






ok,上文我们对这个项目进行了背景介绍,介绍了相关的技术栈和运行结果。接下来我们来对代码进行介绍,帮助读者进一步的了解这个项目。代码和数据集放在文章末尾了。
数据集是这样子的,评论分为两类,label,review.其中label值为1代表积极评论,0代表消极评论。

数据加载部分代码
# 加载评论数据
data = pd.read_csv('ChnSentiCorp_htl_all.csv')
# 加载评论数据
# 重命名列名以匹配代码
data = data.rename(columns={'review': 'comment_text', 'label': 'sentiment'})
# 将情感标签转换为文本
data['sentiment'] = data['sentiment'].map({1: 'positive', 0: 'negative'})数据预处理部分:
def preprocess_text(text):
if isinstance(text, str): # 检查是否为字符串类型
# 去除特殊字符和标点符号
text = re.sub(r'[^\w\s]', '', text)
# 分词
words = jieba.cut(text)
# 去除停用词
stop_words = set() # 或者使用停用词表
# stop_words = set(stopwords.words('chinese'))
words = [word for word in words if word not in stop_words]
return ' '.join(words)
else:
# 处理非字符串类型,例如返回空字符串或进行其他处理
return ''训练并且对模型进行评估:
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
data['comment_text'], data['sentiment'], test_size=0.2, random_state=42
)
# 特征提取
vectorizer = TfidfVectorizer()
X_train_vec = vectorizer.fit_transform(X_train)
X_test_vec = vectorizer.transform(X_test)
# 模型训练
model = LogisticRegression()
model.fit(X_train_vec, y_train)
# 模型评估
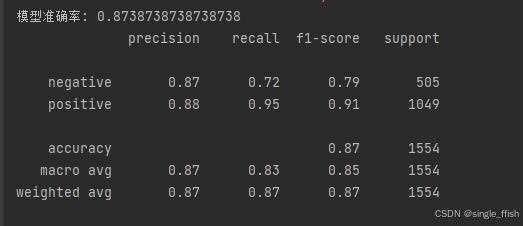
y_pred = model.predict(X_test_vec)
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy}")
print(classification_report(y_test, y_pred))对训练数据可视化:
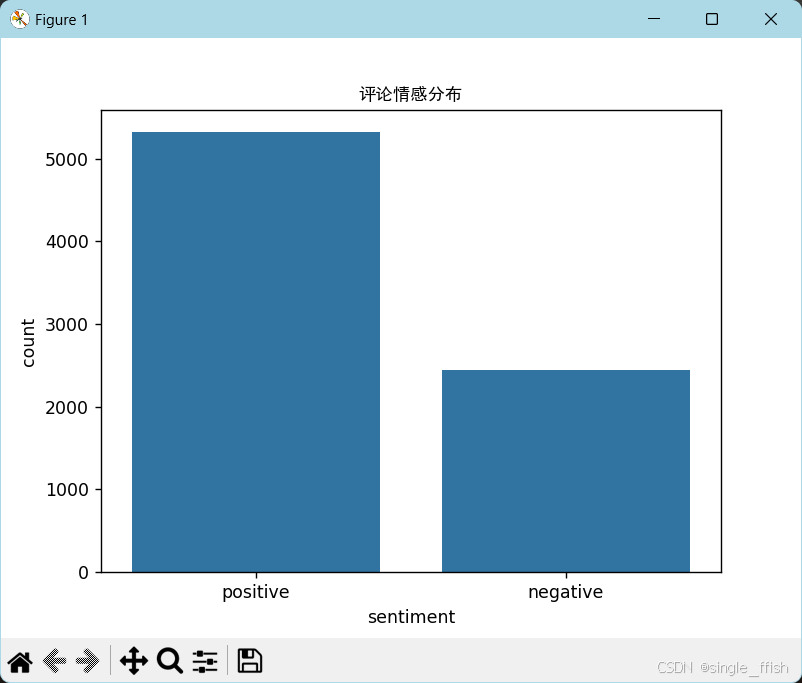
# 结果可视化
sns.countplot(x='sentiment', data=data)
plt.title('评论情感分布',fontproperties='SimHei')
plt.show()
# 生成关键词云
from wordcloud import WordCloud
import matplotlib.pyplot as plt
positive_comments = data[data['sentiment'] == 'positive']['comment_text']
negative_comments = data[data['sentiment'] == 'negative']['comment_text']
font_path = 'C:/Windows/Fonts/simhei.ttf' # 替换为您系统中的中文字体路径
font_prop = font_manager.FontProperties(fname=font_path)
# 生成正面评论关键词云
wordcloud = WordCloud(
width=800, height=400, background_color='white', collocations=False,font_path=font_path
).generate(' '.join(positive_comments))
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear' )
plt.axis('off')
plt.title('正面评论关键词云', fontproperties='SimHei')
plt.show()
# 生成负面评论关键词云
wordcloud = WordCloud(
width=800, height=400, background_color='white', collocations=False,font_path=font_path
).generate(' '.join(negative_comments))
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('负面评论关键词云',fontproperties='SimHei')
plt.show()全部代码:
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score, classification_report import matplotlib.pyplot as plt import seaborn as sns import re import jieba from matplotlib import font_manager # 加载评论数据 data = pd.read_csv('ChnSentiCorp_htl_all.csv') # 加载评论数据 # 重命名列名以匹配代码 data = data.rename(columns={'review': 'comment_text', 'label': 'sentiment'}) # 将情感标签转换为文本(如果需要) data['sentiment'] = data['sentiment'].map({1: 'positive', 0: 'negative'}) # 数据预处理 # def preprocess_text(text): # # 去除特殊字符和标点符号 # text = re.sub(r'[^\w\s]', '', text) # # 分词 # words = jieba.cut(text) # # 去除停用词 # stop_words=set() # # stop_words = set(stopwords.words('chinese')) # words = [word for word in words if word not in stop_words] # return ' '.join(words) # def preprocess_text(text): if isinstance(text, str): # 检查是否为字符串类型 # 去除特殊字符和标点符号 text = re.sub(r'[^\w\s]', '', text) # 分词 words = jieba.cut(text) # 去除停用词 stop_words = set() # 或者使用停用词表 # stop_words = set(stopwords.words('chinese')) words = [word for word in words if word not in stop_words] return ' '.join(words) else: # 处理非字符串类型,例如返回空字符串或进行其他处理 return '' data['comment_text'] = data['comment_text'].apply(preprocess_text) # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split( data['comment_text'], data['sentiment'], test_size=0.2, random_state=42 ) # 特征提取 vectorizer = TfidfVectorizer() X_train_vec = vectorizer.fit_transform(X_train) X_test_vec = vectorizer.transform(X_test) # 模型训练 model = LogisticRegression() model.fit(X_train_vec, y_train) # 模型评估 y_pred = model.predict(X_test_vec) accuracy = accuracy_score(y_test, y_pred) print(f"模型准确率: {accuracy}") print(classification_report(y_test, y_pred)) # 结果可视化 sns.countplot(x='sentiment', data=data) plt.title('评论情感分布',fontproperties='SimHei') plt.show() # 生成关键词云 from wordcloud import WordCloud import matplotlib.pyplot as plt positive_comments = data[data['sentiment'] == 'positive']['comment_text'] negative_comments = data[data['sentiment'] == 'negative']['comment_text'] font_path = 'C:/Windows/Fonts/simhei.ttf' # 替换为您系统中的中文字体路径 font_prop = font_manager.FontProperties(fname=font_path) # 生成正面评论关键词云 wordcloud = WordCloud( width=800, height=400, background_color='white', collocations=False,font_path=font_path ).generate(' '.join(positive_comments)) plt.figure(figsize=(10, 5)) plt.imshow(wordcloud, interpolation='bilinear' ) plt.axis('off') plt.title('正面评论关键词云', fontproperties='SimHei') plt.show() # 生成负面评论关键词云 wordcloud = WordCloud( width=800, height=400, background_color='white', collocations=False,font_path=font_path ).generate(' '.join(negative_comments)) plt.figure(figsize=(10, 5)) plt.imshow(wordcloud, interpolation='bilinear') plt.axis('off') plt.title('负面评论关键词云',fontproperties='SimHei') plt.show()
运行结果:




















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











