







Decision Transformer 原理详解
1. 背景与动机
传统强化学习的挑战
- 长期依赖建模困难:传统RL算法(如DQN、PPO)在需要长程决策的任务中表现受限。
- 样本效率低下:在线交互学习需要大量环境交互,数据利用率低。
- 离线学习局限:离线RL方法(如CQL、BCQ)需复杂约束设计,难以直接利用历史轨迹。
Transformer的启示
- 序列建模优势:Transformer在NLP中展现了对长序列的建模能力,通过自注意力机制捕捉全局依赖。
- 监督学习范式:将RL问题转化为序列预测任务,利用历史轨迹数据直接生成动作。
2. 核心思想
将强化学习任务建模为条件序列生成问题,使用Transformer模型以自回归方式生成动作序列,条件为历史状态、动作及目标回报(或奖励)。
3. 建模方式
输入表示
将轨迹数据表示为三元组序列,每个时间步包含:
Token
t
=
(
s
t
,
a
t
,
R
t
)
\text{Token}_t = (s_t, a_t, R_t)
Tokent=(st,at,Rt)
- 状态( s t s_t st):当前环境观测。
- 动作( a t a_t at):当前执行的动作。
- 目标回报( R t R_t Rt):从当前时刻到轨迹结束的累计回报(或未来剩余回报)。
序列构建
- 轨迹分段:对一条轨迹 τ = ( s 0 , a 0 , r 0 , s 1 , . . . , s T ) \tau = (s_0, a_0, r_0, s_1, ..., s_T) τ=(s0,a0,r0,s1,...,sT),计算每个时刻的剩余回报 R t = ∑ k = t T γ k − t r k R_t = \sum_{k=t}^T \gamma^{k-t} r_k Rt=∑k=tTγk−trk。
- 输入序列:按时间步拼接为:
[ R 0 , s 0 , a 0 , R 1 , s 1 , a 1 , . . . , R T , s T ] [R_0, s_0, a_0, R_1, s_1, a_1, ..., R_T, s_T] [R0,s0,a0,R1,s1,a1,...,RT,sT]
模型结构
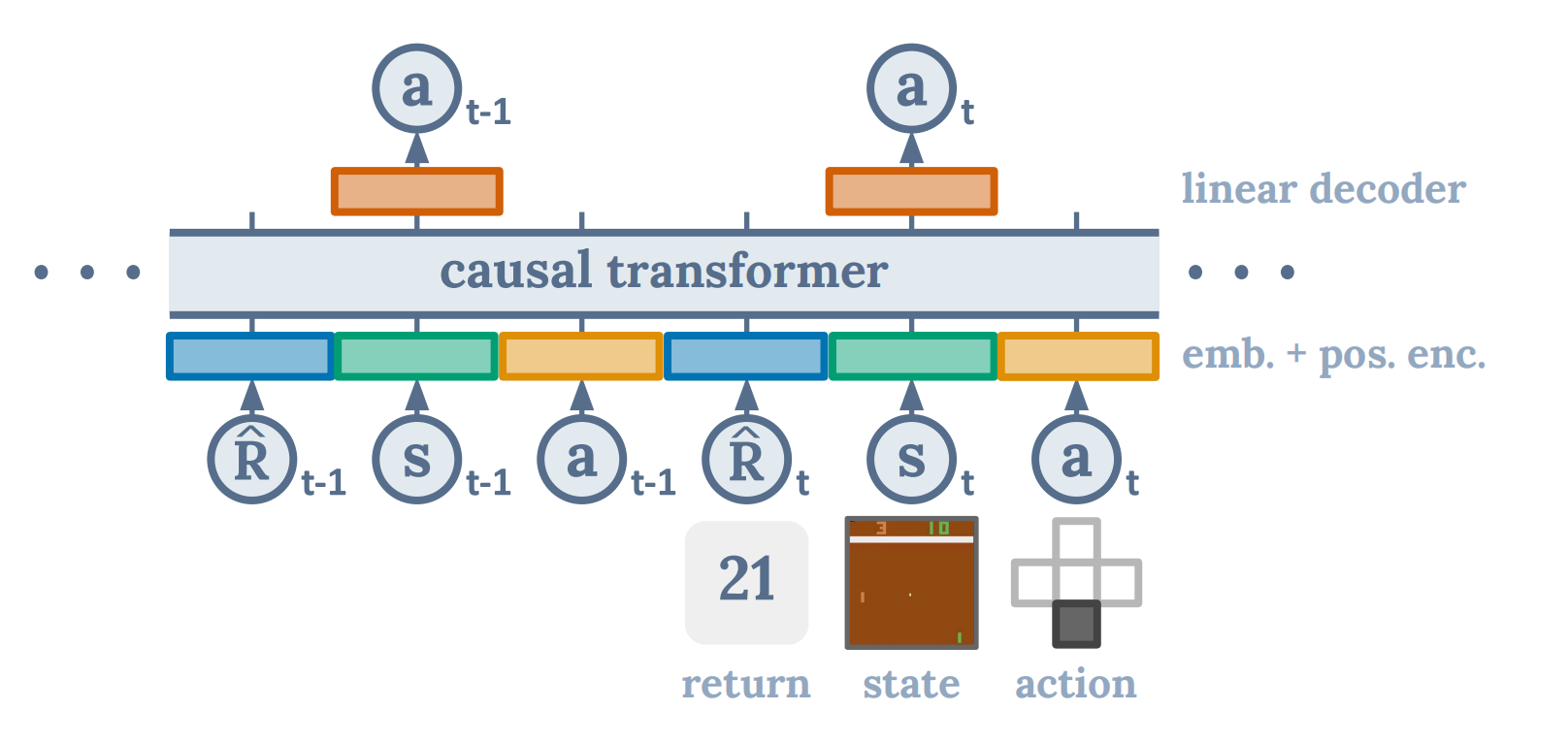
- Transformer Decoder:使用类似GPT的结构,以因果掩码确保预测仅依赖历史信息。
- Token嵌入:将 R t , s t , a t R_t, s_t, a_t Rt,st,at 分别嵌入为向量并拼接。
- 位置编码:添加时间步位置信息。
4. 损失函数
通过最大似然估计(MLE)优化动作预测的准确性:
L
=
−
∑
t
=
0
T
log
P
(
a
t
∣
R
≤
t
,
s
≤
t
,
a
<
t
)
\mathcal{L} = -\sum_{t=0}^T \log P(a_t | R_{\leq t}, s_{\leq t}, a_{<t})
L=−t=0∑TlogP(at∣R≤t,s≤t,a<t)
- 目标:给定历史状态、回报和动作,正确预测当前动作。
- 实现细节:仅对动作部分的预测计算损失,状态和回报作为条件输入。
5. 训练与推理
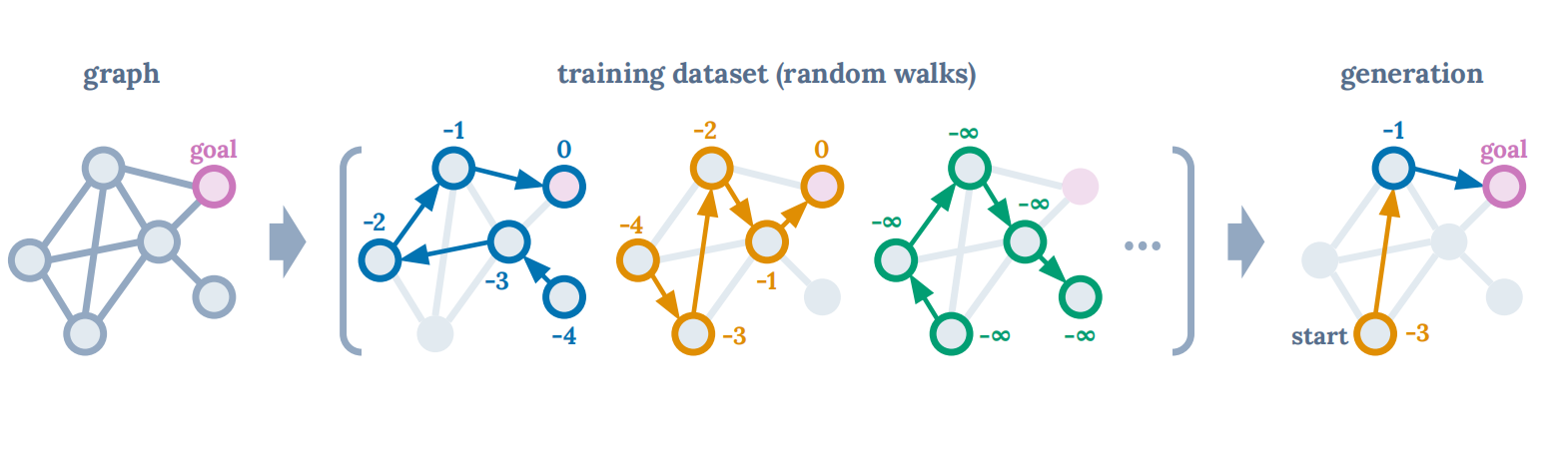
如上图所示:固定图结构下寻找最短路径的示例(左图)被建模为强化学习问题。训练数据集由随机游走轨迹及其每个节点的剩余回报组成(中图)。在给定起始状态且要求每个节点生成最大可能回报的条件下,Decision Transformer能够序列化生成最优路径。
训练阶段
- 输入:完整轨迹的 [ R t , s t , a t ] [R_t, s_t, a_t] [Rt,st,at] 序列。
- 掩码机制:使用因果掩码防止未来信息泄漏。
- 优化目标:最小化动作预测的交叉熵损失。
推理阶段
- 自回归生成:以初始状态
s
0
s_0
s0 和目标回报
R
0
R_0
R0 为起点,逐步生成动作:
- 输入当前序列 [ R 0 , s 0 , a 0 , R 1 , s 1 ] [R_0, s_0, a_0, R_1, s_1] [R0,s0,a0,R1,s1]。
- 预测下一动作 a 1 a_1 a1。
- 执行 a 1 a_1 a1,获取新状态 s 2 s_2 s2,更新剩余回报 R 1 = R 0 − r 0 R_1 = R_0 - r_0 R1=R0−r0。
- 重复直到终止。
import torch
import torch.nn as nn
from torch.nn import TransformerEncoder, TransformerEncoderLayer
class DecisionTransformer(nn.Module):
def __init__(self, state_dim, act_dim, hidden_dim=128, nhead=4, num_layers=3, max_timestep=1000):
"""
Decision Transformer 模型
参数:
state_dim (int): 状态维度
act_dim (int): 动作维度
hidden_dim (int): 隐藏层维度 (默认: 128)
nhead (int): Transformer头数 (默认: 4)
num_layers (int): Transformer层数 (默认: 3)
max_timestep (int): 最大时间步数 (用于位置编码,默认: 1000)
"""
super().__init__()
# 嵌入层定义
self.embed_t = nn.Embedding(max_timestep, hidden_dim) # 时间步位置嵌入
self.embed_R = nn.Linear(1, hidden_dim) # Return-to-go嵌入
self.embed_s = nn.Linear(state_dim, hidden_dim) # 状态嵌入
self.embed_a = nn.Linear(act_dim, hidden_dim) # 动作嵌入
# Transformer编码器
encoder_layers = TransformerEncoderLayer(hidden_dim, nhead, dim_feedforward=4*hidden_dim)
self.transformer = TransformerEncoder(encoder_layers, num_layers)
# 动作预测头
self.pred_a = nn.Linear(hidden_dim, act_dim)
# 初始化参数
self.hidden_dim = hidden_dim
self.act_dim = act_dim
def forward(self, R, s, a, timesteps):
"""
前向传播
参数:
R (Tensor): Return-to-go序列 [batch_size, seq_len, 1]
s (Tensor): 状态序列 [batch_size, seq_len, state_dim]
a (Tensor): 动作序列 [batch_size, seq_len, act_dim]
timesteps (Tensor): 时间步序列 [batch_size, seq_len]
返回:
Tensor: 预测动作序列 [batch_size, seq_len, act_dim]
"""
batch_size, seq_len = R.shape[:2]
# 1. 计算各元素的嵌入
pos_emb = self.embed_t(timesteps) # [batch_size, seq_len, hidden_dim]
# 计算各模态嵌入并添加位置信息
R_emb = self.embed_R(R) + pos_emb # [batch_size, seq_len, hidden_dim]
s_emb = self.embed_s(s) + pos_emb # [batch_size, seq_len, hidden_dim]
a_emb = self.embed_a(a) + pos_emb # [batch_size, seq_len, hidden_dim]
# 2. 按(R_1, s_1, a_1, ...)顺序交错堆叠
input_embeds = torch.stack([R_emb, s_emb, a_emb], dim=2) # [batch_size, seq_len, 3, hidden_dim]
input_embeds = input_embeds.view(batch_size, 3*seq_len, self.hidden_dim) # [batch_size, 3*seq_len, hidden_dim]
# 3. 添加序列维度并应用Transformer
src = input_embeds.permute(1, 0, 2) # [seq_len*3, batch_size, hidden_dim]
# 生成因果掩码 (仅允许关注历史信息)
mask = nn.Transformer.generate_square_subsequent_mask(src.size(0)).to(src.device)
# Transformer编码
hidden_states = self.transformer(src, mask) # [seq_len*3, batch_size, hidden_dim]
hidden_states = hidden_states.permute(1, 0, 2) # [batch_size, seq_len*3, hidden_dim]
# 4. 提取动作对应的隐藏状态
a_hidden = hidden_states[:, 2::3] # 每3个元素取第3个 (对应a的位置)
# 5. 预测动作
return self.pred_a(a_hidden) # [batch_size, seq_len, act_dim]
# 示例用法
if __name__ == "__main__":
# 超参数定义
state_dim = 10 # 状态维度
act_dim = 4 # 动作维度
batch_size = 32 # 批大小
seq_len = 20 # 序列长度
# 初始化模型
model = DecisionTransformer(state_dim, act_dim)
# 生成随机输入数据
R = torch.randn(batch_size, seq_len, 1) # Return-to-go
s = torch.randn(batch_size, seq_len, state_dim) # 状态
a = torch.randn(batch_size, seq_len, act_dim) # 动作
t = torch.randint(0, 1000, (batch_size, seq_len))# 时间步
# 前向传播
a_pred = model(R, s, a, t)
print("预测动作形状:", a_pred.shape) # 应为 [32, 20, 4]
# 训练步骤示例
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
loss_fn = nn.MSELoss()
# 计算损失
loss = loss_fn(a_pred, a)
print("初始损失:", loss.item())
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 评估循环示例 (需要与环境交互)
def evaluate(model, env, target_return, K=20):
model.eval()
state = env.reset()
states = [state]
returns = [target_return]
actions = []
timesteps = [0]
done = False
while not done:
# 准备输入序列 (保持最近K步)
R_in = torch.FloatTensor(returns[-K:]).unsqueeze(0) # [1, min(K,t), 1]
s_in = torch.FloatTensor(states[-K:]).unsqueeze(0) # [1, min(K,t), state_dim]
a_in = torch.FloatTensor(actions[-K:]).unsqueeze(0) if len(actions)>0 else torch.empty(1,0,act_dim)
t_in = torch.LongTensor(timesteps[-K:]).unsqueeze(0) # [1, min(K,t)]
# 预测动作
with torch.no_grad():
a_pred = model(R_in, s_in, a_in, t_in) # [1, seq_len, act_dim]
next_action = a_pred[0, -1] # 取最新预测动作
# 与环境交互
next_state, reward, done, _ = env.step(next_action.numpy())
# 更新序列
returns.append(returns[-1] - reward) # 更新剩余回报
states.append(next_state)
actions.append(next_action)
timesteps.append(len(returns))
return sum(returns) # 返回累计奖励
-
代码关键点
-
嵌入层结构:
时间步使用可学习的Embedding层
各模态(R/s/a)使用独立线性变换后加入位置信息
-
序列构建:
输入序列按(R_t, s_t, a_t)的顺序交错排列
使用3倍于原序列长度的维度来处理三种不同模态
-
注意力机制:
使用标准Transformer编码器
通过因果掩码强制实现自回归特性
-
训练优化:
使用简单的MSE损失进行动作预测
支持批量训练和序列截断
-
推理策略:
采用自回归生成方式
维护滑动窗口保持上下文长度
逐步更新returns-to-go
-
-
实际使用时需要注意
-
输入需要标准化处理
-
训练数据需要包含高质量的轨迹
-
目标returns-to-go的设置需要与任务奖励尺度匹配
-
上下文长度K的选择会影响性能
-
6. 与传统强化学习的区别
| 特性 | Decision Transformer | 传统RL算法 |
|---|---|---|
| 核心机制 | 序列建模,监督学习直接预测动作 | 基于Bellman方程,动态规划或策略梯度优化 |
| 问题建模 | 序列生成(监督学习) | 动态规划/策略优化(交互学习) |
| 数据利用 | 直接利用离线轨迹,无需交互 | 依赖在线交互或重要性采样 |
| 回报处理 | 目标回报作为条件输入 | 通过价值函数隐式建模 |
| 策略表示 | 显式生成动作序列 | 策略网络或值函数近似 |
| 长期依赖处理 | 自注意力机制捕捉全局依赖 | 依赖循环网络或折扣因子 |
| 探索机制 | 依赖数据分布,无显式探索 | ε-greedy、随机策略等显式探索 |
7. 优势与局限性
优势
- 离线学习友好:直接利用历史数据,无需环境交互。
- 长程决策能力:Transformer全局注意力机制有效捕捉长期依赖。
- 简化流程:将RL转化为监督学习,避免复杂值函数优化。
局限性
- 依赖高质量数据:数据分布偏差会导致策略次优。
- 目标回报敏感性:需合理设置目标回报,否则可能生成不合理动作。
- 实时性不足:自回归生成速度较慢,难以应对高实时性任务。
8. 实例说明
GridWorld导航任务
- 目标:智能体从起点到达目标点,最大化累计奖励。
- Decision Transformer输入:
- 状态 s t s_t st:当前位置坐标。
- 动作 a t a_t at:移动方向(上/下/左/右)。
- 目标回报 R t R_t Rt:剩余曼哈顿距离的负值。
- 输出:预测每一步动作,引导智能体走向目标。
9. Decision Transformer Return-to-go思想扩展
Decision Transformer(DT)中的Return-to-Go(RTG)与自然语言处理(NLP)中的Prompt存在一定的相似性,但它们的核心机制和设计目标有所不同。以下是详细解释:
9.1. RTG与Prompt的类比
相似性
- 引导生成过程:
- Prompt在NLP中用于指定生成任务的目标(例如“翻译以下句子:…”),直接引导模型生成符合预期的内容。
- RTG在DT中表示当前轨迹的剩余目标回报(即从当前时刻到轨迹结束的累积奖励),它动态地引导模型生成能够达成该回报的动作序列。
- 条件输入:
两者都作为模型的输入条件,直接影响模型的输出。RTG可以被视为一种“强化学习领域的Prompt”,因为它通过数值化的目标间接“提示”模型应如何行动。
关键区别
- 动态性:
RTG在轨迹的每一步会更新(逐渐减少),而传统Prompt通常是静态的文本前缀。 - 数值化目标:
RTG是数值型的条件信号,直接与强化学习的奖励机制挂钩,而Prompt通常是符号化的语义信息。
9.2. RTG如何影响轨迹生成
训练阶段
- 监督信号:
在训练时,RTG是基于真实轨迹的剩余回报计算的(例如专家轨迹的累积奖励)。模型通过历史状态、动作和RTG序列,学习预测下一步动作。 - 目标条件化:
RTG的作用类似于目标条件策略(Goal-Conditioned Policy),使模型能够根据不同的目标回报生成对应的动作。
推断阶段
- 目标设定:
在推断时,可以通过手动设置RTG的初始值(例如设置更高的目标回报)来尝试引导模型生成更优的轨迹。 - 诱导机制:
如果模型在训练时见过类似的高回报轨迹,理论上可以通过设置更高的RTG值,诱导模型生成更优动作。这与Prompt工程中通过优化提示词提升生成质量的思想一致。
9.3. 通过优秀RTG诱导更好轨迹的可行性
成功条件
- 训练数据的覆盖性:
如果模型在训练时见过高回报轨迹对应的RTG值,且能够泛化到更高的RTG值,则可能生成更优轨迹。 - 模型的泛化能力:
Transformer的注意力机制使其对序列模式具有强捕捉能力。如果RTG与动作的关联模式被正确学习,模型可能对未见过的RTG值产生合理响应。
潜在问题
- 不匹配风险:
若设置的RTG值远超出训练数据的分布(例如设置一个不切实际的高回报目标),模型可能生成不合理动作(类似NLP中的“幻觉”)。(扩展:HAC通过subgoal testing trasition策略(Hindsight数据增强技巧)对底层策略能力不匹配的subgoal进行惩罚。) - 局部最优陷阱:
DT基于历史数据模仿策略,可能无法像在线强化学习算法(如PPO)那样主动探索新策略,导致对RTG的响应受限。
9.4. 实验验证与改进方法
实验观察
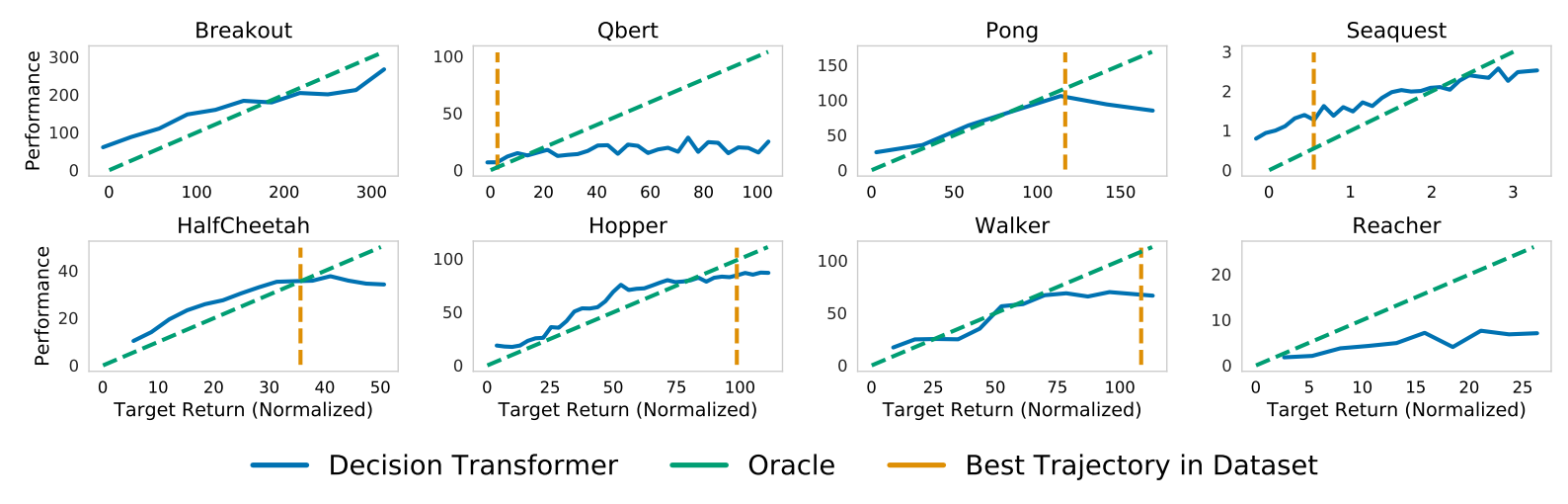
上图展示了在指定目标(期望)回报条件下,由决策变换器(Decision Transformer)累积的采样(评估)回报。使用比数据集中最大单episode回报更高的回报来提示Decision Transformer,结果表明该模型有时具备外推能力。
- 在原始DT论文中,通过替换RTG为专家轨迹的初始值,可以生成接近专家水平的轨迹。
- 若逐步提高RTG(例如从低到高逐步微调),模型可能逐步适应更高的目标(类似于课程学习)。
其中:
- 横轴代表目标回报,return-to-go,作为条件输入到transformer
- 纵轴代表按照当前return-to-go作为条件输入执行策略得到的实际回报
- 黄色竖线代表离线训练数据集中最大单episode回报作为return-to-go时的表现,代表 Behavior Cloning算法能力的天花板。
改进方向
- RTG规范化:
在训练时对RTG进行标准化或分桶处理,增强模型对不同目标范围的适应能力。 - 多目标训练:
引入多任务学习,使模型同时学习不同RTG目标下的策略。 - 在线微调:
结合在线强化学习,在推断时根据实际回报动态调整RTG,避免目标与能力不匹配。
9.5. 总结
- RTG的作用:
它既是目标条件信号,也是一种隐式的Prompt,通过数值化的剩余回报引导模型生成动作。 - 诱导策略的有效性:
合理设置RTG(如在训练数据分布范围内逐步提高)可以生成更优轨迹,但需注意模型的泛化边界。 - 与Prompt的区别:
RTG的动态更新和数值化特性使其更适用于强化学习的时序决策场景,而Prompt更偏向符号化语义引导。
通过以上机制,Decision Transformer在某种程度上实现了“通过目标设定(RTG)诱导策略生成”,这一思想与Prompt工程有异曲同工之妙,但需结合强化学习的特性进行针对性设计。
10. 总结
Decision Transformer通过将强化学习问题重新建模为条件序列生成任务,利用Transformer的全局建模能力和监督学习范式,显著简化了离线策略优化过程。其在长程决策和离线场景中表现突出,但对数据质量和回报设计高度敏感,是当前离线RL领域的重要突破方向。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











