







1. 虚实映射——数据的起源
我们在什么时候需要记录数据,记录数据的目的又是什么?
本质上数据是对现实世界的抽象,桌面上有一个苹果,你可以将其记录为 apple: 1,又再将其关联到桌子,于是变成 desk : { apple : 1}。计算机科学的愿景是将世界抽象为一个机器能读懂的结构。从这个层面上说,我们在近二三十年的时间里,一直致力于建设虚拟世界,也就是尝试将现实世界中的一切事物,抽象到虚拟世界中去。
一开始这种抽象是极为原始的,比如说在计算机诞生之前所使用的打孔机,所记录的数据是简单的0和1的组合。计算机诞生之后,因为需要存储的数据越来越多,从线性结构到树形结构,再到图结构,从抽象数据类型到面向对象,后来又发展出支持并发访问的分布式存储数据结构(详见后续第五章内容)。
那么要把现实世界将数学、统计学、计算机科学、工程学、经济学、社会科学等知识建模到虚拟世界,最为核心而又最为基础的步骤是什么?答案是:分类。
我们无法了解我们没有命名的事物。——亚里士多德
语言既是人类认识世界的利器,同时也是形成简化与偏见的陷阱。然而,当数据需要产生实际效用时,你不但需要有一套描述的话语,也需要让人类可以在此基础之上协同的共识体系,这一套共识体系也就是定义以及标准。定义、标准是为人类共识所服务的,有共识才能够让更多的人在同一个框架下工作,而不至于产生各种各样的不兼容。
当我们“就数论数”之时,分类、定义乃至标准也就归集到了数据编目这一概念之上。那
既然数据编目以及编目标准是为人类共识所服务,那一个最小的共识单元又是什么?
2. 数据元
从使用者角度分析,一套数据编目必然是为一群人服务的,有时候也会为了不同组织之间的对接所服务,也就是不同组织间沟通的协议。
从数据库角度来看,数据编目的最小单元则是一个“数据元”,可以是一张表格中某一个字段定义,而表格的分类方法又会让这样的“数据元”变得多样。比如说你可以按照本体去分类,也可以按照业务需求分类,在数据库建模范式中,有经典的三范式建模,可以根据软件应用的需求,按照对象去进行抽象。
从语言学角度来看,数据编目的最小单元则变得更小了,可以是一个词甚至是一个字。
从社会学角度来看,可能是一个共享的价值观、规划或原则,这更偏向于我们能够理解的关于“共识”的定义。
综合下来,如果人类社会是一个整体,那第二层则是行业,行业之下还有领域,不同行业之间的领域共性区域有大有小,比如说财务领域在各行各业的共性域会较大,但销售域或者是客户域的差别就会大很多,这取决于你在售卖的商品和服务是什么。领域之下则是场景,场景之下分为一个又一个数据单元,而数据单元再细分则是字词(Words)和数值(Values)。由此定义延伸出来的一个共识最小单元是如下图的嵌套结构:
industry:{
domain:{
scene:{
key:value
}
}
}
从这个角度出发,你会发现本体论是对现实世界建模的一个很好的哲学范式。
本体论是研究存在的本质和性质的分支哲学。在计算机科学和信息科学领域,本体论是对现实世界知识的高级、结构化的表示,通常用于定义概念、分类以及它们之间的关系。
本体论的数据结构是经典的RDF(Resource Description Framework),或是OWL(Ontology Web Language)等。
这样复杂的结构意味着我们可以更为精确地表示实体之间的复杂关系和属性,支持高级的语义查询,而不仅仅是简单的数据检索。
我在刚进入数据行业之时,所接触到的建模范式要更为简单。一种是更多用于业务系统的三范式建模,通常以业务系统操作的实体对象为存储。另一种则是用于分析系统(OLAP)以检索为导向的星型+雪花建模,通常从分析的角度将数据区分为“维度”与“事实”。其中直观地去理解维度就是不怎么会变化,而是事物的一些固有属性值,事实则是以多个维度为交叉所产生的带有时间戳的过程数据。
比如酒店的维度可能包括门店、房型、房间等,而事实是每日的房晚、入住及离店时间、消费金额等;零售的维度可能包括分店、品牌、商品等,事实则是每日的销售额、库存数量、消费人数等;保险的维度可能包括保单类型、客户、营销员等,事实则是保额、保费、销售业绩等等。
从OLAP的角度,数据仓库从业者最容易想到的是,当我可以将一个行业里所有的维度与事实数据都遍历一遍的话,我就可以知道每一个行业需要进行衡量的各项指标。由此得到各行业专有的、规范化、共性的一套指标体系。
当我有了这样的指标体系之后,定制化的数据分析和深度的业务洞察就会成为可能。而数据仓库与商业智能的服务商则可以认为自己具备越来越多的行业经验,从而为客户提供更加精准、有效的解决方案。
然而,我们在这样的道路上却又遇到了更多现实的障碍。
首先,每个行业都有其独特的运营模式和市场变化,这使得“通用”指标体系在实际应用中可能并不完全适用。其次,数据的质量、完整性和时效性都可能影响到分析的准确性。此外,随着行业的不断发展和技术的进步,新的维度和事实可能不断出现,这需要我们不断地更新和调整指标体系。最后,企业内部的数据文化和接受程度也会影响到这套体系的应用和推广。
3. 数据孪生
既然数据一开始就是为了孪生而来——虚实相映,那为何不一开始就将其用本体论的结构来进行记录呢?除了涉及到不同数据结构所擅长的运算,导致了运转性能的不同之外(在第五章详述),另一方面是用本体论或者是基于知识图谱的范式来建模的成本太高了。因此,大部分的商业或非商业的数据记录都是以衡量为目的,也就是说,人们会先考虑What——“我们到底要测量什么”,然后再把How——“如何具体进行测量”需要的数据加进来。
所谓的“烟囱式建设”、“数据孤岛”等概念都由此而来。咋听上去,好像说的是以前的人都干的不对,实际不然。每一个阶段的数字世界建设都只能专注于解决当时迫切的若干问题,但每一次建设也都会制造出新的问题。这正正是人们对数字化建设抱有的最不切实际的期待——以为数字化可以帮助他们解决所有问题(隐含着其并不会导致新问题的妄念)。
系统论的基本前提是,一个新要素的引入,只会增加系统的复杂度而不是减少。纵观现在市面上的大数据平台,还有基于Apache开源体系的一整套解决方案,有哪一个不是变得越来越复杂,而这样的复杂性真的是我们所需要的吗?
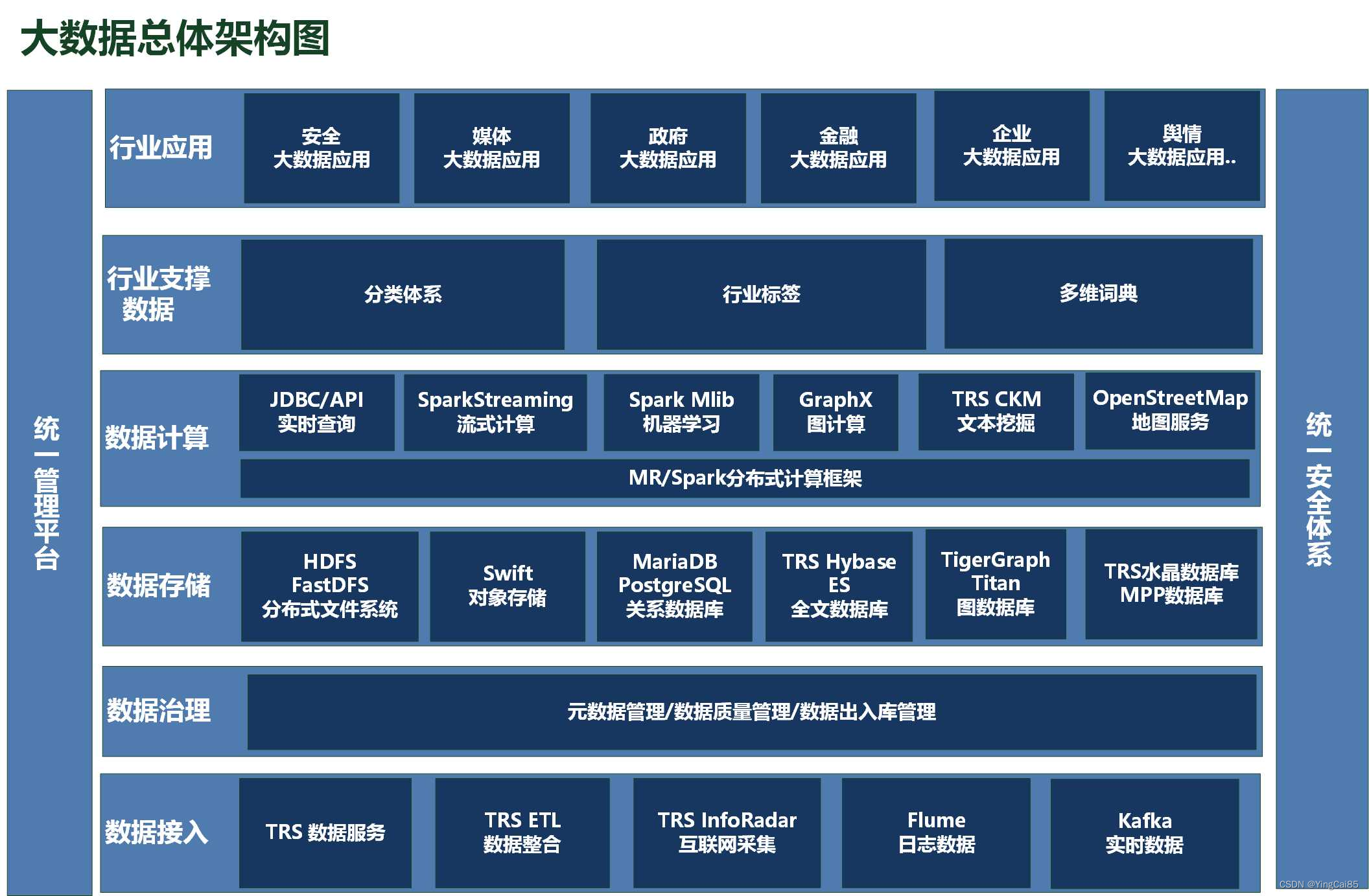
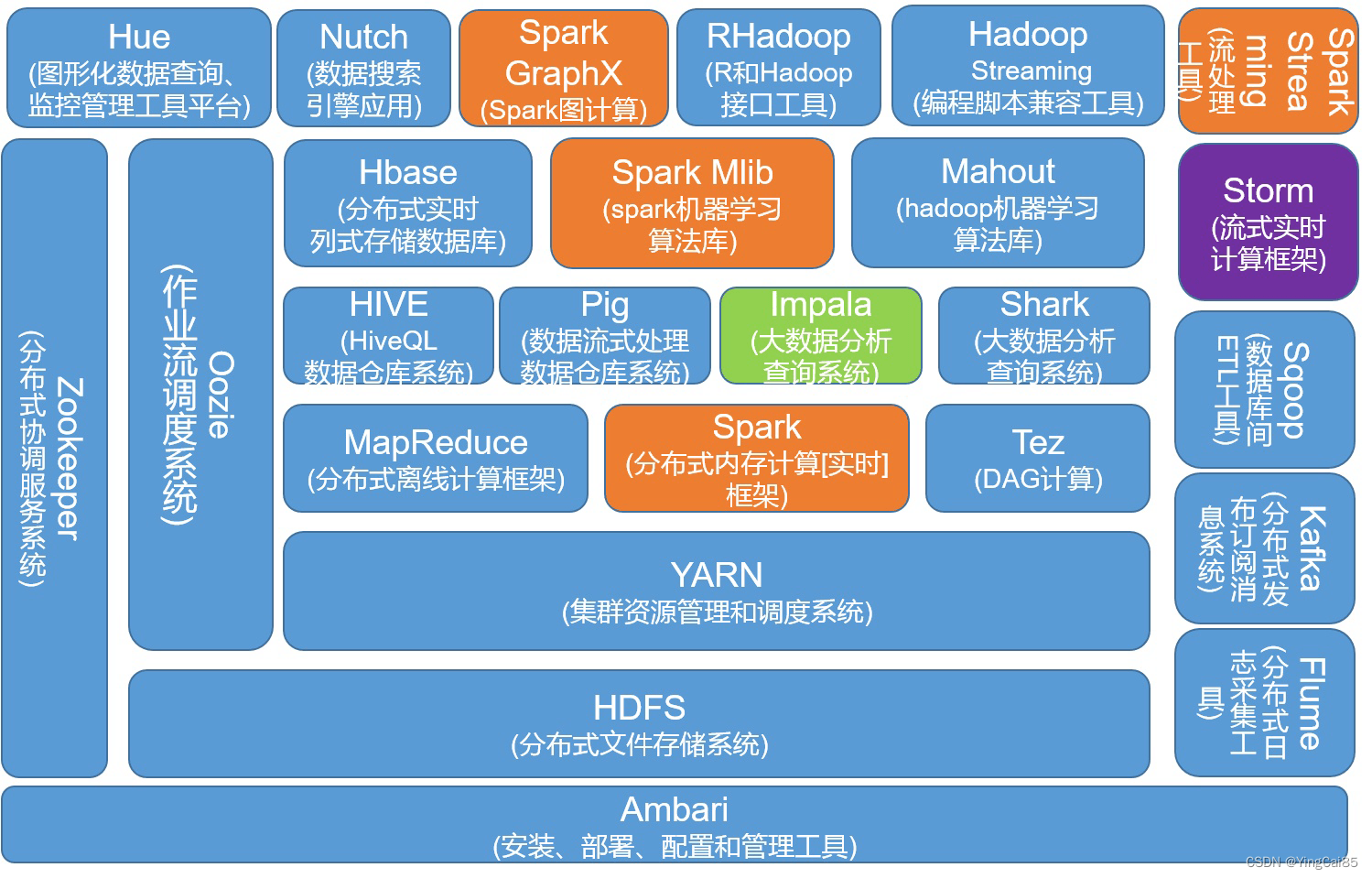
当我们大谈数字化赋能时,鲜少有会将复杂性天然的去能属性摆到台面来说。因为多数人都有风险厌恶,成单的要义在于让客户看到亮点,而非考虑损失。
4. 测量崩塌
其实每一家企业,乃至每一个人,他们收集数据的初衷都是纯粹的。一开始可能并不知道收集回来的数据有什么用,只是期待未来可从数据中挖掘出什么价值。这里的核心问题在于:复杂系统现象可以从数据演化而来吗?数据的积累有助于涌现吗?
或许ChatGPT在我们面前做了一次很好的涌现实验,但并非所有的数据都可以像文字语料那样拆得那么细,也不是所有数据的智能化都能通过Transformer这样大一统的模型来进行处理。比如最近几年开始逐渐增多的关于GeoAI的研究,就花了很多力气再解决时空数据异质性的问题,而该方向大量的AI研究者,也没有共识出一个效果较好的模型,有点像NLP在早期各种奇淫巧技的阶段。
除了AI技术本身的发展,测量本身的缺陷也难以避免,大致可分为几个方向
- 古德哈特定律:一个指标一旦成为评估的工具,它就不再是一个好指标;
- 观察者效应:当你知道自己被观察时,你的行为可能会发生改变,这也意味着通常测量的反效果是,人们总能想到规避的方法;
- 数据偏见与测量误差:数据来源、抽样方式、计算误差等等导致的测不准或有误差与偏见;
可以说,要实现数字孪生的首要任务,就是完成数据孪生——将你日常一举一动以及世界发生的所有变化都采集到虚拟世界里面来。这已经是一项看似不可完成的壮举了,然而即便所有数据都可以“孪生”进来,你仍然无法避免测量本身的崩塌,因为这些压根就不是演化的逻辑,而且机械的逻辑。我们会在第十讲重新回到这个话题,讨论个人的对策。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











