






车牌检测和识别系统
目录
一、引言
车牌检测和识别系统是一种用于自动识别和记录车辆车牌号码的技术系统。它通过图像处理和模式识别技术,对车辆的车牌进行准确、快速的检测和识别,从而实现了自动化的车辆管理、交通监控和安全控制。
车牌检测和识别系统的背景和意义
背景: 随着车辆数量的增加和交通管理的需求,传统的人工识别车牌已经无法满足实际需求。人工识别存在效率低、识别准确率不高的问题,且需要大量的人力投入。因此,发展车牌检测和识别系统,提高车牌识别的准确性和效率,成为了一个迫切的需求。
意义: 实现自动化车辆管理和交通监控,提高管理效率和准确性。提高道路交通安全性,及时处理和惩罚交通违法行为,实现车辆的智能化管理和控制,提高运营效率,实现重要场所和区域的安全控制,识别非法车辆并报警,提供准确的车辆数据支持,为交通规划和城市管理提供依据。
车牌检测和识别的基本流程:
图像预处理:首先,对输入的图像进行预处理,以提高车牌检测的准确性。
车牌区域定位:利用目标检测算法(如YOLOv8)对预处理后的图像进行车牌区域的定位。
车牌区域提取:根据检测算法给出的边界框,从原始图像中提取出车牌区域的小图。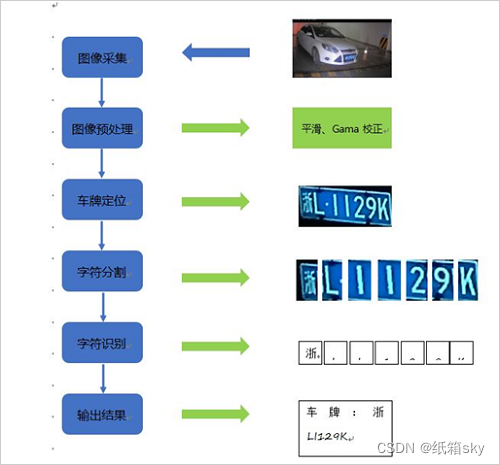
字符分割:对提取出的车牌小图进行字符分割。通常基于字符之间的间距、颜色和纹理等特征,将车牌图像划分为多个单独的字符区域。
字符特征提取:对每个字符区域提取特征。这些特征可以是基于像素级别的(如HOG特征、SIFT特征等),也可以是基于深度学习模型的(如卷积神经网络提取的特征)。
字符识别:利用分类器(如支持向量机SVM、神经网络或卷积神经网络CNN)对提取的特征进行分类,以识别出每个字符的具体内容。
后处理:对识别结果进行后处理,包括去除重复字符、修正识别错误等操作,以提高识别的准确性。
二、技术概述
车牌检测和识别所使用的主要技术
车牌检测和识别系统主要依赖两种技术:目标检测技术用于车牌定位,而字符识别技术则用于提取和识别车牌上的字符。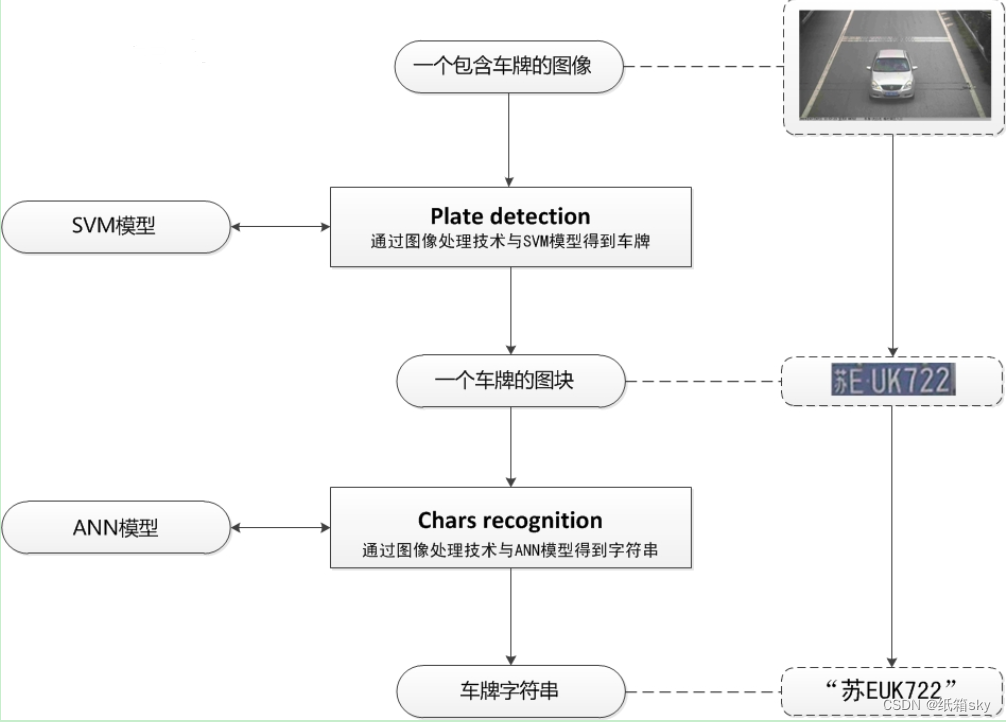
YOLOv8模型用于车牌检测
def load_model(weights, device): #加载yolov8 模型
model = attempt_load_weights(weights,device=device) # load FP32 model
return model load_model函数负责加载预训练的YOLOv8模型。通过这个函数,我们可以将训练好的模型加载到内存中,以便后续的车牌检测任务使用。加载模型后,通过调用模型的推理函数det_rec_plate,我们可以对输入的图像进行车牌检测,并获得检测结果。
img, r, left, top = pre_processing(img, opt, device) # 前处理
predict = detect_model(img)[0] # 调用推理函数进行车牌检测
outputs = post_processing(predict, 0.3, 0.5, r, left, top) # 后处理
在这里,detect_model(img)[0]就是调用推理函数的部分。detect_model是加载好的YOLOv8模型,img是经过预处理的图像。推理函数的返回值(在这里被索引为[0])包含了检测到的所有物体的边界框、置信度等信息。然后,这些信息被传递给post_processing函数进行后处理,如应用非极大值抑制(NMS)算法去除重叠的边界框,并还原边界框到原始图像的坐标系统中。
具体来说,det_rec_plate函数负责整个车牌检测和识别的流程,其中包括加载模型、预处理图像、调用推理函数进行车牌检测以及后续的车牌字符识别。
算法用于车牌字符识别
get_plate_result函数负责接收车牌区域的图像,并返回识别的车牌号码
def det_rec_plate(img, img_ori, detect_model, plate_rec_model):
# ... 其他代码 ...
for output in outputs:
# ... 获取车牌区域、标签等 ...
roi_img = img_ori[rect[1]:rect[3], rect[0]:rect[2]]
if int(label): # 判断是否是双层车牌
roi_img = get_split_merge(roi_img)
# 调用 get_plate_result 函数进行车牌字符识别
plate_number, rec_prob, plate_color, color_conf = get_plate_result(roi_img, device, plate_rec_model, is_color=True)
# ... 后续处理,如将结果添加到结果列表中 ...
# ... 返回结果列表 ...get_plate_result 函数是在 plate_recognition.plate_rec 模块中定义的。这个模块负责车牌字符识别的功能,包括调用 get_plate_result 函数 ,get_plate_result 函数被调用是在 det_rec_plate 函数内部,具体是在检测到一个车牌区域(通过 YOLOv8 模型)之后。这个循环中,对于每一个检测到的车牌区域(由 output 变量表示),都会提取出对应的图像区域 roi_img,并调用 get_plate_result 函数进行字符识别。识别的结果包括车牌号码 plate_number、识别概率 rec_prob、车牌颜色 plate_color 和颜色置信度 color_conf。
三、系统架构
系统的整体架构
车牌检测和识别系统由两个主要模块组成:车牌检测模块和字符识别模块。这两个模块协同工作,以实现从输入图像中自动检测和识别车牌号码的功能
各个模块的功能和相互作用
车牌检测模块:负责定位图像中的车牌区域
load_model:这个函数加载预训练的 YOLOv8 模型(detect_model),这是车牌检测的核心模型。
detect_model = load_model(opt.detect_model, device) # 初始化yolov8识别模型pre_processing:这个函数对输入图像进行预处理,使其适应 YOLOv8 模型的输入要求。
img, r, left, top = pre_processing(img, opt, device) # 前处理det_rec_plate:这个函数中调用了车牌检测模型(detect_model),并对模型的输出进行了后处理。特别地,detect_model(img)[0] 这行代码就是调用 YOLOv8 模型进行车牌检测 。
predict = detect_model(img)[0] # 检测车牌
outputs = post_processing(predict, 0.3, 0.5, r, left, top) # 后处理post_processing:这个函数对车牌检测模型的输出进行后处理,包括应用非极大值抑制(NMS)来过滤重叠的边界框,并将边界框坐标还原到原始图像上。
车牌检测模块的核心在于加载预训练的 YOLOv8 模型(load_model),对输入图像进行预处理(pre_processing),调用模型进行车牌检测(在 det_rec_plate 函数中通过 detect_model(img)[0] 实现),以及对检测结果进行后处理(post_processing)。
字符识别模块:负责识别车牌上的字符
get_plate_result:这个函数是字符识别模块的核心。它接收车牌区域的图像作为输入,并返回识别的车牌号码、识别概率、车牌颜色以及颜色置信度。这个函数通常在 det_rec_plate 函数中被调用,用于对每个检测到的车牌区域进行字符识别。
plate_number, rec_prob, plate_color, color_conf = get_plate_result(roi_img, device, plate_rec_model, is_color=True)init_model:虽然这个函数本身不是字符识别的核心代码,但它负责初始化字符识别模型(plate_rec_model)。这个模型在 get_plate_result 函数中被用来进行字符识别。
plate_rec_model = init_model(device, opt.rec_model, is_color=True) # 初始化识别模型det_rec_plate:这个函数调用了 get_plate_result 函数来进行字符识别。它首先检测车牌区域,然后对每个区域应用字符识别算法。
for output in outputs:
# ... 省略其他代码 ...
roi_img = img_ori[rect[1]:rect[3], rect[0]:rect[2]] # 提取车牌区域图像
plate_number, rec_prob, plate_color, color_conf = get_plate_result(roi_img, device, plate_rec_model, is_color=True) # 字符识别
# ... 省略其他代码 ...字符识别模块的核心在于 get_plate_result 函数,它接收车牌区域图像并返回识别结果。此外,init_model 函数用于初始化字符识别模型,而 det_rec_plate 函数则负责调用字符识别算法对每个检测到的车牌区域进行识别。
四、车牌检测模块
YOLOv8模型
模型原理和优势
原理:
网络结构:采用高效的卷积神经网络作为主干,提取图像特征。
Anchor机制:可能采用Anchor-Free或改进的Anchor机制,简化边界框预测。
任务解耦:分类和定位任务分别处理,提高准确性。
优势:
速度与效率:在保证准确性的同时,实现快速处理。
先进骨干网络:优秀的特征提取能力,适应复杂场景。
实时应用与边缘设备:适合在实时应用或资源受限设备上运行。
可扩展性:良好的开源项目,易于定制和优化。
训练数据和模型训练过程
训练数据是车牌检测和识别系统的重要组成部分。
为了训练出高性能的模型,需要收集大量包含车牌的图像数据。我们通过爬取部分车牌网站图片以及通过飞桨平台下载车牌号数据集_数据集-飞桨AI Studio星河社区 (baidu.com),收集到原始图像数据后,还需要进行一系列的数据预处理工作。首先,需要对图像进行标注,标记出车牌的位置和车牌上的字符,标注完成后,还需要将标注信息转换为模型训练所需的格式,如YOLOv8所需的txt格式或VOC格式等。
模型训练是车牌检测和识别系统的核心环节。
我们选择了YOLOv8作为车牌检测模型,并根据实际情况调整了模型的超参数,如学习率、批大小、迭代次数等。然后,使用深度学习框架和训练脚本开始训练模型。训练过程中,模型会不断地学习输入图像中的特征,并优化模型参数以最小化预测误差。训练过程中可以通过可视化工具来监控训练进度和模型性能。当模型训练完成后,需要进行模型评估和测试。这通常包括在验证集或测试集上评估模型的准确率、召回率等指标,以确保模型在实际应用中具有良好的性能。
车牌检测流程
图像预处理
图像预处理的部分主要在pre_processing函数中实现。这个函数负责将输入图像进行一系列的处理,以适应车牌检测和识别模型的输入要求。
def pre_processing(img, opt, device):
img, r, left, top = letter_box(img, (opt.img_size, opt.img_size))
img = img[:, :, ::-1].transpose((2, 0, 1)).copy() # bgr2rgb hwc2chw
img = torch.from_numpy(img).to(device)
img = img.float()
img = img / 255.0
img = img.unsqueeze(0) # 增加批次维度
return img, r, left, toppre_processing函数执行了以下预处理步骤:使用letter_box函数调整图像的大小,并在必要时填充边缘,以保持图像的宽高比并匹配模型的输入尺寸。将图像从BGR颜色空间转换为RGB颜色空间,并将图像数据的维度从HWC(高度、宽度、通道)转换为CHW(通道、高度、宽度),以适应深度学习模型的输入要求。将图像数据从NumPy数组转换为PyTorch张量,并转换为浮点数类型。然后,将图像数据的像素值归一化到[0, 1]范围,以便模型能够更好地处理。为图像数据增加一个批次维度,使其能够作为模型的输入。
模型推理获取检测结果
模型推理获取检测结果的代码主要位于det_rec_plate函数中,特别是通过调用YOLOv8模型的部分。detect_model(img)[0]是模型推理的关键步骤,它接收预处理后的图像数据img作为输入,并返回模型的检测结果。这些结果随后被传递给post_processing函数进行后处理,以便提取出最终的车牌边界框和其他相关信息。
def det_rec_plate(img, img_ori, detect_model, plate_rec_model):
# ... 省略其他代码 ...
img, r, left, top = pre_processing(img, opt, device) # 前处理
predict = detect_model(img)[0] # 模型推理获取检测结果
outputs = post_processing(predict, 0.3, 0.5, r, left, top) # 后处理
# ... 省略后续字符识别等代码 ...代码通过以下步骤实现:
图像预处理:首先,对输入图像进行预处理,调用pre_processing函数准备图像数据以符合模型的输入要求。
模型推理:使用预处理后的图像数据作为输入,调用加载好的YOLOv8模型(detect_model)进行推理。这通常通过一行代码实现,如predict = detect_model(img)[0]。
后处理:对模型推理输出的结果进行后处理。这包括应用非极大值抑制(NMS)来过滤重叠的边界框,并将边界框坐标还原到原始图像上。后处理操作在post_processing函数中实现。
检测结果的后处理
检测结果的后处理代码部分主要集中在post_processing函数中。
def post_processing(prediction, conf, iou_thresh, r, left, top):
# 过滤低置信度边界框
prediction = prediction.permute(0, 2, 1).squeeze(0)
xc = prediction[:, 4:6].amax(1) > conf
x = prediction[xc]
if not len(x):
return []
# 提取边界框并转换为xyxy格式
boxes = x[:, :4]
boxes = xywh2xyxy(boxes)
# 找出得分和所属类别(对于车牌检测,可能只有一个类别)
score, index = torch.max(x[:, 4:6], dim=-1, keepdim=True)
x = torch.cat((boxes, score, x[:, 6:14], index), dim=1)
# 应用非极大值抑制(NMS)
keep = my_nums(x, iou_thresh)
x = x[keep]
# 坐标还原到原图上
x = restore_box(x, r, left, top)
return x在这个函数中:
prediction.permute(0, 2, 1).squeeze(0) 用于调整预测结果的维度,以便后续处理。
xc = prediction[:, 4:6].amax(1) > conf 用于过滤掉置信度低于阈值的边界框。
xywh2xyxy(boxes) 将中心点+宽高的边界框格式转换为左上角+右下角的格式。
torch.max(x[:, 4:6], dim=-1, keepdim=True) 用于找出每个边界框的得分和所属类别
my_nums(x, iou_thresh) 执行非极大值抑制,消除重叠的边界框。
restore_box(x, r, left, top) 将边界框坐标从模型输出空间还原到原始图像空间
五、车牌字符识别模块
车牌图像分割
车牌区域的裁剪是在det_rec_plate函数中通过以下代码完成。
for output in outputs:
# ... 其他代码 ...
rect = output[:4] # 提取边界框坐标
rect = [int(x) for x in rect] # 将坐标转换为整数
roi_img = img_ori[rect[1]:rect[3], rect[0]:rect[2]] # 根据边界框坐标从原始图像中裁剪车牌区域
# ... 后续的车牌字符识别代码 ...这里,output[:4]从模型的输出中提取出边界框的坐标(通常是左上角和右下角的坐标),然后将这些坐标转换为整数类型。接着,使用这些坐标从原始图像img_ori中裁剪出车牌区域的图像roi_img。这个裁剪操作就实现了车牌图像的分割。
字符特征提取
字符特征提取是在调用get_plate_result函数时隐式发生的。这个函数接收车牌区域的图像作为输入,并调用已经训练好的车牌字符识别模型(plate_rec_model)进行推理。模型会对输入的车牌图像进行前向传播计算,通过一系列的卷积层、池化层、全连接层等网络结构来提取字符特征,并最终输出字符识别的结果
字符识别算法应用
字符识别算法应用的代码部分主要体现在调用get_plate_result函数时。这个函数负责接收车牌区域的图像(roi_img),并应用字符识别算法来识别车牌上的字符。get_plate_result函数内部会使用已经加载和初始化好的字符识别模型(plate_rec_model)对车牌区域图像进行推理。推理过程中,模型会应用其学习到的字符特征提取和分类能力,对输入的车牌图像进行处理,并输出识别的字符序列。
for output in outputs:
# ... 其他代码 ...
roi_img = img_ori[rect[1]:rect[3], rect[0]:rect[2]] # 提取车牌区域图像
plate_number, rec_prob, plate_color, color_conf = get_plate_result(roi_img, device, plate_rec_model, is_color=True)
# ... 后续处理代码 ...这里,get_plate_result函数接收车牌区域图像roi_img作为输入,以及设备信息device、字符识别模型plate_rec_model和其他参数。函数内部会使用这些参数调用字符识别模型进行推理,并返回识别的车牌号码plate_number、识别概率rec_prob、车牌颜色plate_color和颜色置信度color_conf
六、前端GUI
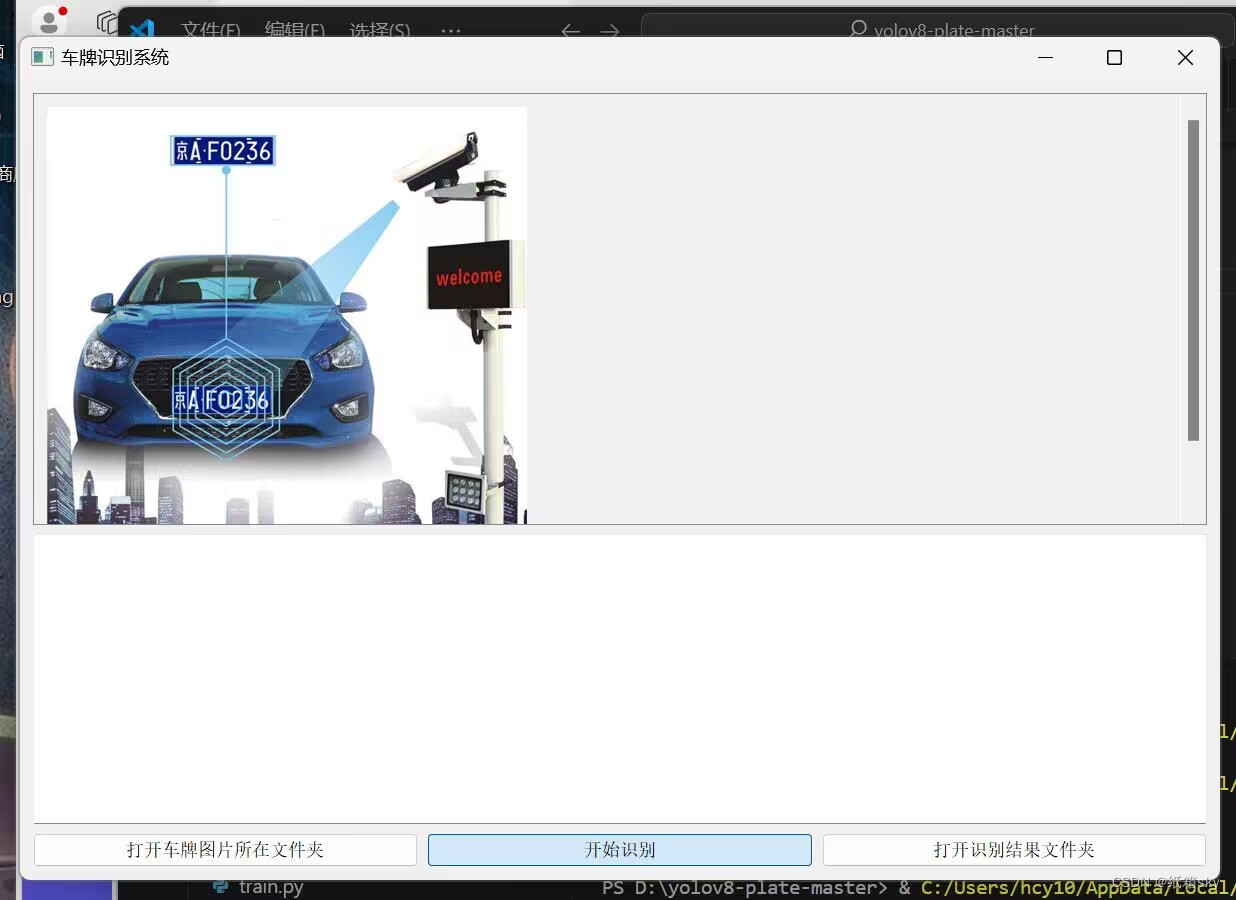
这是基于 PyQt5 的车牌识别系统的图形用户界面 (GUI) 程序。该系统提供了用户加载车牌图片、运行车牌识别程序并查看识别结果的功能。通过直观的界面和简单的操作,用户可以方便地进行车牌识别操作
系统主要由以下几个部分组成:
图形用户界面:使用 PyQt5 库创建,提供了用户与系统进行交互的直观界面。
图片加载与显示:用户可以通过界面加载车牌图片,并在界面上预览图片。
车牌识别程序:系统调用一个外部的车牌识别程序(如 '1.exe'),该程序负责处理图片并输出识别结果。
结果展示:识别结果以文本形式展示在界面上,用户可以查看和保存结果。
GUI交互界面完整代码
import os import sys import subprocess import platform import shutil from PyQt5.QtWidgets import QApplication, QMainWindow, QVBoxLayout, QWidget, QTextEdit, QPushButton, QTableWidget, QTableWidgetItem, QHBoxLayout, QLabel, QScrollArea, QMessageBox, QLabel, QGraphicsScene, QGraphicsView, QMessageBox from PyQt5.QtGui import QPixmap from PyQt5.QtCore import Qt class PlateRecognitionWindow(QMainWindow): def __init__(self): super().__init__() self.setWindowTitle("车牌识别系统") self.initUI() def initUI(self): central_widget = QWidget(self) self.setCentralWidget(central_widget) layout = QVBoxLayout() # 图片预览区 self.preview_area = QScrollArea() self.preview_area.setWidgetResizable(True) self.loadAndDisplayImage('1.jpg') # 加载1.jpg图片 layout.addWidget(self.preview_area) # 车牌识别结果文本展示区 self.text_edit = QTextEdit() self.text_edit.setReadOnly(True) layout.addWidget(self.text_edit) # 按钮区 button_layout = QHBoxLayout() self.open_image_folder_button = QPushButton("打开车牌图片所在文件夹") self.open_image_folder_button.clicked.connect(lambda: self.openSpecificFolder('imgs')) button_layout.addWidget(self.open_image_folder_button) self.run_button = QPushButton("开始识别") self.run_button.clicked.connect(self.runExternalProgram) button_layout.addWidget(self.run_button) self.open_result_folder_button = QPushButton("打开识别结果文件夹") self.open_result_folder_button.clicked.connect(lambda: self.openSpecificFolder('result')) button_layout.addWidget(self.open_result_folder_button) layout.addLayout(button_layout) central_widget.setLayout(layout) self.setGeometry(100, 100, 1200, 800) def loadAndDisplayImage(self, image_path): """加载并显示图片""" if os.path.exists(image_path) and os.path.isfile(image_path): pixmap = QPixmap(image_path) if not pixmap.isNull(): image_label = QLabel() image_label.setPixmap(pixmap.scaled( self.preview_area.width(), self.preview_area.height(), Qt.KeepAspectRatio, Qt.SmoothTransformation )) scroll_contents = QWidget() scroll_layout = QVBoxLayout(scroll_contents) scroll_layout.addWidget(image_label) scroll_contents.setLayout(scroll_layout) self.preview_area.setWidget(scroll_contents) else: self.text_edit.append("图片加载失败,请检查图片是否损坏。") else: self.text_edit.append(f"图片文件{image_path}不存在。") def openSpecificFolder(self, folder_name): folder_path = os.path.join(os.getcwd(), folder_name) if os.path.exists(folder_path) and os.path.isdir(folder_path): print(f"打开了{folder_name.capitalize()}文件夹: {folder_path}") if platform.system() == "Windows": os.startfile(folder_path) elif platform.system() == "Darwin": subprocess.Popen(["open", folder_path]) elif platform.system() == "Linux": subprocess.Popen(["xdg-open", folder_path]) else: print("不支持的操作系统类型。") else: print(f"{folder_name.capitalize()}文件夹不存在于当前工作目录。") def runExternalProgram(self): exe_path = os.path.join(os.getcwd(), "1.exe") if not os.path.isfile(exe_path): self.text_edit.append("无法找到外部程序1.exe。") return command = [exe_path] try: process = subprocess.Popen(command, stdout=subprocess.PIPE, stderr=subprocess.STDOUT, universal_newlines=True, encoding='GBK', errors='replace') self.text_edit.append("开始执行外部程序...") for line in iter(process.stdout.readline, ""): self.text_edit.append(line.rstrip()) QApplication.processEvents() process.stdout.close() process.wait() self.text_edit.append("外部程序执行完毕。") self.readAndDisplayResultText() # 在这里调用方法来读取并显示车牌识别信息.txt except Exception as e: self.text_edit.append(f"执行过程中遇到错误:{str(e)}") def readAndDisplayResultText(self): txt_path = os.path.join(os.getcwd(), "1.txt") if os.path.exists(txt_path) and os.path.isfile(txt_path): with open(txt_path, 'r', encoding='utf-8', errors='replace') as file: content = file.read() self.text_edit.setPlainText(content) # 询问用户是否删除1.txt文件 reply = QMessageBox.question(self, '删除文件', '是否删除车牌识别信息.txt文件?', QMessageBox.Yes | QMessageBox.No, QMessageBox.No) if reply == QMessageBox.Yes: os.remove(txt_path) self.text_edit.append("车牌识别信息.txt文件已被删除。") else: self.text_edit.append("保留了车牌识别信息.txt文件。") else: self.text_edit.append("无法找到结果文件车牌识别信息.txt。") if __name__ == "__main__": app = QApplication(sys.argv) window = PlateRecognitionWindow() window.show() sys.exit(app.exec_())
七、实验结果与分析
车牌检测和识别
处理后的图像识别出来的车牌号码
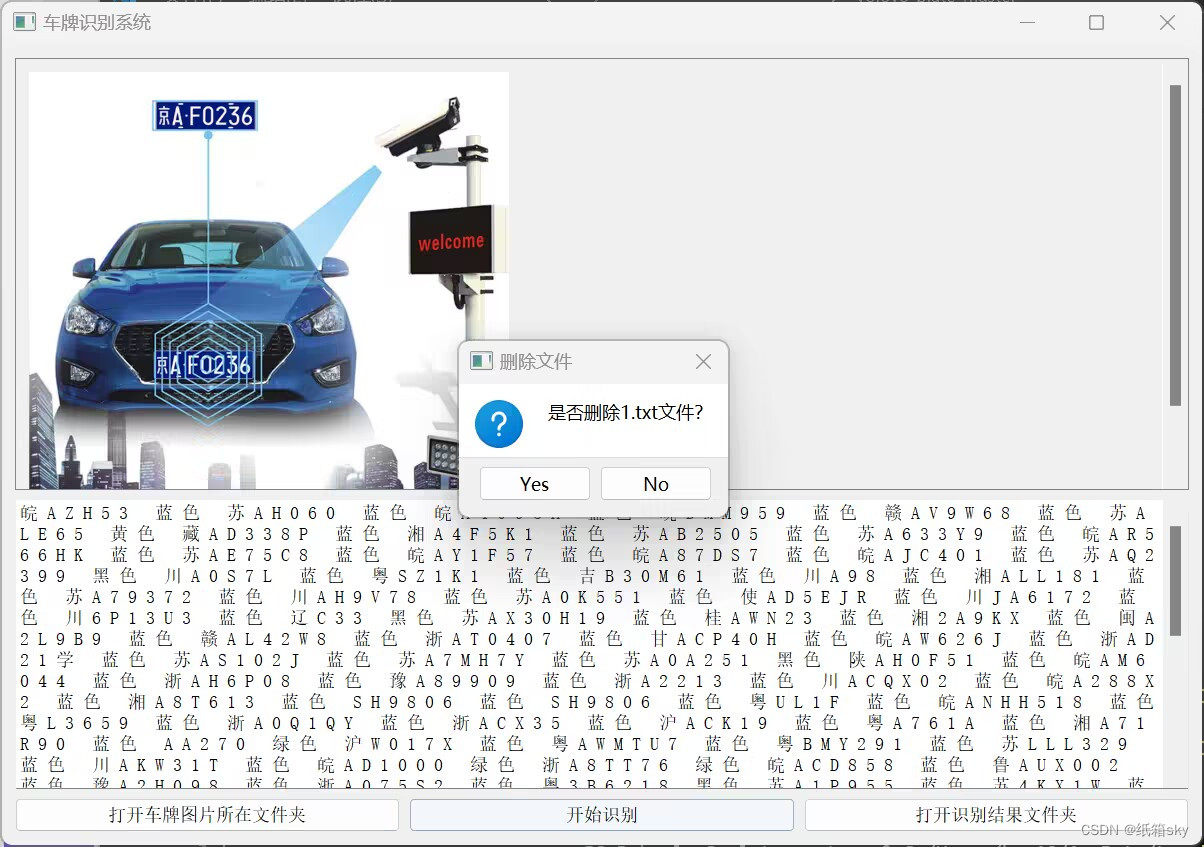
处理后的图像识别出来的车牌图片
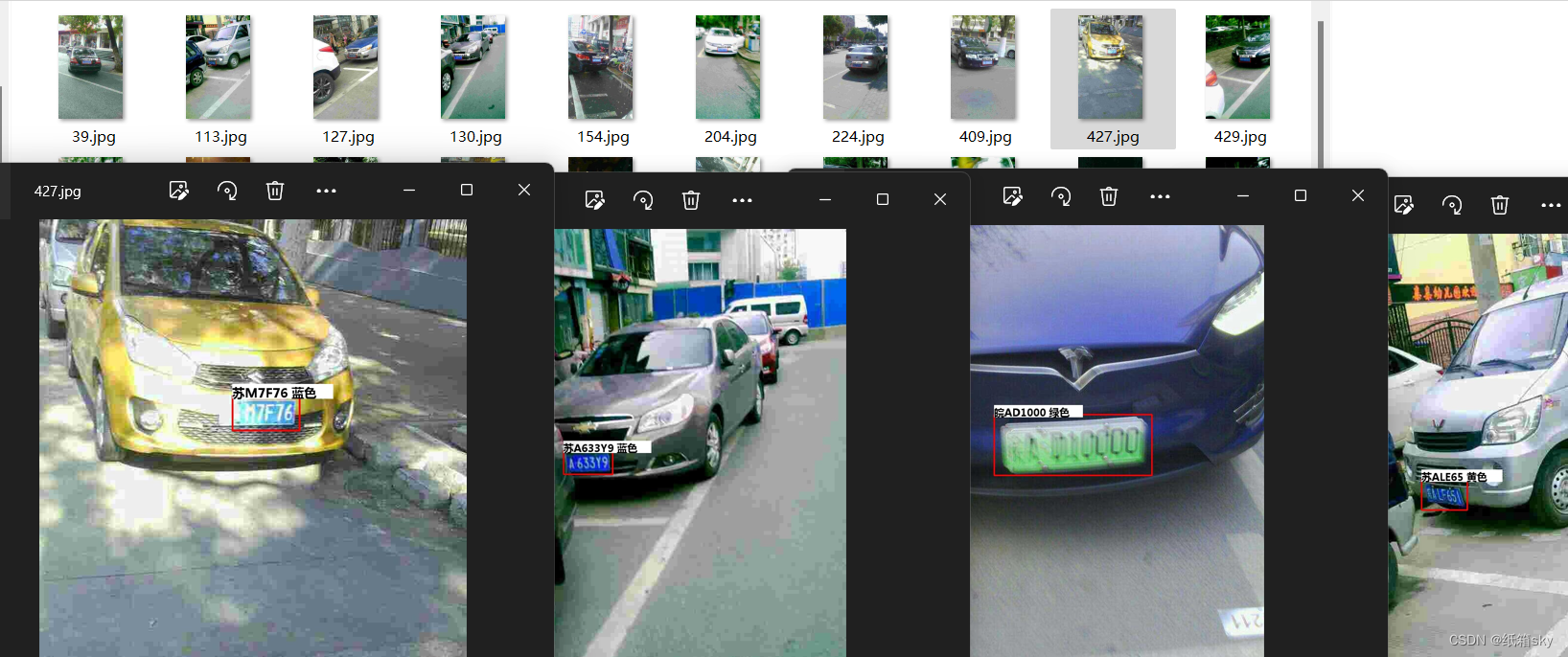
八、完整代码
# 导入必要的库 import torch import cv2 # OpenCV库,用于图像和视频处理 import numpy as np # 用于科学计算的库,尤其是处理数组和矩阵 import argparse # 用于从命令行解析参数 import copy # 用于复制对象 import time # 用于时间处理 import os # 用于与操作系统交互,如文件路径和文件操作 # 导入第三方库 from ultralytics.nn.tasks import attempt_load_weights # 从ultralytics库中导入尝试加载模型权重的函数 from plate_recognition.plate_rec import get_plate_result, init_model, cv_imread # 导入车牌识别相关的函数和初始化模型函数 from plate_recognition.double_plate_split_merge import get_split_merge # 导入双车牌分割合并函数 from fonts.cv_puttext import cv2ImgAddText # 导入在图像上添加文本的函数 # 定义函数:读取文件夹内的文件,并将文件路径添加到列表中 def allFilePath(rootPath, allFIleList): # 读取指定目录下的所有文件和子目录 fileList = os.listdir(rootPath) for temp in fileList: # 如果当前项是一个文件 if os.path.isfile(os.path.join(rootPath, temp)): # 将文件路径添加到列表中 allFIleList.append(os.path.join(rootPath, temp)) else: # 如果当前项是一个子目录,则递归调用allFilePath函数 allFilePath(os.path.join(rootPath, temp), allFIleList) # 定义函数:透视变换得到车牌小图 def four_point_transform(image, pts): # pts为四个顶点的坐标(应该是已排序的),但在这里直接赋值,因为pts已经传入 rect = pts.astype('float32') # 将坐标转换为float32类型 (tl, tr, br, bl) = rect # tl, tr, br, bl 分别代表左上角、右上角、右下角和左下角 # 计算新图像的宽度和高度 widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2)) widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2)) maxWidth = max(int(widthA), int(widthB)) heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2)) heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2)) maxHeight = max(int(heightA), int(heightB)) # 定义目标图像上的四个点(左上角、右上角、右下角、左下角) # 这里定义的是经过透视变换后车牌图像在新坐标系中的位置 dst = np.array([ [0, 0], # 左上角 (0, 0) [maxWidth - 1, 0], # 右上角 (maxWidth - 1, 0) [maxWidth - 1, maxHeight - 1], # 右下角 (maxWidth - 1, maxHeight - 1) [0, maxHeight - 1] # 左下角 (0, maxHeight - 1) ], dtype="float32") # 使用OpenCV的getPerspectiveTransform函数计算透视变换矩阵 M = cv2.getPerspectiveTransform(rect, dst) # 应用透视变换得到车牌小图 warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight)) return warped # YOLO前处理letter_box操作,用于调整图像尺寸以适应模型的输入要求 def letter_box(img, size=(640, 640)): # 获取原始图像的高、宽和通道数 h, w, _ = img.shape # 计算缩放比例,使得图像的长宽比不超过目标尺寸的长宽比 r = min(size[0] / h, size[1] / w) # 计算缩放后的图像尺寸 new_h, new_w = int(h * r), int(w * r) # 缩放图像 new_img = cv2.resize(img, (new_w, new_h)) # 计算在目标尺寸中填充边界的大小(左、上、右、下) left = int((size[1] - new_w) / 2) top = int((size[0] - new_h) / 2) right = size[1] - left - new_w bottom = size[0] - top - new_h # 在图像周围添加边界(填充),使图像大小达到目标尺寸 # 使用黑色(RGB值为(114, 114, 114))进行填充 img = cv2.copyMakeBorder(new_img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114)) # 返回填充后的图像、缩放比例、以及填充的左、上边界大小 return img, r, left, top # 加载yolov8模型 def load_model(weights, device): # 使用ultralytics库中的attempt_load_weights函数尝试加载模型权重 # 这会加载一个FP32精度的模型 model = attempt_load_weights(weights, device=device) return model # 将边界框坐标从(x, y, w, h)格式转换为(x1, y1, x2, y2)格式 def xywh2xyxy(det): # 创建一个与输入det相同形状的新数组y y = det.clone() # 计算左上角坐标(x1, y1) y[:, 0] = det[:, 0] - det[:, 2] / 2 y[:, 1] = det[:, 1] - det[:, 3] / 2 # 计算右下角坐标(x2, y2) y[:, 2] = det[:, 0] + det[:, 2] / 2 y[:, 3] = det[:, 1] + det[:, 3] / 2 # 返回转换后的坐标 return y def my_nums(dets,iou_thresh): #nms操作 y = dets.clone() y_box_score = y[:,:5] index = torch.argsort(y_box_score[:,-1],descending=True) keep = [] while index.size()[0]>0: i = index[0].item() keep.append(i) x1=torch.maximum(y_box_score[i,0],y_box_score[index[1:],0]) y1=torch.maximum(y_box_score[i,1],y_box_score[index[1:],1]) x2=torch.minimum(y_box_score[i,2],y_box_score[index[1:],2]) y2=torch.minimum(y_box_score[i,3],y_box_score[index[1:],3]) zero_=torch.tensor(0).to(device) w=torch.maximum(zero_,x2-x1) h=torch.maximum(zero_,y2-y1) inter_area = w*h nuion_area1 =(y_box_score[i,2]-y_box_score[i,0])*(y_box_score[i,3]-y_box_score[i,1]) #计算交集 union_area2 =(y_box_score[index[1:],2]-y_box_score[index[1:],0])*(y_box_score[index[1:],3]-y_box_score[index[1:],1])#计算并集 iou = inter_area/(nuion_area1+union_area2-inter_area)#计算iou idx = torch.where(iou<=iou_thresh)[0] #保留iou小于iou_thresh的 index=index[idx+1] return keep def restore_box(dets,r,left,top): #坐标还原到原图上 dets[:,[0,2]]=dets[:,[0,2]]-left dets[:,[1,3]]= dets[:,[1,3]]-top dets[:,:4]/=r # dets[:,5:13]/=r return dets # pass def post_processing(prediction,conf,iou_thresh,r,left,top): #后处理 prediction = prediction.permute(0,2,1).squeeze(0) xc = prediction[:, 4:6].amax(1) > conf #过滤掉小于conf的框 x = prediction[xc] if not len(x): return [] boxes = x[:,:4] #框 boxes = xywh2xyxy(boxes) #中心点 宽高 变为 左上 右下两个点 score,index = torch.max(x[:,4:6],dim=-1,keepdim=True) #找出得分和所属类别 x = torch.cat((boxes,score,x[:,6:14],index),dim=1) #重新组合 score = x[:,4] keep =my_nums(x,iou_thresh) x=x[keep] x=restore_box(x,r,left,top) return x def pre_processing(img,opt,device): #前处理 img, r,left,top= letter_box(img,(opt.img_size,opt.img_size)) # print(img.shape) img=img[:,:,::-1].transpose((2,0,1)).copy() #bgr2rgb hwc2chw img = torch.from_numpy(img).to(device) img = img.float() img = img/255.0 img =img.unsqueeze(0) return img ,r,left,top def det_rec_plate(img,img_ori,detect_model,plate_rec_model): result_list=[] img,r,left,top = pre_processing(img,opt,device) #前处理 predict = detect_model(img)[0] outputs=post_processing(predict,0.3,0.5,r,left,top) #后处理 for output in outputs: result_dict={} output = output.squeeze().cpu().numpy().tolist() rect=output[:4] rect = [int(x) for x in rect] label = output[-1] roi_img = img_ori[rect[1]:rect[3],rect[0]:rect[2]] # land_marks=np.array(output[5:13],dtype='int64').reshape(4,2) # roi_img = four_point_transform(img_ori,land_marks) #透视变换得到车牌小图 if int(label): #判断是否是双层车牌,是双牌的话进行分割后然后拼接 roi_img=get_split_merge(roi_img) plate_number,rec_prob,plate_color,color_conf=get_plate_result(roi_img,device,plate_rec_model,is_color=True) result_dict['plate_no']=plate_number #车牌号 result_dict['plate_color']=plate_color #车牌颜色 result_dict['rect']=rect #车牌roi区域 result_dict['detect_conf']=output[4] #检测区域得分 # result_dict['landmarks']=land_marks.tolist() #车牌角点坐标 # result_dict['rec_conf']=rec_prob #每个字符的概率 result_dict['roi_height']=roi_img.shape[0] #车牌高度 # result_dict['plate_color']=plate_color # if is_color: result_dict['color_conf']=color_conf #颜色得分 result_dict['plate_type']=int(label) #单双层 0单层 1双层 result_list.append(result_dict) return result_list def draw_result(orgimg,dict_list,is_color=False): # 车牌结果画出来 result_str ="" for result in dict_list: rect_area = result['rect'] x,y,w,h = rect_area[0],rect_area[1],rect_area[2]-rect_area[0],rect_area[3]-rect_area[1] padding_w = 0.05*w padding_h = 0.11*h rect_area[0]=max(0,int(x-padding_w)) rect_area[1]=max(0,int(y-padding_h)) rect_area[2]=min(orgimg.shape[1],int(rect_area[2]+padding_w)) rect_area[3]=min(orgimg.shape[0],int(rect_area[3]+padding_h)) height_area = result['roi_height'] # landmarks=result['landmarks'] result_p = result['plate_no'] if result['plate_type']==0:#单层 result_p+=" "+result['plate_color'] else: #双层 result_p+=" "+result['plate_color']+"双层" result_str+=result_p+" " # for i in range(4): #关键点 # cv2.circle(orgimg, (int(landmarks[i][0]), int(landmarks[i][1])), 5, clors[i], -1) cv2.rectangle(orgimg,(rect_area[0],rect_area[1]),(rect_area[2],rect_area[3]),(0,0,255),2) #画框 labelSize = cv2.getTextSize(result_p,cv2.FONT_HERSHEY_SIMPLEX,0.5,1) #获得字体的大小 if rect_area[0]+labelSize[0][0]>orgimg.shape[1]: #防止显示的文字越界 rect_area[0]=int(orgimg.shape[1]-labelSize[0][0]) orgimg=cv2.rectangle(orgimg,(rect_area[0],int(rect_area[1]-round(1.6*labelSize[0][1]))),(int(rect_area[0]+round(1.2*labelSize[0][0])),rect_area[1]+labelSize[1]),(255,255,255),cv2.FILLED)#画文字框,背景白色 if len(result)>=6: orgimg=cv2ImgAddText(orgimg,result_p,rect_area[0],int(rect_area[1]-round(1.6*labelSize[0][1])),(0,0,0),21) # orgimg=cv2ImgAddText(orgimg,result_p,rect_area[0]-height_area,rect_area[1]-height_area-10,(0,255,0),height_area) # 假设你在循环中或根据某些条件判断需要不断记录数据 for data_to_record in result_str: # your_data_source 应替换为你的数据来源,如循环变量或检测结果 # 构建你想要写入的数据字符串 record_content = f"{data_to_record} " # \n 表示换行,使每次记录都在新的一行 # 使用追加模式 ('a') 打开文件,这样每次写入都不会覆盖之前的记录 with open('1.txt', 'a', encoding='utf-8') as file: file.write(record_content) # 这里可以继续其他操作,每次循环或条件满足时都会向文件追加内容 print(result_str) return orgimg if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument('--detect_model', nargs='+', type=str, default=r'weights/yolov8s.pt', help='model.pt path(s)') #yolov8检测模型 parser.add_argument('--rec_model', type=str, default=r'weights/plate_rec_color.pth', help='model.pt path(s)')#车牌字符识别模型 parser.add_argument('--image_path', type=str, default=r'imgs', help='source') #待识别图片路径 parser.add_argument('--img_size', type=int, default=640, help='inference size (pixels)') #yolov8 网络模型输入大小 parser.add_argument('--output', type=str, default='result', help='source') #结果保存的文件夹 device =torch.device("cuda" if torch.cuda.is_available() else "cpu") clors = [(255,0,0),(0,255,0),(0,0,255),(255,255,0),(0,255,255)] opt = parser.parse_args() save_path = opt.output if not os.path.exists(save_path): os.mkdir(save_path) detect_model = load_model(opt.detect_model, device) #初始化yolov8识别模型 plate_rec_model=init_model(device,opt.rec_model,is_color=True) #初始化识别模型 #算参数量 total = sum(p.numel() for p in detect_model.parameters()) total_1 = sum(p.numel() for p in plate_rec_model.parameters()) print("yolov8 detect params: %.2fM,rec params: %.2fM" % (total/1e6,total_1/1e6)) detect_model.eval() # print(detect_model) file_list = [] allFilePath(opt.image_path,file_list) count=0 time_all = 0 time_begin=time.time() for pic_ in file_list: print(count,pic_,end=" ") time_b = time.time() #开始时间 img = cv2.imread(pic_) img_ori = copy.deepcopy(img) result_list=det_rec_plate(img,img_ori,detect_model,plate_rec_model) time_e=time.time() ori_img=draw_result(img,result_list) #将结果画在图上 img_name = os.path.basename(pic_) save_img_path = os.path.join(save_path,img_name) #图片保存的路径 time_gap = time_e-time_b #计算单个图片识别耗时 if count: time_all+=time_gap count+=1 cv2.imwrite(save_img_path,ori_img) #op # print(result_list) print(f"sumTime time is {time.time()-time_begin} s, average pic time is {time_all/(len(file_list)-1)}")


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









