







 本文介绍了两种相对高级的聚类算法——谱聚类和Chameleon聚类。谱聚类从简正模式的角度解释,通过降维找到数据特征空间进行聚类。Chameleon算法结合近邻数据聚类,适用于识别特殊形状的簇,尤其适合处理甜甜圈等结构。这两种算法在处理复杂数据结构时表现出优于K-means的特点。
本文介绍了两种相对高级的聚类算法——谱聚类和Chameleon聚类。谱聚类从简正模式的角度解释,通过降维找到数据特征空间进行聚类。Chameleon算法结合近邻数据聚类,适用于识别特殊形状的簇,尤其适合处理甜甜圈等结构。这两种算法在处理复杂数据结构时表现出优于K-means的特点。
上一篇文章里说到的层次聚类和K-means聚类,可以说是聚类算法里面最基本的两种方法(wiki的cluster analysis页面都把它们排前两位)。这次要探讨的,则是两个相对“高级”一点的方法:谱聚类和chameleon聚类。
4、谱聚类
一般说到谱聚类,都是从降维(Dimensionality Reduction)或者是图分割(Graph Cut)的角度来理解。但是实际上,从物理学的简正模式的角度,可以更为直观地理解这个算法的本质。
这里先把基本的算法步骤写出来,然后再讨论算法的原理。
谱聚类基本步骤:
1、给出N个数据点两两之间的相似性。也就是一个N*N的相似性矩阵A,A(i,j)代表i和j两个数据点的相似度,数值越大则表示越相似。注意A(i,j)=A(j,i),A(i,i)=0。
2、计算矩阵D,使它的对角元是A矩阵的对应的那一列(或行)的值之和,其余地方为0。也就是使得
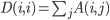
3、令B=D-A
4、求B矩阵的前k个本征值和本征矢,将数据点投影到一个k维空间。第i本征矢的第j个值,就表示第j个数据点在k维空间中第i维的投影。就是说如果把k个特征矢量并成一个N*k的矩阵,则每一行代表一个数据点在k维空间的坐标。
5、根据每个数据点的k维空间坐标,使用K-means或者其它聚类算法在k维空间对数据进行聚类。
从算法的第4、5步就可以看出,谱聚类的本质实际上就类似于PCA,先将数据点投影到一个更能反映数据特征的空间,然后再用其它办法进行聚类。这也就是一种降维的思想(实际上也可能是升维)。那么问题的关键就在于,它把数据点投影到什么空间去了?为什么这个空间更能反映数据特征?这个问题可以从图分割的角度来理解(看这里),不过我这里要从简谐振动的角度来讨论这个问题,这也是一个更为直观的理解。
简正模式
说起简谐振动,学过高中物理的童鞋都不会陌生:两个小球连上一根弹簧,就是最简单的简谐振动模型。为了简单起见,写成一维的形式,而且弹簧的平衡距离设为0,于是,当小球的坐标给定时,弹性势能就是
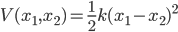
我们把上面那个算法套用在这个例子上试试,两个小球的“相似度”就看成是它们之间弹簧的弹性系数k,k越大,小球之间的关系自然就越紧密了。这样上面要求的矩阵就是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 394
394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









