







VQ-VAE 模型详解
论文链接:https://arxiv.org/abs/1711.00937
一、背景与动机
-
离散潜在变量的优势
传统变分自编码器(VAE)使用连续的潜在变量,可能因平滑插值导致细节丢失。而离散潜在变量(如VQ-VAE)能通过强制潜在空间中的每个点对应码本中的明确向量(多个向量,比如一个图片对应码本中多个向量的组合,也可以将多个向量看作图片的token表示,参考DALL-E模型),捕捉更清晰的模式。例如,图像中的边缘、纹理等局部特征可由特定码本向量表示,避免连续变量的模糊性。 -
后验坍缩(Posterior Collapse)
在VAE中,后验分布 q ( z ∣ x ) q(z|x) q(z∣x) 可能坍缩到先验 p ( z ) p(z) p(z),导致潜在变量 z z z 不携带输入信息。原因在于优化过程中,KL散度项迫使 q ( z ∣ x ) q(z|x) q(z∣x) 接近先验,而重构损失未能有效约束或者解码器太强。这使模型退化为普通自编码器,失去生成能力,即编码器随便将输入 x x x映射到一个点,解码器都能恢复,Latent Space没有规范化、不含 p ( z ∣ x ) p(z|x) p(z∣x)条件分布信息。 -
VQ-VAE如何缓解后验坍缩
VQ-VAE通过离散化潜在变量和固定码本强制后验分布 q ( z ∣ x ) q(z|x) q(z∣x) 为码本上的分类分布。编码器输出必须匹配码本中的向量,避免坍缩到连续先验。同时,码本与编码器的协同优化确保潜在变量保留输入信息。
二、模型结构
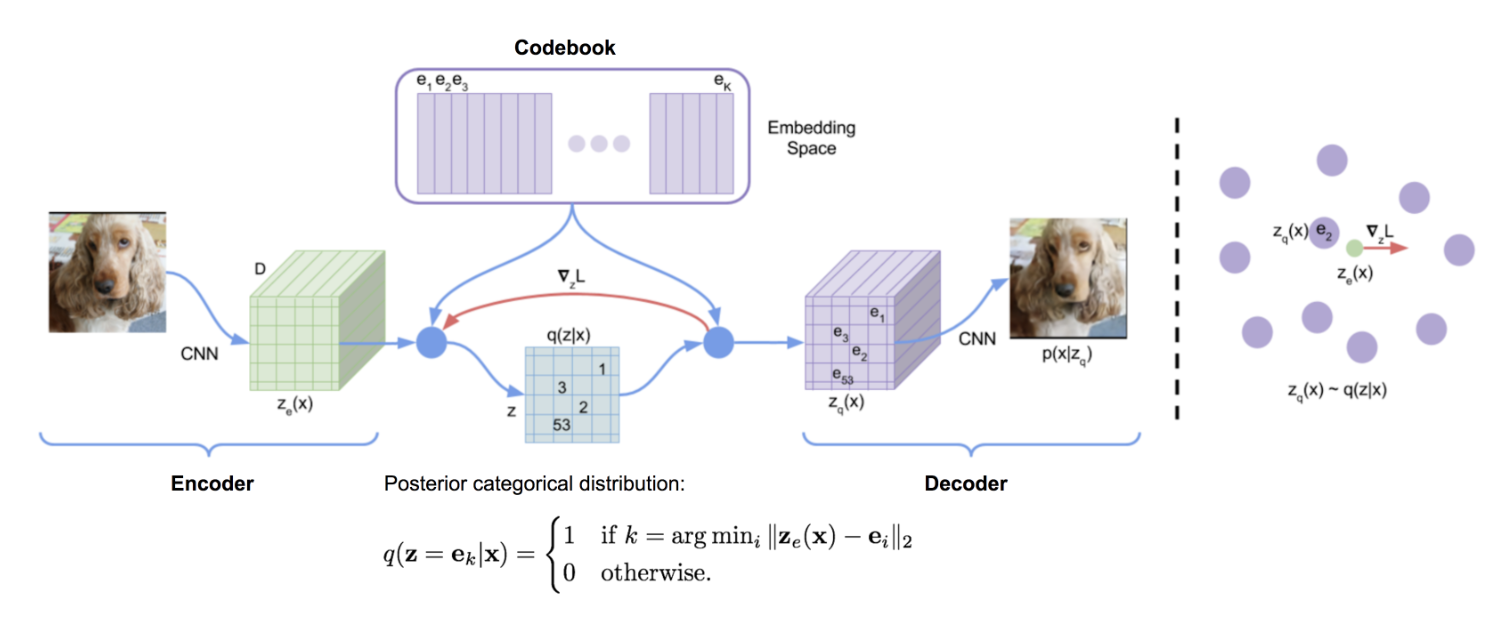
- 编码器(Encoder):将输入 x x x 映射为连续潜在向量 z e z_e ze。
- 向量量化层(VQ Layer):通过最近邻搜索将 z e z_e ze 替换为码本中的离散向量 z q = e k z_q = e_k zq=ek,其中 k = arg min i ∥ z e − e i ∥ 2 k = \arg\min_i \| z_e - e_i \|_2 k=argmini∥ze−ei∥2。
- 解码器(Decoder):根据 z q z_q zq 重构 x ^ \hat{x} x^。
- 映射方式:对于编码器输出的每个空间位置(或时间位置等)的连续向量,VQ Layer会独立地在码本中找到最近的离散向量进行替换。例如,在处理图像时,编码器输出的特征图可能为 H × W × D H \times W \times D H×W×D(高度、宽度、特征维度),其中每个空间位置 ( h , w ) (h, w) (h,w) 处的 D D D 维向量 z e ( h , w ) z_e^{(h,w)} ze(h,w) 会被替换为码本中的某个离散向量 e k e_k ek。这个过程对每个位置独立执行。最终输出的 z q z_q zq 是由多个离散向量组成的张量(如 H × W × D H \times W \times D H×W×D),每个位置对应一个从码本中选出的离散向量。因此,VQ层是将多个连续向量分别映射为对应的多个离散向量,而非单一离散向量。
- 码本(Codebook):包含 K K K 个可学习的嵌入向量 { e 1 , e 2 , . . . , e K } \{ e_1, e_2, ..., e_K \} {e1,e2,...,eK},维度与 z z z 相同。
三、损失函数
总损失由三部分组成:
L
=
L
recon
+
β
L
codebook
+
γ
L
commit
\mathcal{L} = \mathcal{L}_{\text{recon}} + \beta \mathcal{L}_{\text{codebook}} + \gamma \mathcal{L}_{\text{commit}}
L=Lrecon+βLcodebook+γLcommit
其中
β
\beta
β 为权重(通常设为1)。
-
重构损失(Reconstruction Loss)
最小化输入与重构的差异:
L recon = ∥ x − Decoder ( z q ) ∥ 2 2 \mathcal{L}_{\text{recon}} = \| x - \text{Decoder}(z_q) \|_2^2 Lrecon=∥x−Decoder(zq)∥22 -
码本损失(Codebook Loss)
更新码本向量以匹配编码器输出:
L codebook = ∥ sg ( z e ) − e k ∥ 2 2 \mathcal{L}_{\text{codebook}} = \| \text{sg}(z_e) - e_k \|_2^2 Lcodebook=∥sg(ze)−ek∥22sg(stop gradient)阻止梯度回传至编码器,仅优化码本。- 优化码本的离散向量接近编码器的输出
-
Commitment Loss
鼓励编码器输出 z e z_e ze 接近码本向量:
L commit = ∥ z e − sg ( e k ) ∥ 2 2 \mathcal{L}_{\text{commit}} = \| z_e - \text{sg}(e_k) \|_2^2 Lcommit=∥ze−sg(ek)∥22- 仅优化编码器,码本不更新。
- 优化编码器的向量接近码本的离散向量
四、梯度直通估计(Straight-Through Estimator)
量化操作( arg min \arg\min argmin)不可导,梯度无法直接回传。VQ-VAE采用直通估计:
- 前向传播:使用 z q = e k z_q = e_k zq=ek 作为解码器输入。
- 反向传播:将解码器对 z q z_q zq 的梯度直接复制给 z e z_e ze,跳过量化步骤。
数学上,梯度计算为:
∂
L
∂
z
e
=
∂
L
∂
z
q
\frac{\partial \mathcal{L}}{\partial z_e} = \frac{\partial \mathcal{L}}{\partial z_q}
∂ze∂L=∂zq∂L
这使得编码器可通过重构损失更新,尽管量化不可导。
直通估计技巧
z
e
=
e
n
c
o
d
e
r
(
x
)
z
q
=
z
e
+
s
g
[
e
k
−
z
e
]
,
e
k
=
a
r
g
m
i
n
e
∈
{
e
1
,
e
2
,
⋯
,
e
K
}
∣
∣
z
e
−
e
∣
∣
x
^
=
d
e
c
o
d
e
r
(
z
q
)
L
=
∣
∣
x
−
x
^
∣
∣
2
+
β
∣
∣
e
k
−
s
g
[
z
e
]
∣
∣
2
+
γ
∣
∣
z
e
−
s
g
[
e
k
]
∣
∣
2
\begin{aligned} z_e&=encoder(x)\\ z_q&=z_e+sg[e_k-z_e], \quad e_k=argmin_{e\in \{e_1, e_2, \cdots, e_K\}}||z_e-e|| \\ \hat{x}&=decoder(z_q) \\ \mathcal{L}&=||x-\hat{x}||^2+\beta||e_k-sg[z_e]||^2+\gamma||z_e-sg[e_k]||^2 \end{aligned}
zezqx^L=encoder(x)=ze+sg[ek−ze],ek=argmine∈{e1,e2,⋯,eK}∣∣ze−e∣∣=decoder(zq)=∣∣x−x^∣∣2+β∣∣ek−sg[ze]∣∣2+γ∣∣ze−sg[ek]∣∣2
利用sg stop_gradient算子和
e
k
e_k
ek与
z
e
z_e
ze的最邻近特性,在反向传播时用
z
e
z_e
ze替换
e
k
e_k
ek,也就是
z
q
=
z
e
+
s
g
[
e
k
−
z
e
]
z_q=z_e+sg[e_k−z_e]
zq=ze+sg[ek−ze]
- 前向计算,等价于
sg不存在,所以 z q = z e + e k − z e = e k z_q=z_e+e_k-z_e=e_k zq=ze+ek−ze=ek - 反向传播,
sg的梯度等于0,所以 ∇ z q = ∇ z e \nabla z_q=\nabla z_e ∇zq=∇ze,梯度绕过不可导算子直达编码器 - β ∣ ∣ e k − s g [ z e ] ∣ ∣ 2 \beta||e_k-sg[z_e]||^2 β∣∣ek−sg[ze]∣∣2来优化编码表,其意图类似K-Means,希望 e k e_k ek等于所有与它最邻近的 z e z_e ze的中心。
- γ ∣ ∣ z e − s g [ e k ] ∣ ∣ 2 \gamma||z_e-sg[e_k]||^2 γ∣∣ze−sg[ek]∣∣2,则希望编码器也主动配合来促进这种聚类特性
五、后验分布与先验
-
后验分布 q ( z ∣ x ) q(z|x) q(z∣x):确定性选择最近码本向量,等价于one-hot分布。
-
先验分布 p ( z ) p(z) p(z):通常假设为均匀分布 1 K \frac{1}{K} K1,或根据码本使用频率动态调整。
-
由于潜在变量离散化,KL散度项显式或隐式地被码本约束替代,避免后验坍缩。
-
VQ-VAE虽然被冠以VAE之名,但它实际上只是一个AE,并没有VAE的生成能力。它跟普通AE的区别是,它的编码结果是一个离散序列而非连续型向量,即它可以将连续型或离散型的数据编码为一个离散序列,并且允许解码器通过这个离散离散来重构原始输入,这就如同文本的Tokenizer——将输入转换为另一个离散序列,然后允许通过这个离散序列来恢复原始文本——所以它被视作任意模态的Tokenizer。总结:VQVAE是编码为一个离散序列,并不是编码为一个分布。 话说回来,通过码书多个离散变量的组合,解码器也能解码出很多有意思的内容,从这个角度说是生成模型也不为过。
六、训练流程
- 编码器生成 z e z_e ze。
- 量化层选择最近码本向量 z q = e k z_q = e_k zq=ek。
- 解码器重构 x ^ \hat{x} x^。
- 计算总损失并反向传播,更新编码器、解码器和码本。
七、关键点总结
- 离散化的优势:码本强制潜在变量表示明确特征,避免连续空间的模糊性。
- 后验坍缩缓解:码本的存在和损失设计强制编码器使用有效离散表示。
- 梯度直通:解决量化不可导问题,确保编码器可训练。
通过结合离散潜在变量、码本学习和直通梯度,VQ-VAE在图像、音频等领域实现了高质量的重建与生成。
八、代码
import torch
import torch.nn as nn
import torch.nn.functional as F
"""
向量量化层(VQ Layer)
"""
class VectorQuantizer(nn.Module):
def __init__(self, num_embeddings, embedding_dim, commitment_cost=0.25):
super().__init__()
self.embedding_dim = embedding_dim
self.num_embeddings = num_embeddings
self.commitment_cost = commitment_cost
# 初始化 Codebook
self.embeddings = nn.Embedding(self.num_embeddings, self.embedding_dim)
nn.init.uniform_(self.embeddings.weight, -1/self.num_embeddings, 1/self.num_embeddings)
def forward(self, z_e):
"""
输入: z_e (Tensor) - 编码器输出的连续潜在变量 [B, D, H, W]
输出: z_q (Tensor) - 量化后的离散潜在变量 [B, D, H, W]
loss (Tensor) - 量化总损失
perplexity (Tensor) - Codebook 使用困惑度
"""
# 调整维度: [B, D, H, W] → [B, H, W, D] → [BHW, D]
z_e_flat = z_e.permute(0, 2, 3, 1).contiguous()
z_e_flat = z_e_flat.view(-1, self.embedding_dim)
# 计算与 Codebook 的距离 [BHW, K]
distances = (
torch.sum(z_e_flat**2, dim=1, keepdim=True) +
torch.sum(self.embeddings.weight**2, dim=1) -
2 * torch.matmul(z_e_flat, self.embeddings.weight.t())
# 找到最近邻的 Codebook 索引
encoding_indices = torch.argmin(distances, dim=1)
quantized_flat = self.embeddings(encoding_indices)
# 计算损失
q_loss = F.mse_loss(quantized_flat.detach(), z_e_flat) # 码本Loss
e_loss = F.mse_loss(z_e_flat.detach(), quantized_flat) # Commitment Loss
loss = q_loss + self.commitment_cost * e_loss
# 直通梯度:z_q = z_e + (z_q - z_e).detach()
quantized_flat = z_e_flat + (quantized_flat - z_e_flat).detach()
# 恢复原始维度 [B, D, H, W]
quantized = quantized_flat.view(z_e.shape[0], z_e.shape[2], z_e.shape[3], self.embedding_dim)
quantized = quantized.permute(0, 3, 1, 2).contiguous()
# 计算困惑度(Codebook 使用均匀性),码书使用频率的熵
avg_probs = torch.histc(encoding_indices.float(), bins=self.num_embeddings, min=0, max=self.num_embeddings-1)
perplexity = torch.exp(-torch.sum(avg_probs * torch.log(avg_probs + 1e-10)))
return quantized, loss, perplexity
"""
编码器与解码器(以图像为例)
"""
class Encoder(nn.Module):
""" 输入图像 [B, C, H, W] → 输出连续潜在变量 [B, D, H', W'] """
def __init__(self, in_channels=3, latent_dim=64):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels, 32, 4, stride=2, padding=1), # 128x128 → 64x64
nn.ReLU(),
nn.Conv2d(32, 64, 4, stride=2, padding=1), # 64x64 → 32x32
nn.ReLU(),
nn.Conv2d(64, latent_dim, 1) # 调整通道数
)
def forward(self, x):
return self.model(x)
class Decoder(nn.Module):
""" 输入量化潜在变量 [B, D, H', W'] → 输出重构图像 [B, C, H, W] """
def __init__(self, out_channels=3, latent_dim=64):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(latent_dim, 64, 3, padding=1),
nn.ReLU(),
nn.Upsample(scale_factor=2), # 32x32 → 64x64
nn.Conv2d(64, 32, 3, padding=1),
nn.ReLU(),
nn.Upsample(scale_factor=2), # 64x64 → 128x128
nn.Conv2d(32, out_channels, 3, padding=1),
nn.Tanh() # 输出归一化到 [-1, 1]
)
def forward(self, z_q):
return self.model(z_q)
"""
完整 VQ-VAE 模型
"""
class VQVAE(nn.Module):
def __init__(self, in_channels=3, latent_dim=64, num_embeddings=512, commitment_cost=0.25):
super().__init__()
self.encoder = Encoder(in_channels, latent_dim)
self.vq_layer = VectorQuantizer(num_embeddings, latent_dim, commitment_cost)
self.decoder = Decoder(in_channels, latent_dim)
def forward(self, x):
# 编码 → 量化 → 解码
z_e = self.encoder(x)
z_q, vq_loss, perplexity = self.vq_layer(z_e)
x_recon = self.decoder(z_q)
# 总损失 = 重构损失 + VQ损失 + Commitment损失
recon_loss = F.mse_loss(x_recon, x)
total_loss = recon_loss + vq_loss
return x_recon, total_loss, perplexity
"""
测试代码
"""
if __name__ == "__main__":
# 参数设置
B, C, H, W = 4, 3, 128, 128 # 批大小, 通道, 高, 宽
latent_dim = 64
num_embeddings = 512
# 初始化模型
model = VQVAE(C, latent_dim, num_embeddings)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
# 模拟输入
x = torch.randn(B, C, H, W)
# 前向传播
x_recon, loss, perplexity = model(x)
# 输出检查
print(f"输入形状: {x.shape}") # [4, 3, 128, 128]
print(f"重构形状: {x_recon.shape}") # [4, 3, 128, 128]
print(f"总损失: {loss.item():.4f}") # 标量值
print(f"困惑度: {perplexity.item():.2f}") # 度量 Codebook 使用均匀性



















 2263
2263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











