







文件操作和IO
文件
概念
- 平时说的文件一般都是指存储在硬盘上面的普通文件(txt,mp4,rar)。
- 在计算机当中,文件可能是一个广泛的概念,不只是普通文件,还可以包括目录(目录文件)。
- 操作系统当中,还会使用文件来描述一些其他的硬件设备或软件资源。
- 网卡,操作系统中把这样的硬件设备也给抽象成一个文件,用来简化开发。显示器/键盘 都被操作系统视作文件。
普通文件是保存在硬盘上面的。
文件的分类
在程序有的角度,文件主要分为两种:
- 文本文件:里面存储的是字符。文本文件本质上也是存字节的。但是文本文件当中,相邻的字节在一起刚好可以构成一个个的字符。
- 二进制文件:存储的是字节。这种的话,字节和字符就没有关系了。
判断一个文件是不是二进制编码,用记事本打开就好。打开是乱码,就是二进制文件,不是乱码就是文本文件。就像打开一个图片:

用记事本打开的话,就是这个样子:
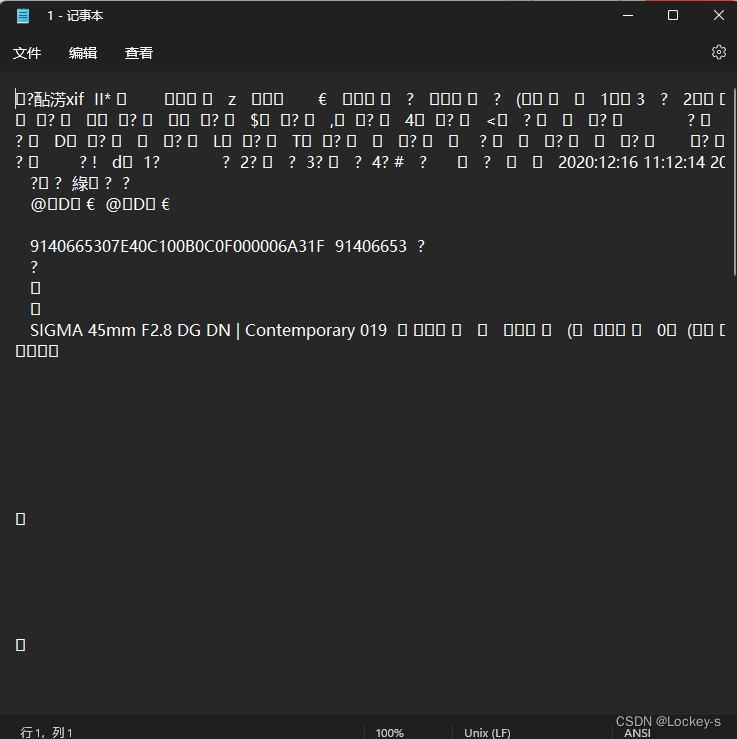
是乱码,就说明这个图片在存储的时候是以二进制存储的。
常见的文件类型
- .txt .c .java 都是文本文件。
- .doc .ppt .exe .zip .class 等等都属于二进制文件。
文件系统的目录结构
整体的文件系统,是树形结构。如图:
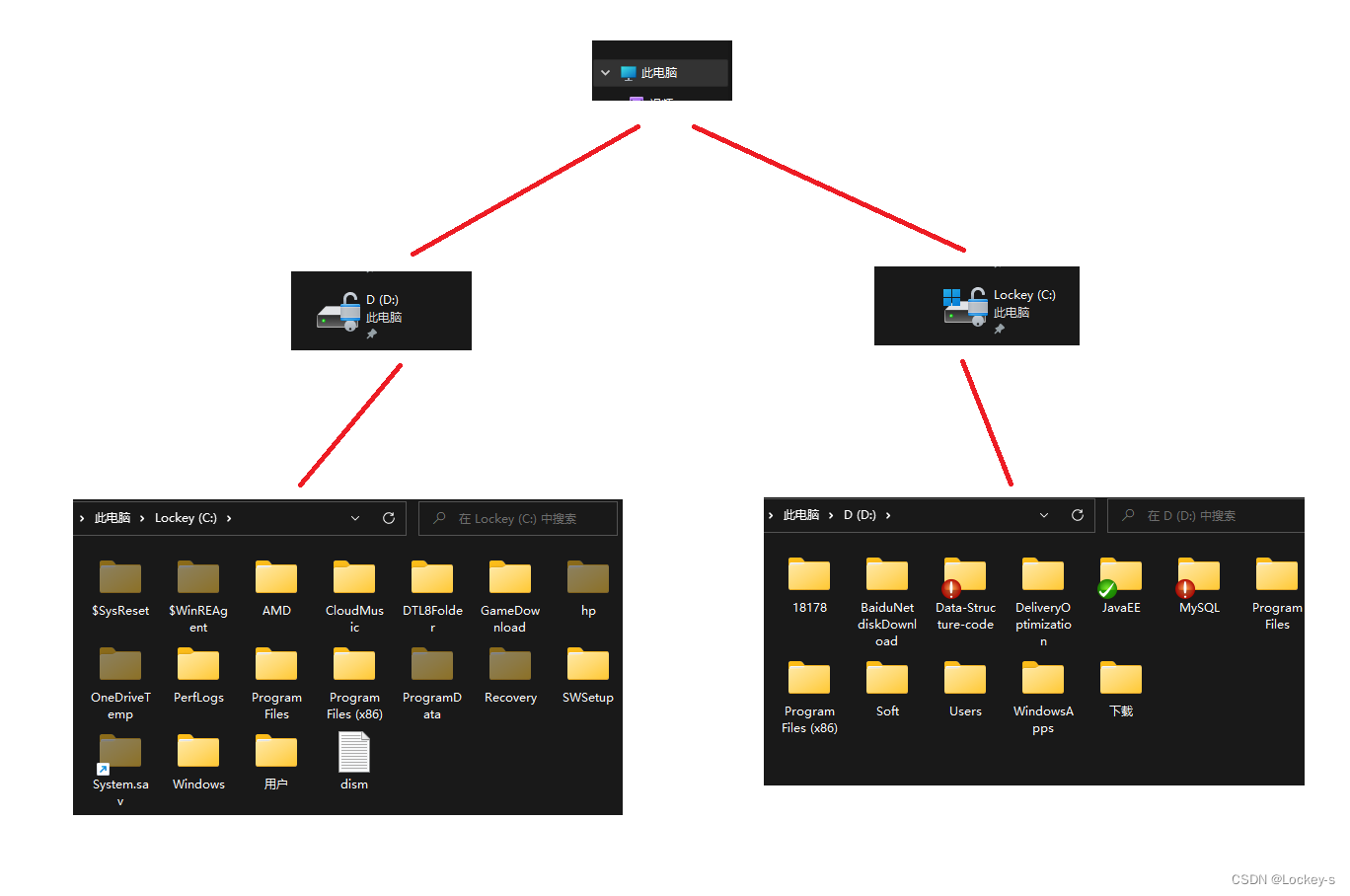
- 如果是一个普通文件,就是树的叶子节点。
- 如果是一个目录文件,目录中就可以包含字数,这个目录就是非叶子节点。
路径
在操作系统中,通过“路径”这样的概念来描述一个具体文件/目录的位置。
- 绝对路径:以盘符开头的。就像:D:\BaiduNetdiskDownload\壁纸\1月日历.png。
- 相对路径:以
.或..开头的,其中.表示当前路径..表示当前路径的父目录(上级路径)。 - 相对路径,必须要有一个基准目录,相对路径就hi是从基准路径出发,按照一个啥样的路径找到的对应文件。
- 即使是定位到同一个文件,如果基准目录不同,此时相对路径也不同。
例如:以 D:\D:\BaiduNetdiskDownload\壁纸 为基准目录,找到 2月日历.png 就是这样:./2月日历.png。图片位置如下:
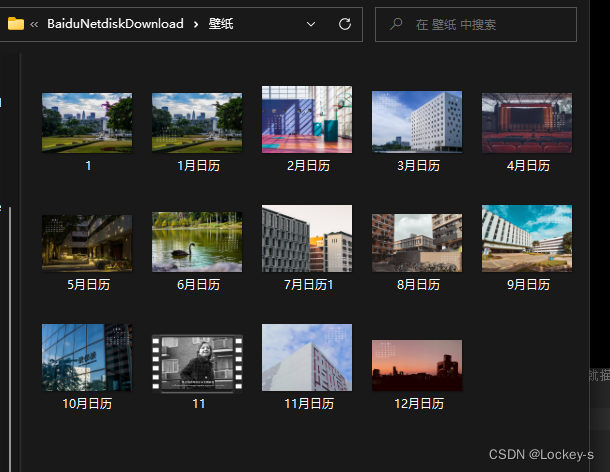
因为在同一个目录里,所以就是 ./2月日历.png 。
如果要找到上一级的其它文件,比如 教父1 ,就是这样 ../教父1.MP4 文件位置如下:
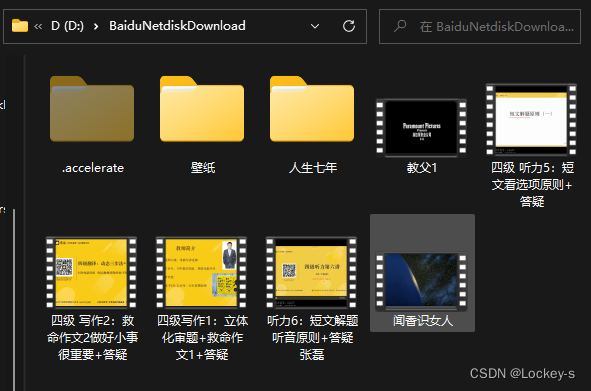
这里的 .. 就表示先回到上一级路劲,然后再从上一级路径中寻找 教父1.MP4 这个文件。
Java 中的文件操作
Java 当中的文件操作,主要有两类:
- 文件系统相关的操作:就是通过“文件资源管理器”能够完成一些功能。列出目录中有哪些文件,创建文件,创建目录,删除文件,重命名文件等等,Java 当中提供了一个 File 类,通过这个类来完成上述操作,File 类就描述了文件/目录。
- 文件内容相关的操作。
文件系统相关操作
- Java 当中提供了一个 File 类,通过这个类来完成上述操作,File 类就描述了文件/目录。
- 基于这个对象就可以实现上面的这些功能。File 的构造方法,能够传入一个路径,来指定一个文件,这个路径可以是绝对路径也可以是相对路径。
- 构造好对象,就可以通过方法来实现一些功能。
绝对路径
在使用绝对路径的时候,在 File 的构造方法中写出来就行了,建议用 反斜杠,如果是用斜杠的话,就得再用一个斜杠来转义。所以建议用 反斜杠。代码如下:
public static void main(String[] args) throws IOException {
//通过绝对路径来定位。
File f1 = new File("d/Test1.txt");
//获取到文件的父目录
System.out.println(f1.getParent());
//获取到文件名
System.out.println(f1.getName());
//获取到文件路径
System.out.println(f1.getPath());
//获取到绝对路径
System.out.println(f1.getAbsolutePath());
//获取到绝对路径
System.out.println(f1.getCanonicalPath());
}
运行结果如下:
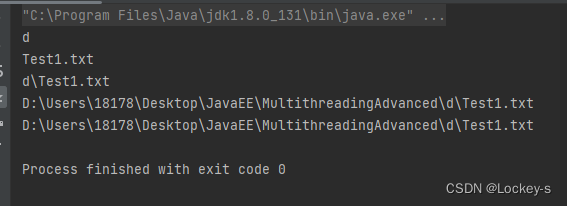
相对路径
- 说到相对路径,一样得先明确一个“基准路径”,代码中基准路径是啥:光看代码看不出来。
- 基准路径是由通过哪种方式来运行 Java 程序确定的。(不同的运行 Java 程序的方式,基准路径就不相同)。
- 如果是通过 命令行 的方式,此时执行命令所在的目录,就是基准路径(实际上不考虑这个情况)。
- 如果是通过 IDEA 的方式来运行程序,此时的基准路径就是当前项目所在的路径。此时的 基准路径 就是项目所在路径。
- 后续还会把一个 Java 代码打成 war 包,放到 Tomcat 上面去运行。这种情况下,基准路径 就是 Tomcat 的 bin 目录。
测试代码如下:
public static void main(String[] args) throws IOException {
File f2 = new File("./Test1.txt");
//获取到文件的父目录
System.out.println(f2.getParent());
//获取到文件名
System.out.println(f2.getName());
//获取到文件路径
System.out.println(f2.getPath());
//获取到绝对路径
System.out.println(f2.getAbsolutePath());
//获取到绝对路径
System.out.println(f2.getCanonicalPath());
}
运行结果如下:
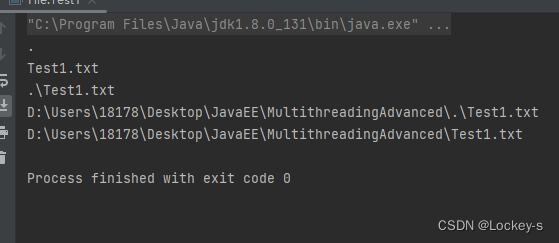
基准路径就是这里:
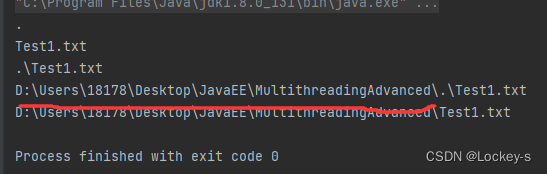
然后后面把相对路径拼接上去,. 可以省略,所以就有了下面的绝对路径。
文件是否存在
绝对路径
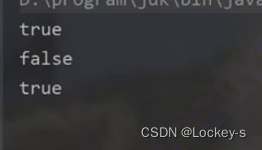
通过绝对路径来看,文件是否存在,是否是一个目录,是否是一个普通文件:
public static void main(String[] args) {
File f = new File("d:/Test1.txt");
//判断文件是否存在
System.out.println(f.exists());
//判断文件是否是一个目录
System.out.println(f.isDirectory());
//判断文件是否是一个普通文件
System.out.println(f.isFile());
}
因为我们提前在 d 盘中创建好了文件.
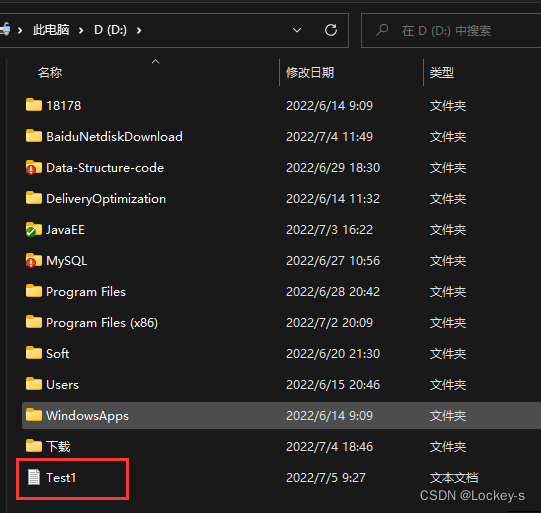
所以运行结果如下:
相对路径
通过相对路径来看,文件是否存在,是否是一个目录,是否是一个普通文件:
public static void main(String[] args) {
//换成相对路径就全是 false 了
File f = new File("./Test1.txt");
//判断文件是否存在
System.out.println(f.exists());
//判断文件是否是一个目录
System.out.println(f.isDirectory());
//判断文件是否是一个普通文件
System.out.println(f.isFile());
}
运行结果如下:

因为当前项目中,并没有创建这样的文件,所以都是 false。
文件的创建和删除
创建文件
通过 createNewFile 来创建文件,代码如下:
public static void main(String[] args) throws IOException {
//文件的创建和删除
File f = new File("./Test1.txt");
System.out.println(f.exists());
System.out.println("创建文件");
f.createNewFile();
System.out.println("创建文件结束");
System.out.println(f.exists());
}
运行结果如下:

然后在项目目录里就可以找到创建的文件了:

删除文件
通过 delete 方法直接删除,代码如下:
public static void main2(String[] args) {
File f = new File("./Test1.txt");
//删除文件,直接删除
f.delete();
}
运行之后,就发现文件目录当中的文件被删除掉了:

创建目录
创建一级目录
通过 mkdir 来创建目录。代码如下:
public static void main(String[] args) {
File f = new File("./aaa");
//创建目录
f.mkdir();
//说明已经创建好目录了。
System.out.println(f.isDirectory());
}
运行结果如下:

然后在项目目录当中就可以找到创建的目录了:

创建多级目录
通过 mkdirs 来创建多级目录。代码如下:
public static void main(String[] args) {
//创建多级目录
File f = new File("./aaa/bbb/ccc/ddd");
f.mkdirs();
System.out.println(f.isDirectory());
}
运行结果如下:

然后从项目目录当中就可以看到创建的多级目录了:

输出文件
通过 list 列出文件
代码如下:
public static void main1(String[] args) {
File f = new File("./");
//把 ./ 目录下所有的目录全部列出来
System.out.println(Arrays.toString(f.list()));
}
运行结果如下:

通过 File 对象来输出
代码如下:
public static void main(String[] args) {
File f = new File("./");
//通过 File 对象来输出。
System.out.println(Arrays.toString(f.listFiles()));
}
运行结果如下:

重命名文件
通过 renameTo 来重命名文件。代码如下:
public static void main(String[] args) {
File f = new File("./aaa");
File f2 = new File("./zzz");
//把 aaa 的名字改成 zzz
f.renameTo(f2);
}
修改后的结果如下:

文件内容的读写
针对文件内容的读写,Java 标准库提供了一组类。按照文件的内容,分成了两个系列:
- 字节流对象,针对二进制文件,是以字节为单位进行读写的。
a. 读:InputStream
b. 写:OutputStream - 字符流对象,针对文本文件,是以字符为单位进行读写的。
a. Reader
b. Writer
上面这些抽象类,既可以针对普通文件进行读写,也可以针对特殊文件(网卡,socket)进行读写。
这些类都是抽象类,实际使用的都是这些类的子类:
- FileInputStream
- FileOutputStream
- FileReader
- FileWriter
上面这一组都是针对普通文件进行读写的。
流对象
流只是一个形象的比喻。通过流对象来读取 100 个字节,可以一次读十个字节,十次读完。也可以一次读 20 字节,五次读完。
FileInputStream 读文件
一次读取一个字节
使用的时候,需要在构造方法中指定打开文件的路径。可以是绝对路径,也可以是相对路径。通过 try catch 来处理 FileNotFoundException 异常。代码如下:
public static void main(String[] args) {
//方法中需要指定打开文件的路径。
InputStream inputStream = null;
try {
//1、创建对象,同时也是在打开文件
inputStream = new FileInputStream("d:/Test1.txt");
//2、尝试一个一个字节的读,把文件都读完
//读文件的时候,也可很容易读取失败。硬盘很容易出现坏道,
while (true) {
int b = inputStream.read();
if (b == -1) {
//读到了文件末尾
break;
}
System.out.println(b);
}
//用完关闭文件,写在 finally 里面会更好,因为如果有异常的话,也可以继续关闭资源。
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果如下:

因为我们文件当中的内容是:abcdef。所以读出来就是:97 98 99 100 101 102

一次读取若干个字节
public static void main(String[] args) {
try (InputStream inputStream = new FileInputStream("d:/Test1.txt")){
//一次读若干个字节
while (true) {
byte[] buffer = new byte[1024];
//这个操作是把读出来的结果放到了 buffer 数组里了。相当于是使用 参数 来表示方法的返回值
// 这种做法称为”输出型参数“,这种操作在 Java 中少见,C++ 当中常见。
// 相当于把餐盘给阿姨,阿姨打好饭再给你
int len = inputStream.read(buffer);
if (len == -1) {
//读到了文件末尾,读取完毕
break;
}
for (int i = 0; i < len; i++) {
System.out.println(buffer[i]);
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
运行结果如下:

写文件
使用字节流 OutputStream 来写文件。代码如下:
public static void main(String[] args) {
try (OutputStream outputStream = new FileOutputStream("d:/Test1.txt")) {
//一次写入一个字节
outputStream.write(97);
outputStream.write(98);
outputStream.write(99);
} catch (IOException e) {
e.printStackTrace();
}
}
这里写的内容就是 a,b,c 因为是根据编码来写入的。文件中如下:

按照字符来读写
按照字符来读
代码如下:
public static void main(String[] args) {
try (Reader reader = new FileReader("d:/Test1.txt")) {
//按照字符来读
while (true) {
char[] buffer = new char[1024];
int len = reader.read(buffer);
if (len == -1) {
break;
}
String s = new String(buffer, 0, len);
System.out.println(s);
}
} catch (IOException e) {
e.printStackTrace();
}
}
文件当中的内容:

运行结果如下:

按照字符来写
通过 Writer 来实现:
public static void main(String[] args) {
try (Writer writer = new FileWriter("d:/Test1.txt")) {
writer.write("syz");
} catch (IOException e) {
e.printStackTrace();
}
}
运行结果如下:

实例练习
查找文件并删除
用户输入一个目录,再输入一个要删除的文件名。找到名称中包含指定字符的所有普通文件(不包含目录),并且询问用户是否要删除该文件。不过要注意的是:
- 文件系统上的目录是一种树形结构。
- n 叉树,同样通过递归扫描。
- 扫描到的时候,就询问是否删除。
- 然后根据用户选择进行删除。
代码如下:
public class Test {
public static void main(String[] args) {
//先输入要扫描的目录,以及要删除的文件名。
Scanner scanner = new Scanner(System.in);
System.out.println("请输入要扫描的路径");
String rootDirPath = scanner.next();
System.out.println("请输入要删除的文件名");
String teDeleteName = scanner.next();
File rootDir = new File(rootDirPath);
if (!rootDir.isDirectory()) {
System.out.println("输入的扫描路径有误");
return;
}
//输出所有的目录。输出的时候,遍d历方式也是递归
scanDir(rootDir,teDeleteName);
}
private static void scanDir(File rootDir, String teDeleteName) {
//1、先列出 rootDir 中有哪些内容。
File[] files = rootDir.listFiles();
if (files == null) {
//rootDir 是一个空目录
return;
}
//遍历当前列出的这些内容,如果是普通文件,就检测文件名是否是要删除的文件。
// 如果是目录,就递归进行遍历
for (File f : files) {
if (f.isFile()) {
if (f.getName().contains(teDeleteName)) {
deleteFile(f);
}
} else if (f.isDirectory()) {
scanDir(f,teDeleteName);
}
}
}
private static void deleteFile(File f) {
try {
System.out.println(f.getCanonicalPath() + "确定要删除吗(Y/N)");
Scanner scanner = new Scanner(System.in);
String choice = scanner.next();
if (choice.equals("Y") || choice.equals("y")) {
f.delete();
System.out.println("文件删除成功");
} else {
System.out.println("文件取消删除");
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
在文件中创建一个供测试的文件,这里使用 Test1 :

运行结果如下:

然后打开文件夹查看,发现 Test1 以经被删除了:

文件的复制
让用户指定两个文件:一个是原路径(被复制的文件),一个是目标路径(复制后的文件路径)。要注意的是:在复制的时候不需要检查目标文件是否存在,OutputStream 写文件的时候能够自动创建不存在的文件。代码如下:
public static void main(String[] args) {
//1、输入两个路径
Scanner scanner = new Scanner(System.in);
System.out.println("请输入要拷贝的源路径");
String src = scanner.next();
System.out.println("请输入要拷贝的目标路径");
String dest = scanner.next();
File srcFile = new File(src);
if (!srcFile.isFile()) {
System.out.println("输入的源路径不正确!");
return;
}
//2、读取源文件,拷贝到目标文件当中
try (InputStream inputStream = new FileInputStream(src)) {
try (OutputStream outputStream = new FileOutputStream(dest)) {
//把 inputStream 中的数据读出来,写入到 outputStream 中
byte[] buffer = new byte[1024];
while (true) {
int len = inputStream.read(buffer);
if (len == -1) {
//读取完毕
break;
}
//写入的时候,不能把整个 buffer 都写进去,毕竟 buffer 可能是只有一部分才是有效数据。
outputStream.write(buffer, 0, len);
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
运行结果如下:

我们打开目标文件夹,就可以看到拷贝好的文件了:

普通文件可以拷贝,二进制文件也可以拷贝。
文件内容的查找
- 先输入一个路径。
- 再输入一个要查找的文件内容的关键词。
- 递归的遍历文件,找到看哪个文件里的内容包含了关键词,就把对应的文件路径打印出来。
- 先遍历递归文件,然后每个文件都打开,然后看看有没有一样的关键字,用字符串查找即可。
代码如下:
public static void main(String[] args) {
//输入要扫描的文件路径
Scanner scanner = new Scanner(System.in);
System.out.println("请输入要扫描的路径");
String rootDirPath = scanner.next();
System.out.println("请输入要查询的关键词");
String word = scanner.next();
File rootDir = new File(rootDirPath);
if (!rootDir.isDirectory()) {
System.out.println("输入的路径违法");
return;
}
//递归并遍历,针对普通文件和目录分别处理
scanDir(rootDir, word);
}
private static void scanDir(File rootDir, String word) {
//1、先列出 rootDir 中有哪些内容。
File[] files = rootDir.listFiles();
if (files == null) {
//rootDir 是一个空目录
return;
}
for (File f : files) {
if (f.isFile()) {
//针对文件内容进行查找
if (containsWord(f, word)) {
try {
System.out.println(f.getCanonicalPath());
} catch (IOException e) {
e.printStackTrace();
}
}
} else if (f.isDirectory()) {
scanDir(f,word);
}
}
}
private static boolean containsWord(File f, String word) {
StringBuilder stringBuilder = new StringBuilder();
//把 f 中的内容都读出来,放到 StringBuilder 中
try (Reader reader = new FileReader(f)) {
char[] buffer = new char[1024];
while (true) {
int len = reader.read(buffer);
if (len == -1) {
break;
}
stringBuilder.append(buffer, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
//indexOf 返回的是子串的下标,如果 word 在 StringBuilder 中不存在,就返回 -1
return stringBuilder.indexOf(word) != -1;
}
代码执行结果如下:

.flush
就是刷新缓冲区。就像吃瓜子,一次抓很多瓜子。一次抓很多瓜子的手就是 “输入缓冲区”。如果吃完瓜子,把瓜子皮放在一个纸巾上面,这个纸巾就是输出缓冲区。
缓冲区存在的意义: 缓冲区存在的意义就是为了提高效率,在 计算机 当中很重要,就像 CPU 读取内存的速度,比读取硬盘的速度高很多。所以缓冲区就是一次性读一堆数据放在缓冲区,这样就增加了之后读取的效率。
写数据的时候,需要先把数据写在缓冲区,然后再统一写硬盘。如果缓冲区已经满了,就触发写硬盘操作。如果缓冲区还没满,也想写在硬盘里,就可以通过 flush 来手动刷新缓冲区。
















 881
881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











