







 本文介绍了深度学习中网络超参数设定的重要技巧,包括输入数据像素大小、卷积层和池化层参数的设定。在训练方面,讨论了随机数据打乱、学习率设定以及各种优化算法如SGD、动量法、RMSProp和Adam。此外,还提到了微调神经网络的重要性及其策略。
本文介绍了深度学习中网络超参数设定的重要技巧,包括输入数据像素大小、卷积层和池化层参数的设定。在训练方面,讨论了随机数据打乱、学习率设定以及各种优化算法如SGD、动量法、RMSProp和Adam。此外,还提到了微调神经网络的重要性及其策略。
超参数设定
介绍一些重要的网络设计过程中的超参数设定技巧和训练技巧,如学习率,批规范化操作和网络优化化策略的选择。
网络超参数的设定
网络超参数设定在搭建整个网络架构之前,需首先指定与网络结构相关的各项超参数:输入图像像素,卷积层个数,卷积核相关参数。
输入数据像素大小
使用卷积神经网络处理图像问题时,对不同输入图像为得到同规格输出,同时便于GPU运行,会将图像压缩到 2 2 2^2 22大小。一些经典的案例例如:CIFAR-10 数据 32 × 32 像素,STL数据集的96 × 96像素。另外如果不考虑硬件设备限制(通常是GPU显存大小),更高分辨率的图像一般有利于网络性能提升更为显著。此外需要指出,由于一般卷积神经网络采用全连接层作为最后分类层,若直接改变原始网络模型的输入图像分辨率,会导致原始模型卷积层的最终输出无法输入全连接层的状况,此时要重新改变全连接层输入滤波器大小或重新指定其他相关参数。
卷积层参数的设定
卷积层的超参数主要包括卷积核大小,卷积操作的步长和卷积核个数。关于卷积核大小,小卷积相比大卷积的优势:
- 增加网络的容量和模型复杂程度
- 减少卷积参数个数
因此实践中推荐使用 3 × 3 及 5 × 5 这样的小卷积核,其对应的卷积操作步长设置为1
此外,卷积操作前还可以搭配填充操作(padding),该操作有两层功效 - 可充分利用和处理输入图像,或输入数据的边缘信息
- 搭配合适的卷积层参数可保持输出与输入同等大小,而避免随着网络的深度增加,输入大小的急剧减少。
通常来说,对卷积核大小 f * f, 步长为 1 的卷积操作,当 p =( f - 1 )/ 2 时,便可维持输出与原输入等大。
池化层参数
同卷积核大小类似,池化层的核大小一般也设定为比较小的值,如 2 * 2 , 3 * 3 等。常用的参数设定为2 * 2 , 池化步长为 2 。在此设定下,输出结果大小仅为输入数据长宽大小的 3 / 4。也就是说有 75% 的相应值被丢弃。这就起到了下采样的作用。为了不丢弃过多的输入相应而损失网络性能,池化操作极少使用超过 3 * 3 大小的池化操作。
训练技巧
训练数据随机打乱
在训练卷积神经网络时,尽管训练数据固定,但由于采用了随机批处理的训练机制,因此我们可在模型每轮训练进行前将训练数据随机打乱,以确保模型不同轮次相同批次看到的数据是不同的。这样的处理不仅会提高模型的收敛速度,而且,相对固定次序的训练模型,此操作会略微提升模型在测试集上的预测结果。
###学习率的设定
训练模型时另一关键设定便是模型学习率,一个理想的学习率会促进模型收敛,而不理想的学习率甚至会导致模型直接损失函数损失值爆炸无法完成训练,学习率的设定可遵循以下原则:
- 模型训练开始时初始学习率不宜过大,以0.01, 0.001为宜如果发现开始训练没几个轮次模型目标损失值就急剧上升,这说明模型训练学习率过大,此时应该减小学习率从头训练。
- 学习率应该随着轮次增加而减缓,减缓机制可有不同,一般为如下三种方式:
1)轮数减缓。如前五轮学习率减半,下一个五轮再减半。
2)指数减缓,即学习率按训练轮次增长指数插值递减,在matlab中可指定20轮每轮学习率为 lr = logspace(1e-2, 1e-5, 20) 3) 分数减缓 如果原始的学习率为 l 0 l_0 l0, 学习率按照下式递减, l r l_r lr = l 0 l_0 l0 / (1 + k t k_t kt) , k 为超参数用来控制学习率减缓幅度,t 为训练轮数。
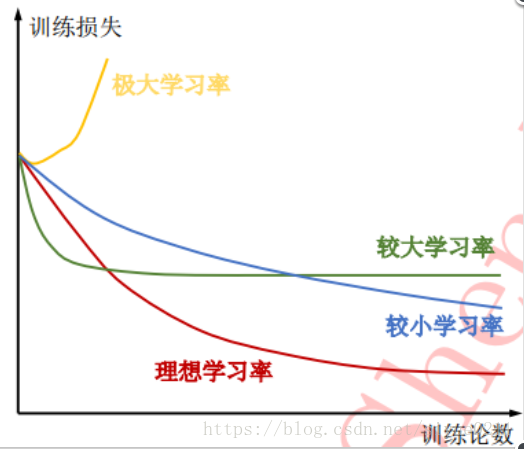
可使用模型训练曲线来判断当前学习率是否合适。 - 如果模型损失值在模型训练开始的几个批次直接爆炸,则学习率太大, 此时应该大幅减小学习率从头开始训练
- 若模型一开始损失值下降明显,但后劲不足(绿色线)此时应使用较小学习率从头开始训练,或在后几轮改小学习率仅重新训练几轮即可。
- 若模型损失值一直下降缓慢,(蓝色线)此时应稍微增大学习率,后继续观察训练曲线
什么是优化算法
优化算法的功能就是改善训练方式,来最小化(最大化)损失函数
模型内部有些参数,是用来计算测试集中目标值 Y 的真实值和预测值的偏差,基于这些参数,就形成了损失函数E(x)。
比如说,权重( ω ω ω)和偏差(b)就是这样的内部参数,一般用于计算输出值,在训练神经网络模型时起到主要作用。
在有效地训练模型并产生准确结果时,模型的内部参数起到了非常重要的作用。这也是为什么我们应该用各种优化策略和算法,来更新和计算影响模型训练和模型输出的网络参数,使其逼近或达到最优值。
优化算法分为两大类:
一阶优化算法
这种算法使用各参数的梯度值来最小化或最大化损失函数,最常用的一阶优化算法是梯度下降。
函数梯度:导数 dy / dx 的多变量表达式,用来表示y相对于x的瞬时变化率。往往为了计算多变量函数的导数时,会用梯度取代导数,并使用偏导数来计算梯度。梯度和导数之间的一个主要区别是函数的梯度形成了一个向量场。
因此,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









