







16.1 — Object relationships
Similarly, programming is also full of recurring patterns, relationships and hierarchies. Particularly when it comes to programming objects, the same patterns that govern real-life objects are applicable to the programming objects we create ourselves. By examining these in more detail, we can better understand how to improve code reusability and write classes that are more extensible.
16.2 — Composition
In real-life, complex objects are often built from smaller, simpler objects. For example, a car is built using a metal frame, an engine, some tires, a transmission, a steering wheel, and a large number of other parts. A personal computer is built from a CPU, a motherboard, some memory, etc… Even you are built from smaller parts: you have a head, a body, some legs, arms, and so on. This process of building complex objects from simpler ones is called object composition.
In C++, you’ve already seen that structs and classes can have data members of various types (such as fundamental types or other classes). When we build classes with data members, we’re essentially constructing a complex object from simpler parts, which is object composition. For this reason, structs and classes are sometimes referred to as composite types.
Types of object composition
There are two basic subtypes of object composition: composition and aggregation. We’ll examine composition in this lesson, and aggregation in the next.
A note on terminology: the term “composition” is often used to refer to both composition and aggregation, not just to the composition subtype. In this tutorial, we’ll use the term “object composition” when we’re referring to both, and “composition” when we’re referring specifically to the composition subtype.
Composition
To qualify as a composition, an object and a part must have the following relationship:
- The part (member) is part of the object (class)
- The part (member) can only belong to one object (class) at a time
- The part (member) has its existence managed by the object (class)
- The part (member) does not know about the existence of the object (class)
In a composition relationship, the object is responsible for the existence of the parts. Most often, this means the part is created when the object is created, and destroyed when the object is destroyed. But more broadly, it means the object manages the part’s lifetime in such a way that the user of the object does not need to get involved. For example, when a body is created, the heart is created too. When a person’s body is destroyed, their heart is destroyed too. Because of this, composition is sometimes called a “death relationship”.
Composition is often used to model physical relationships, where one object is physically contained inside another.
Implementing compositions
In general, if you can design a class using composition, you should design a class using composition. Classes designed using composition are straightforward, flexible, and robust (in that they clean up after themselves nicely).
More examples
Variants on the composition theme
The key point here is that the composition should manage its parts without the user of the composition needing to manage anything.
Composition and class members
16.3 — Aggregation
Aggregation
To qualify as an aggregation, a whole object and its parts must have the following relationship:
- The part (member) is part of the object (class)
- The part (member) can (if desired) belong to more than one object (class) at a time
- The part (member) does not have its existence managed by the object (class)
- The part (member) does not know about the existence of the object (class)
Implementing aggregations
Let’s take a look at a Teacher and Department example in more detail. In this example, we’re going to make a couple of simplifications: First, the department will only hold one teacher. Second, the teacher will be unaware of what department they’re part of.
#include <iostream>
#include <string>
class Teacher
{
private:
std::string m_name{};
public:
Teacher(const std::string& name)
: m_name{ name }
{
}
const std::string& getName() const { return m_name; }
};
class Department
{
private:
const Teacher& m_teacher; // This dept holds only one teacher for simplicity, but it could hold many teachers
public:
Department(const Teacher& teacher)
: m_teacher{ teacher }
{
}
};
int main()
{
// Create a teacher outside the scope of the Department
Teacher bob{ "Bob" }; // create a teacher
{
// Create a department and use the constructor parameter to pass
// the teacher to it.
Department department{ bob };
} // department goes out of scope here and is destroyed
// bob still exists here, but the department doesn't
std::cout << bob.getName() << " still exists!\n";
return 0;
}
In this case, bob is created independently of department, and then passed into department‘s constructor. When department is destroyed, the m_teacher reference is destroyed, but the teacher itself is not destroyed, so it still exists until it is independently destroyed later in main().
Pick the right relationship for what you’re modeling
Although it might seem a little silly in the above example that the Teachers don’t know what Department they’re working for, that may be totally fine in the context of a given program. When you’re determining what kind of relationship to implement, implement the simplest relationship that meets your needs, not the one that seems like it would fit best in a real-life context.
For example, if you’re writing a body shop simulator, you may want to implement a car and engine as an aggregation, so the engine can be removed and put on a shelf somewhere for later. However, if you’re writing a racing simulation, you may want to implement a car and an engine as a composition, since the engine will never exist outside of the car in that context.
Best practice
Implement the simplest relationship type that meets the needs of your program, not what seems right in real-life.
Summarizing composition and aggregation
Compositions:
-
Typically use normal member variables
-
Can use pointer members if the class handles object allocation/deallocation itself
-
Responsible for creation/destruction of parts
Aggregations: -
Typically use pointer or reference members that point to or reference objects that live outside the scope of the aggregate class
-
Not responsible for creating/destroying parts
It is worth noting that the concepts of composition and aggregation can be mixed freely within the same class. It is entirely possible to write a class that is responsible for the creation/destruction of some parts but not others. For example, our Department class could have a name and a Teacher. The name would probably be added to the Department by composition, and would be created and destroyed with the Department. On the other hand, the Teacher would be added to the department by aggregation, and created/destroyed independently.
While aggregations can be extremely useful, they are also potentially more dangerous, because aggregations do not handle deallocation of their parts. Deallocations are left to an external party to do. If the external party no longer has a pointer or reference to the abandoned parts, or if it simply forgets to do the cleanup (assuming the class will handle that), then memory will be leaked.
For this reason, compositions should be favored over aggregations.
A few warnings/errata
For a variety of historical and contextual reasons, unlike a composition, the definition of an aggregation is not precise – so you may see other reference material define it differently from the way we do. That’s fine, just be aware.
One final note: In the lesson 10.5 – Introduction to structs, members, and member selection, we defined aggregate data types (such as structs and classes) as data types that group multiple variables together. You may also run across the term aggregate class in your C++ journeys, which is defined as a struct or class that has no provided constructors, destructors, or overloaded assignment, has all public members, and does not use inheritance – essentially a plain-old-data struct. Despite the similarities in naming, aggregates and aggregation are different and should not be confused.
std::reference_wrapper
#include <functional> // std::reference_wrapper
#include <iostream>
#include <vector>
#include <string>
int main()
{
std::string tom{ "Tom" };
std::string berta{ "Berta" };
std::vector<std::reference_wrapper<std::string>> names{ tom, berta }; // these strings are stored by reference, not value
std::string jim{ "Jim" };
names.push_back(jim);
for (auto name : names)
{
// Use the get() member function to get the referenced string.
name.get() += " Beam";
}
std::cout << jim << '\n'; // Jim Beam
return 0;
}
To create a vector of const references, we’d have to add const before the std::string like so
// Vector of const references to std::string
std::vector<std::reference_wrapper<const std::string>> names{ tom, berta };
16.4 — Association
To qualify as an association, an object and another object must have the following relationship:
- The associated object (member) is otherwise unrelated to the object (class)
- The associated object (member) can belong to more than one object (class) at a time
- The associated object (member) does not have its existence managed by the object (class)
- The associated object (member) may or may not know about the existence of the object (class)
Implementing associations
Because associations are a broad type of relationship, they can be implemented in many different ways. However, most often, associations are implemented using pointers, where the object points at the associated object.
Reflexive association
Sometimes objects may have a relationship with other objects of the same type. This is called a reflexive association. A good example of a reflexive association is the relationship between a university course and its prerequisites (which are also university courses).
Associations can be indirect
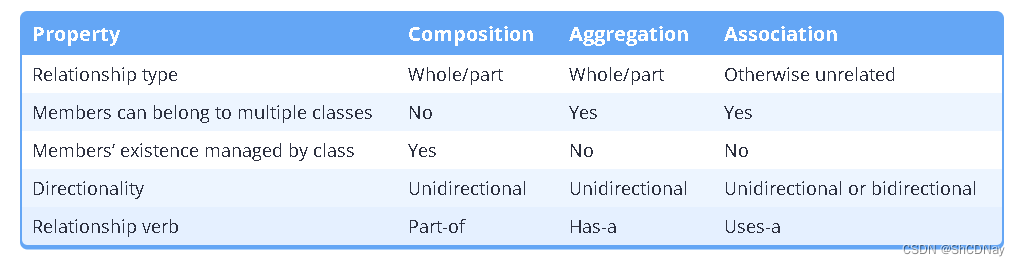
Composition vs aggregation vs association summary
Composition vs aggregation vs association summary
Here’s a summary table to help you remember the difference between composition, aggregation, and association:
16.5 — Dependencies
A dependency occurs when one object invokes another object’s functionality in order to accomplish some specific task. This is a weaker relationship than an association, but still, any change to object being depended upon may break functionality in the (dependent) caller. A dependency is always a unidirectional relationship.
A good example of a dependency that you’ve already seen many times is std::ostream. Our classes that use std::ostream use it in order to accomplish the task of printing something to the console, but not otherwise.
In the above code, Point isn’t directly related to std::ostream, but it has a dependency on std::ostream since operator<< uses std::ostream to print the Point to the console.
Dependencies vs Association in C++
There’s typically some confusion about what differentiates a dependency from an association.
In C++, associations are a relationship between two classes at the class level. That is, one class keeps a direct or indirect “link” to the associated class as a member. For example, a Doctor class has an array of pointers to its Patients as a member. You can always ask the Doctor who its patients are. The Driver class holds the id of the Car the driver object owns as an integer member. The Driver always knows what Car is associated with it.
Dependencies typically are not represented at the class level – that is, the object being depended on is not linked as a member. Rather, the object being depended on is typically instantiated as needed (like opening a file to write data to), or passed into a function as a parameter (like std::ostream in the overloaded operator<< above).
Humor break
16.6 — Container classes
In real life, we use containers all the time. Your breakfast cereal comes in a box, the pages in your book come inside a cover and binding, and you might store any number of items in containers in your garage. Without containers, it would be extremely inconvenient to work with many of these objects. Imagine trying to read a book that didn’t have any sort of binding, or eat cereal that didn’t come in a box without using a bowl. It would be a mess. The value the container provides is largely in its ability to help organize and store items that are put inside it.
Similarly, a container class is a class designed to hold and organize multiple instances of another type (either another class, or a fundamental type). There are many different kinds of container classes, each of which has various advantages, disadvantages, and restrictions in their use.
Container classes typically implement a fairly standardized minimal set of functionality. Most well-defined containers will include functions that:
- Create an empty container (via a constructor)
- Insert a new object into the container
- Remove an object from the container
- Report the number of objects currently in the container
- Empty the container of all objects
- Provide access to the stored objects
- Sort the elements (optional)
Types of containers
Container classes generally come in two different varieties. Value containers are compositions that store copies of the objects that they are holding (and thus are responsible for creating and destroying those copies). Reference containers are aggregations that store pointers or references to other objects (and thus are not responsible for creation or destruction of those objects).
Unlike in real life, where containers can hold whatever types of objects you put in them, in C++, containers typically only hold one type of data. For example, if you have an array of integers, it will only hold integers. Unlike some other languages, many C++ containers do not allow you to arbitrarily mix types. If you need containers to hold integers and doubles, you will generally have to write two separate containers to do this (or use templates, which is an advanced C++ feature). Despite the restrictions on their use, containers are immensely useful, and they make programming easier, safer, and faster.
An array container class
16.7 — std::initializer_list
#include <cassert> // for assert()
#include <iostream>
class IntArray
{
private:
int m_length{};
int* m_data{};
public:
IntArray() = default;
IntArray(int length)
: m_length{ length }
, m_data{ new int[length]{} }
{
}
~IntArray()
{
delete[] m_data;
// we don't need to set m_data to null or m_length to 0 here, since the object will be destroyed immediately after this function anyway
}
int& operator[](int index)
{
assert(index >= 0 && index < m_length);
return m_data[index];
}
int getLength() const { return m_length; }
};
int main()
{
// What happens if we try to use an initializer list with this container class?
IntArray array { 5, 4, 3, 2, 1 }; // this line doesn't compile
for (int count{ 0 }; count < 5; ++count)
std::cout << array[count] << ' ';
return 0;
}
This code won’t compile, because the IntArray class doesn’t have a constructor that knows what to do with an initializer list. As a result, we’re left initializing our array elements individually:
int main()
{
IntArray array(5);
array[0] = 5;
array[1] = 4;
array[2] = 3;
array[3] = 2;
array[4] = 1;
for (int count{ 0 }; count < 5; ++count)
std::cout << array[count] << ' ';
return 0;
}
That’s not so great.
Class initialization using std::initializer_list
When a compiler sees an initializer list, it automatically converts it into an object of type std::initializer_list. Therefore, if we create a constructor that takes a std::initializer_list parameter, we can create objects using the initializer list as an input.
std::initializer_list lives in the <initializer_list> header.
There are a few things to know about std::initializer_list. Much like std::array or std::vector, you have to tell std::initializer_list what type of data the list holds using angled brackets, unless you initialize the std::initializer_list right away. Therefore, you’ll almost never see a plain std::initializer_list. Instead, you’ll see something like std::initializer_list or std::initializer_liststd::string.
Second, std::initializer_list has a (misnamed) size() function which returns the number of elements in the list. This is useful when we need to know the length of the list passed in.
Let’s take a look at updating our IntArray class with a constructor that takes a std::initializer_list.
Class assignment using std::initializer_list
Note that if you implement a constructor that takes a std::initializer_list, you should ensure you do at least one of the following:
- Provide an overloaded list assignment operator
- Provide a proper deep-copying copy assignment operator
- Delete the copy assignment operator
Best practice
If you provide list construction, it’s a good idea to provide list assignment as well.
Summary
Implementing a constructor that takes a std::initializer_list parameter allows us to use list initialization with our custom classes. We can also use std::initializer_list to implement other functions that need to use an initializer list, such as an assignment operator.
16.x — Chapter 16 comprehensive quiz
Quiz time
Select one: If you can design a class using (composition, aggregation, association, or dependency), then you should.
composition














 2163
2163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









