时候,我们将获得 y为1的结果。如果它们中仅有一个为真, y则为0 。我们想要知道是否能找到一个神经网络模型来拟合这种训练集。
为了建立能拟合XNOR运算的神经网络,我们先讲解一个稍微简单的神经网络,它拟合了“且运算”。假设我们有输入x1和 x2,并且都是二进制,即要么为0要么为1。我们的目标函数y等于x1且x2,这是一个逻辑与。那么,我们怎样得到一个具有单个神经元的神经网络来计算,这个逻辑与呢?为了做到这一点,我需要画出偏置单元,即这个里面有个+1的单元。然后给这个网络分配一些权重,如图上写出的这些参数,这里是-30,正20,正20,即h(x)等于 g(-30 + 20x1 + 20x2) 。在图上画出这些权重是很方便很直观的。

让我们来看看这个小神经元是怎样计算的,回忆一下s型激励函数g(z)如图。然后把输入值 x1和x2的四种可能输入带进去。 如果X1和X2均为 0, g(-30)非常接近于0。以此类推,得到上图中右下方的真值表。从表中可以发现,输出值近似等于x1和x2的与运算的值。

更复杂一点的,如上图所示,我们最终可以通过神经网络模型构造出XNOR函数。通过添加另一个层,我们得到了一个更复杂一点的函数。这就是关于神经网络可以计算较复杂函数的某种直观解释,我们知道,当层数很多的时候,你有一个相对简单的输入量的函数,作为第二层。而第三层可以建立在此基础上,来计算更加复杂一些的函数。然后再下一层,又可以计算再复杂一些的函数。















 1277
1277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









