






文章目录
概要
本文主要就是介绍如何使用Langchain和LLM生成知识图谱,并且对一些简单问题进行回答,在写代码之前需要安装一个知识图谱工具neo4j,安装包和说明文档我都放到资源里了
整体架构流程
整体架构流程就是
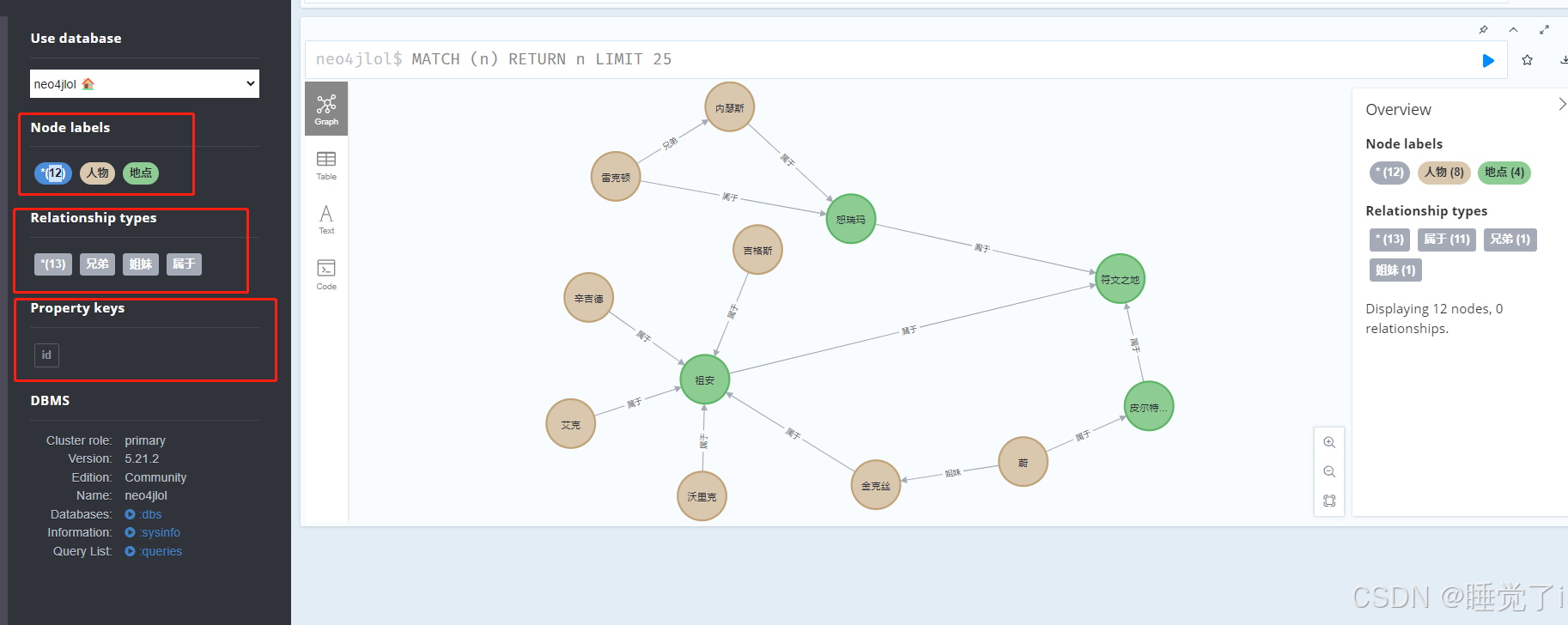
1.通过文档生成对应的知识图谱,知识图谱主要包括以下内容,这个是通过Langchain执行文档生成的知识图谱,节点即人物和地点,关系即兄弟、姐妹、属于,
还有一个属性这里是id,属性这一块应该可以分的更加具体,比如人物名称啊这些可以定义为name啊,地点啊定义为area等等,这块因为是通过Langchain生成的那就不多做操作了,感兴趣的小伙伴可以自行修改。
2.通过生成的知识图谱进行问答生成,同时也可以生成Cypher语句。
技术名词解释
- Neo4j 一个知识图谱的数据库,通过专有的Cypher语句进行增删改查。
技术细节
提示:需要安装的包pip install neo4j json-repair,Langchain的包请查看前面的两篇
话不多说直接上完整代码分为两大块
一、读取文档生成知识图谱
import os
from langchain_community.graphs import Neo4jGraph
from docx import Document as DocxDocument
from langchain_core.documents import Document
from langchain_experimental.graph_transformers import LLMGraphTransformer
from llm.model_init.init import LLModel
os.environ["DASHSCOPE_API_KEY"] = "sk-xxx"
os.environ["NEO4J_URI"] = "bolt://localhost:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_DATABASE"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "neo4j"
graph = Neo4jGraph()
# qwen api
api_key = "sk-df937c6e67ff46f6b1f4c406e281dd8b"
# 初始化大模型
llm_instance = LLModel(api_key=api_key)
# 返回llm
llm = llm_instance.initialize_Tongyi_model()
llm_transformer_filtered = LLMGraphTransformer(
llm=llm,
allowed_nodes=["人物", "地点"],
allowed_relationships=["属于", "姐妹", "兄弟"],
)
word_doc_path = r'D:\AI\人物关系.docx'
# 读取 Word 文档的内容
# 读取 Word 文档的内容,包括段落和表格
def read_word_document(doc_path):
doc = DocxDocument(doc_path)
full_text = []
# 读取段落内容
for para in doc.paragraphs:
full_text.append(para.text)
# 读取表格内容
for table in doc.tables:
for row in table.rows:
row_data = [cell.text for cell in row.cells]
full_text.append('\t'.join(row_data))
return '\n'.join(full_text)
# 将 Word 文档内容读取并转换为 Document 对象
document_text = read_word_document(word_doc_path)
if len(document_text) > 30000:
document_text = document_text[:30000]
documents = [Document(page_content=document_text)]
graph_documents = llm_transformer_filtered.convert_to_graph_documents(documents)
graph.add_graph_documents(graph_documents)
生成这一块就不过多阐述了,主要就是对文档的节点(allowed_nodes)和关系(allowed_relationships)的定义
llm_transformer_filtered = LLMGraphTransformer(
llm=llm,
allowed_nodes=["人物", "地点"],
allowed_relationships=["属于", "姐妹", "兄弟"],
)
二、通过自然语言结合知识图谱生成答案
import os
from langchain_community.chains.graph_qa.cypher import GraphCypherQAChain
from langchain_community.graphs import Neo4jGraph
from langchain_core.prompts import PromptTemplate
from llm.model_init.init import LLModel
# qwen api
api_key = "sk-xxx"
# 初始化大模型
llm_instance = LLModel(api_key=api_key)
# 返回llm
llm = llm_instance.initialize_Tongyi_model()
class Neo4jTest:
def neo4jInfo(query: str):
"""知识图谱工具,查询人物关系和隶属地区"""
os.environ["NEO4J_URI"] = "bolt://localhost:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "neo4j"
os.environ["NEO4J_DATABASE"] = "neo4j"
graph = Neo4jGraph()
# cypher提示词
cypher_generation_template = """
任务:
为Neo4j图数据库生成Cypher查询。
说明:
仅使用提供的模式中的关系类型和属性。
不要使用任何未提供的其他关系类型或属性。
仅return出现的所有节点,只需要return问题的节点
模式:
{schema}
Cypher examples1:
# 上海巴士第四公共交通有限公司有哪些线路
MATCH (com:com {{Company: "上海巴士第四公共交通有限公司"}})-[:OPERATED_BY]->(r:route)
MATCH (r)-[:lineOf]->(l:line)
WITH l
RETURN l
注意:
在回答中不要包含任何解释或道歉。
不要回答任何可能要求你构建除Cypher语句之外的任何文本的问题。
确保查询中的关系方向是正确的。
确保正确地为实体和关系设置别名。
不要运行会向数据库添加或删除内容的任何查询。
确保将后续所有语句都设置别名为with语句。
如果涉及线路指向节点的是routeNameA。
问题是:
{question},返回问题出现的节点,不要返回属性
"""
cypher_generation_prompt = PromptTemplate(
input_variables=["schema", "question"], template=cypher_generation_template
)
# 问答提示词
qa_generation_template = """您是一个助手,根据Neo4j Cypher查询的结果生成人类可读的响应。
查询结果部分包含基于用户自然语言问题生成的Cypher查询的结果。
提供的信息是权威的,您绝不能怀疑它或尝试使用内部知识来纠正它。
使答案听起来像对问题的回答。
不需要回答与问题无关的内容。
查询结果:
{context}
问题:
{question}
如果提供的信息为空,请说您不知道答案。
空信息的样子是这样的:[]
如果信息不为空,您必须使用结果提供答案。
"""
qa_generation_prompt = PromptTemplate(
input_variables=["context", "question"], template=qa_generation_template
)
# graph neo4j数据库连接
# llm 大模型
# verbose true则输出cypher语句和返回的Full Context
# validate_cypher true 确保语法正确,语义和底层数据匹配
hospital_cypher_chain = GraphCypherQAChain.from_llm(
llm=llm,
graph=graph,
verbose=True,
qa_prompt=qa_generation_prompt,
cypher_prompt=cypher_generation_prompt,
validate_cypher=True
)
response = hospital_cypher_chain.invoke(query)
response = response["result"]
return response
if __name__ == "__main__":
print("------" + Neo4jTest.neo4jInfo("祖安有哪些人物") + "------")
这里有几个重点部分,咱们拆开来讲
1.大模型的连接
这部分内容就是这一块
# qwen api
api_key = "sk-xxx"
# 初始化大模型
llm_instance = LLModel(api_key=api_key)
# 返回llm
llm = llm_instance.initialize_Tongyi_model()
LLModel工具在我的另一篇文章中基于LangChain+LLM(千问)的基础问答使用,非常基础的内容哦 可以看到
2.neo4j的连接和创建
def neo4jInfo(query: str):
"""知识图谱工具,查询人物关系和隶属地区"""
os.environ["NEO4J_URI"] = "bolt://localhost:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "neo4j"
os.environ["NEO4J_DATABASE"] = "neo4j"
graph = Neo4jGraph()
知识图谱工具,查询人物关系和隶属地区 这一段是工具的描述,这是后续agent需要学习的内容,可以进行一个了解,暂时直接理解为注释即可。
3.Cypher的提示词工程
我们可以看到这里吧主要包含几个点
1.return仅需要问题相关的节点
2.模式{schema},是包含在 graph = Neo4jGraph()的属性,是一个neo4j知识图谱整体结构的属性,有兴趣的可以debug看一下
3.Cypher examples 可以根据示例输出对应的Cypher,来对一些比较固定的回答生成答案。在提示词中{}里面的内容都是参数,如果要在提示词中使用{}变成文字,需要再加一个{{}},比如{{id: "蔚"}},对应的就是文字{id: "蔚"},这是cypher语句固定格式
4.解释一下Cypher语句
MATCH (ws:人物 {id: "蔚"})-[:姐妹]->(ss:人物) RETURN ws, ss
MATCH就是查询的意思,第一个ws是类似于sql里的别名,可以随意起然后 别名:人物(具体查询的节点)id即属性:”蔚”。
(ws:人物 {id: "蔚"})这个语句的意思就是人物名称是蔚,别名是ws
[:姐妹] 姐妹是关系,固定格式[:关系]
->连接查询结果
(ss:人物) 查询结果的节点是人物,ss别名
最终得出MATCH (ws:人物 {id: "蔚"})-[:姐妹]->(ss:人物) RETURN ws, ss 查询蔚(ws)的姐妹是哪个人物(ss)
# cypher提示词
cypher_generation_template = """
任务:
为Neo4j图数据库生成Cypher查询。
说明:
仅使用提供的模式中的关系类型和属性。
不要使用任何未提供的其他关系类型或属性。
仅return出现的所有节点,只需要return问题的节点
请根据示例输出一样的Cypher
模式:
{schema}
Cypher examples1:
# 薇的姐妹是谁
cypher
MATCH (ws:人物 {{id: "蔚"}})-[:姐妹]->(ss:人物)
RETURN ws, ss
注意:
在回答中不要包含任何解释或道歉。
不要回答任何可能要求你构建除Cypher语句之外的任何文本的问题。
确保查询中的关系方向是正确的。
确保正确地为实体和关系设置别名。
不要运行会向数据库添加或删除内容的任何查询。
确保将后续所有语句都设置别名为with语句。
问题是:
{question},返回问题出现的节点,不要返回属性
"""
#提示词中的schema是graph 中的属性,question就是问题
cypher_generation_prompt = PromptTemplate(
input_variables=["schema", "question"], template=cypher_generation_template
)
4.问答的提示词工程
很简单就是传入context结果和question,context也是在graph中生成的答案
# 问答提示词
qa_generation_template = """您是一个助手,根据Neo4j Cypher查询的结果生成人类可读的响应。
查询结果部分包含基于用户自然语言问题生成的Cypher查询的结果。
提供的信息是权威的,您绝不能怀疑它或尝试使用内部知识来纠正它。
使答案听起来像对问题的回答。
不需要回答与问题无关的内容。
查询结果:
{context}
问题:
{question}
如果提供的信息为空,请说您不知道答案。
空信息的样子是这样的:[]
如果信息不为空,您必须使用结果提供答案。
"""
qa_generation_prompt = PromptTemplate(
input_variables=["context", "question"], template=qa_generation_template
)
5.neo4j和大模型的应用
通过GraphCypherQAChain方法执行大模型,还有包含一些参数输入的含义都在注释里
# graph neo4j数据库连接
# llm 大模型
# verbose true则输出cypher语句和返回的Full Context
# validate_cypher true 确保语法正确,语义和底层数据匹配
hospital_cypher_chain = GraphCypherQAChain.from_llm(
llm=llm,
graph=graph,
verbose=True,
qa_prompt=qa_generation_prompt,
cypher_prompt=cypher_generation_prompt,
validate_cypher=True
)
response = hospital_cypher_chain.invoke(query)
response = response["result"]
return response
6.尝试调用
首先查询示例中的问答薇的姐妹是谁
if __name__ == "__main__":
print("------" + Neo4jTest.neo4jInfo("薇的姐妹是谁") + "------")
提示:尝试调用代码之前,这里有部分源码需要修改E:\conda\envs\fastApiProject\Lib\site-packages\langchain_community\chains\graph_qa\cypher.py
1.查询context = self.graph.query(generated_cypher)[: self.top_k]
去除[: self.top_k]部分,否则问答输出有限
2.查询chain_result: Dict[str, Any] = {self.output_key: final_result}
修改为 修改返回格式增加cypher语句和context内容
chain_result: Dict[str, Any] = {
self.output_key: final_result,
"cypher_query": generated_cypher,
"context": context
}
3.如果出现ValueError: In order to use this chain, you must acknowledge that it can make dangerous requests by setting allow_dangerous_requests to True.报错内容
allow_dangerous_requests: bool = False
修改为True (官方解释改为True 强制用户选择加入以确认链可以发出危险的请求)
这个问题可能是版本原因,有的版本没有这个问题
大模型回答
D:\AI\conda\envs\aiAgent\python.exe D:\Pycharm\aiAgent\pythonProject\llm\neo4j\neo4j_test.py
> Entering new GraphCypherQAChain chain...
Generated Cypher:
cypher
MATCH (ws:人物 {id: "蔚"})-[:姐妹]->(ss:人物)
RETURN ws, ss
Full Context:
[{'ws': {'id': '蔚'}, 'ss': {'id': '金克丝'}}]
> Finished chain.
------薇的姐妹是金克丝。------
Process finished with exit code 0
然后再问一个祖安有些人
D:\AI\conda\envs\aiAgent\python.exe -X pycache_prefix=C:\Users\yuanzhuo\AppData\Local\JetBrains\PyCharm2024.1\cpython-cache "D:/Pycharm/PyCharm 2024.1.6/plugins/python/helpers/pydev/pydevd.py" --multiprocess --qt-support=auto --client 127.0.0.1 --port 56810 --file D:\Pycharm\aiAgent\pythonProject\llm\neo4j\neo4j_test.py
Connected to pydev debugger (build 241.19072.16)
> Entering new GraphCypherQAChain chain...
Generated Cypher:
cypher
MATCH (z:地点 {id: "祖安"})<-[:属于]-(p:人物)
RETURN p, z
Full Context:
[{'p': {'id': '沃里克'}, 'z': {'id': '祖安'}}, {'p': {'id': '金克丝'}, 'z': {'id': '祖安'}}, {'p': {'id': '艾克'}, 'z': {'id': '祖安'}}, {'p': {'id': '辛吉德'}, 'z': {'id': '祖安'}}, {'p': {'id': '吉格斯'}, 'z': {'id': '祖安'}}]
> Finished chain.
------祖安有以下人物:沃里克、金克丝、艾克、辛吉德和吉格斯。------
Process finished with exit code 0
如果你想修改final_result的格式也可以在问答的提示词中展示示例
# 问答提示词
qa_generation_template = """您是一个助手,根据Neo4j Cypher查询的结果生成人类可读的响应。
查询结果部分包含基于用户自然语言问题生成的Cypher查询的结果。
提供的信息是权威的,您绝不能怀疑它或尝试使用内部知识来纠正它。
使答案听起来像对问题的回答。
不需要回答与问题无关的内容。
查询结果:
{context}
问题:
{question}
示例1:
问题:祖安有哪些人
回答:英雄联盟祖安包含的英雄有
如果提供的信息为空,请说您不知道答案。
空信息的样子是这样的:[]
如果信息不为空,您必须使用结果提供答案。
"""
按照示例的回答祖安有哪些人
D:\AI\conda\envs\aiAgent\python.exe D:\Pycharm\aiAgent\pythonProject\llm\neo4j\neo4j_test.py
> Entering new GraphCypherQAChain chain...
Generated Cypher:
cypher
MATCH (z:地点 {id: "祖安"})<-[:属于]-(p:人物)
RETURN z, p
Full Context:
[{'z': {'id': '祖安'}, 'p': {'id': '沃里克'}}, {'z': {'id': '祖安'}, 'p': {'id': '金克丝'}}, {'z': {'id': '祖安'}, 'p': {'id': '艾克'}}, {'z': {'id': '祖安'}, 'p': {'id': '辛吉德'}}, {'z': {'id': '祖安'}, 'p': {'id': '吉格斯'}}]
> Finished chain.
------英雄联盟祖安包含的英雄有沃里克、金克丝、艾克、辛吉德和吉格斯。------
Process finished with exit code 0
小结
是不是很简单,知识图谱是一种结构化知识的表示形式,通过节点和边来表示实体及其之间的关系,我们可以实现增强搜索引擎效果、智能问答、推荐系统、语义理解与文本分析、数据整合与管理等等功能,感谢大家的观看,希望对你有帮助,谢谢。


















 770
770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









