






Tips 最好装个jupyter notebook 便于可视化
一. 专有名词
1. state(s)表示物体的状态
2. agent 智能体
3. action 动作

在这张图片中,左边一整张图片是state,马里奥是agent,左右上三个动作是action
4. policy pai 策略

5. reward R 奖励
6. state transition 状态转移
注意状态转移是具有随机性的,也就是下一个状态是不确定的。
关系
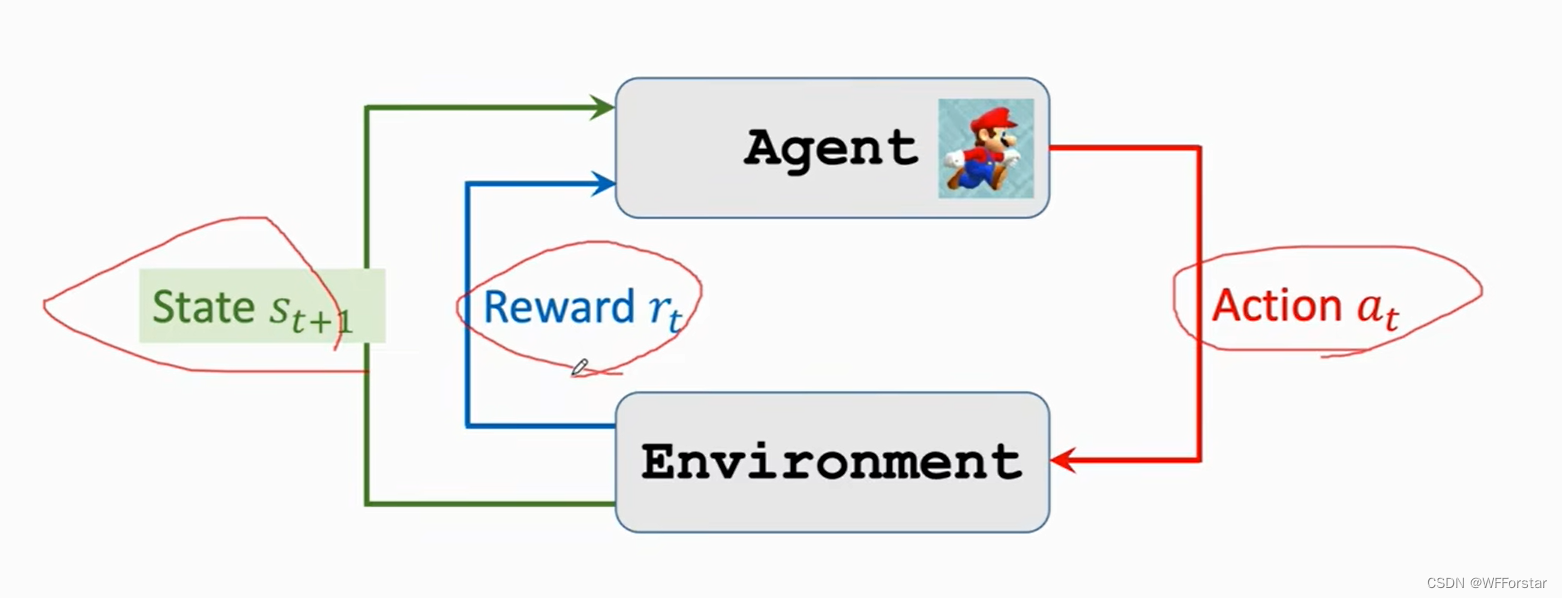
上述基本概念都有一定的联系,如上图所示。
随机性
在深度强化学习中,随机性主要来自于两个方面:agent的action具有随机性,state transition也具有随机性。
return 回报

回报是指从t时刻开始直到结束所有奖励的累加,如定义1。
但事实上,每个时间点的奖励的权重并不相通,越未来的回报权重越低,因此定义了一个折扣率gama,通过定义2这个公式来实现求得更符合实际的回报。因此,折扣率gama设置的大小和深度强化学习的结果有一定的关系。
而奖励同样具有随机性,是由state和action决定的,因此回报return也同样具有随机性,由state和action决定
Action-Value Function 动作价值函数

Qpai函数是指在pai策略下得到的动作价值函数,而Q函数是指最优动作价值函数,定义就是当policy=pai时,取得的Qpai最大,因此Q与pai已经无关,它的实际意义是当agent处于St 这个state的时候,动作at好不好。

Vpai是状态价值函数,用来评价状态是好是坏。
















 6345
6345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











