







- 1.HBase简介
- 2.HBase的数据模型
- 3.HBase的物理模型
- 4.HBase的架构体系
- 5.HBase的基础知识
- 6.HBase伪分布式环境安装
- 7.HBase的Shell操作
- 7.1创建表create 'student','stu_id','address','info'
- 7.2列出全部表list
- 7.3表的描述describe 'student'
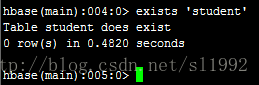
- 7.4表是否存在exists 'student'
- 7.5表是否可用/禁用is_enabled 'student',is_disabled 'student'
- 7.6添加记录put
- 7.7查看记录
- 7.8查看表中记录总数count 'student'
- 7.9查看所有记录scan 'student'
- 7.10获取表某个列中的版本数据
- 7.11更新/修改操作
- 7.12获取版本数据
- 7.13删除一列数据delete 'student','zhangsan','info:age'
- 7.14删除一行数据deleteall 'student','zhangsan'
- 7.15清空表truncate 'student'
- 7.16删除表
- 7.17退出quit
- 8.停止HBase
HBase伪分布式环境搭建及命令行使用
1.HBase简介
Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。HBase利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,利用ZooKeeper作为协调工具。
2.HBase的数据模型
- 表(table),是存储管理数据的。
- 行键(row key),类似于MySQL中的主键。
行键是HBase表天然自带的,Table中的记录按照Row Key排序。 - 列簇(column family),列的集合。
HBase中列簇是需要在定义表时指定的,列是在插入记录时动态增加的。
HBase表中的数据,每个列簇单独一个文件。 - 时间戳(timestamp),列(也称作标签、修饰符)的一个属性。
行键和列确定的单元格,可以存储多个数据,每个数据含有时间戳属性,数据具有版本特性。
如果不指定时间戳或者版本,默认取最新的数据。 - 存储的数据都是字节数组。
- 表中的数据是按照行键的顺序物理存储的。
3.HBase的物理模型
- HBase是适合海量数据(如20PB)的秒级简单查询的数据库。
- HBase表中的记录,按照行键进行拆分, 拆分成一个个的region。
许多个region存储在region server(单独的物理机器)中的,这样,对表的操作转化为对多台region server的并行查询。
4.HBase的架构体系
- Client
包含访问HBase的接口,Client维护着一些cache 来加快对HBase的访问,比如region的位置信息 - ZooKeeper
①保证任何时候,集群中只有一个running master
②存贮所有Region的寻址入口
③实时监控Region Server的状态,将Region Server的上线和下线信息,实时通知给Master
④存储Hbase 的schema,包括有哪些table,每个table 有哪些column family - Master
①可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行
②为Region Server分配region
③负责Region Server 的负载均衡
④发现失效的Region Server并重新分配其上的region - Region Server
①维护Master分配给它的region,处理对这些region的IO请求
②负责切分在运行过程中变得过大的region
可以看出,Client访问HBase上数据的过程并不需要Master参与,寻址访问ZooKeeper和Region Server,数据读写访问Region Server。HRegionServer主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。
5.HBase的基础知识
HBase中有两张特殊的Table,-ROOT-和.META.
.META.:记录了用户表的Region信息,.META.可以有多个regoin
-ROOT-:记录了.META.表的Region信息,-ROOT-只有一个region
ZooKeeper中记录了-ROOT-表的location
Client访问用户数据之前需要首先访问ZooKeeper,然后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问。
6.HBase伪分布式环境安装
HBase是依赖Hadoop的数据存储系统,所以安装HBase前Hadoop环境要安装成功,可参见hadoop2.6.4伪分布式环境搭建
由于HBase自带ZooKeeper,所以ZooKeeper可以不用安装。HBase内置的ZooKeeper效果一般不好,一般都选择外置独立的ZooKeeper。下面会有说到如何使用独立的,如何使用默认自带的,想学习HBase可以不安装外置独立的ZooKeeper。
6.1下载HBase
下载HBase,选择当前稳定版stable。将下载的hbase-1.2.4-bin.tar.gz拷贝到Linux系统/root/Downloads目录下,解压到/usr/local/目录下tar -zxvf hbase-1.2.4-bin.tar.gz -C /usr/local/
6.2配置系统环境变量
vi /etc/profile,文件末尾配置内容:
export JAVA_HOME=/usr/local/java/jdk1.8.0_101
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.6.0
export ZOOKEEPER_HOME=/usr/local/zookeeper-3.4.9-1
export HBASE_HOME=/usr/local/hbase-1.2.4
export PATH=.:$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$HBASE_HOME/bin6.3验证环境变量是否配置成功
hbase version

6.4修改hbase-env.sh文件
修改${HBASE_HOME}/conf/hbase-env.sh文件
①修改设置JAVA_HOMEexport JAVA_HOME=/usr/local/jdk
②修改设置HBASE_MANAGES_ZK,export HBASE_MANAGES_ZK=true为true表示使用HBase自带的ZooKeeper,为false表示使用独立的ZooKeeper,需要安装ZooKeeper
6.5修改hbase-site.xml文件
修改${HBASE_HOME}/conf/hbase-site.xml文件,配置内容如下:
<property>
<name>hbase.rootdir</name>
<value>hdfs://cyyun:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>cyyun</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>注:hbase.rootdir的值一定要与Hadoop的配置文件core-site.xml中fs.default.name的值相同,hbase.zookeeper.quorum的值一定是启动HBase所在的机器主机名
6.6修改regionservers文件
修改文件的内容为主机名cyyun
6.7启动HBase
首先确保Hadoop集群已经启动。
执行命令start-hbase.sh,启动HBase

使用jps查看进程
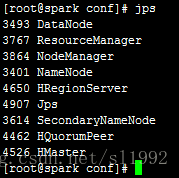
可以看到新增了3个Java进程HMaster、HRegionServer、HQuorumPeer。
可以在浏览器上查看地址http://cyyun:16010,可以看到HBase的管理界面。
注:hbase1.0以前的版本端口号是60010,需要自己手动配置,在文件hbase-site.xml中添加如下配置,就可以使用http://cyyun:60010访问了。
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>查看HDFS目录,会发现根目录下多了一个hbase的目录hadoop fs -ls /
停止命令是stop-hbase.sh
此时HBase使用自带的ZooKeeper伪分布式环境安装成功。
6.8使用独立的ZooKeeper搭建HBase
①修改设置HBASE_MANAGES_ZK,export HBASE_MANAGES_ZK=false
②分别启动ZooKeeper
③启动Hadoop
④启动HBase
查看进程jps,除了HMaster、HRegionServer,多出3个zk进程QuorumPeerMain。
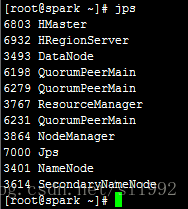
此时进入到ZooKeeper的命令行Shell,ls /查看到ZooKeeper多出来一个节点hbase

此时HBase使用独立的ZooKeeper伪分布式环境安装成功。
7.HBase的Shell操作
HBase启动成功后,输入命令hbase shell进入到HBase提供的一个Shell的终端进行交互
| 名称 | 命令表达式 |
|---|---|
| 创建表 | create '表名称','列簇名称1','列簇名称2','列簇名称N' |
| 列出全部表 | list |
| 得到表的描述 | describe '表名称' |
| 检查表是否存在 | exists '表名称' |
| 表是否可用/禁用 | is_enabled '表名称';is_disabled '表名称' |
| 添加记录 | put '表名称','行名称','列簇名称:列名称','值' |
| 获取一个行键记录 | get '表名称','行名称' |
| 获取一个行键,一个列簇的所有数据 | get '表名称','行名称','列簇名' |
| 获取一个行键,一个列簇中的一个列的所有数据 | get '表名称','行名称','列簇名:列名称' |
| 查看表中记录总数 | count '表名称' |
| 查看所有记录 | scan '表名称' |
| 查看一个表一个列中所有数据 | get '表名称',{COLUMNS=>'列簇名称:列名称'} |
| 更新/修改记录 | 并不是修改,就是重写一遍进行覆盖 |
| 获取版本数据 | get '表名称',{COLUMNS=>'列簇名称:列名称',VERSIONS=>1} |
| 根据时间戳获取版本数据 | get '表名称','行名称',{COLUMN=>'列簇名称:列名称',TIMESTAMP=>时间戳} |
| 删除一列记录 | delete '表名称','行名称','列簇名称:列名称' |
| 删除一条记录(一个行键记录) | deleteall '表名称','行名称' |
| 清空表 | truncate '表名称' |
| 删除一张表 | 先要禁用该表,才能对该表进行删除,第一步disable '表名称',第二步drop '表名称' |
7.1创建表create 'student','stu_id','address','info'

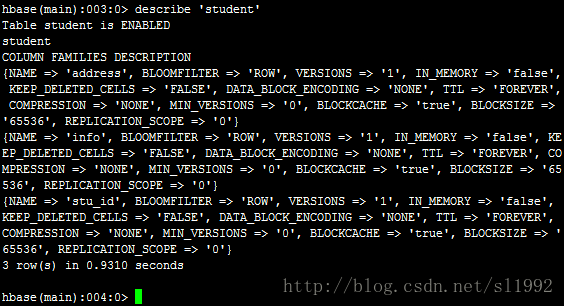
表student,有三个列簇stu_id,address,info
7.2列出全部表list
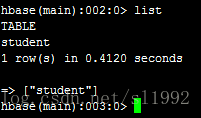
7.3表的描述describe 'student'
7.4表是否存在exists 'student'
7.5表是否可用/禁用is_enabled 'student',is_disabled 'student'
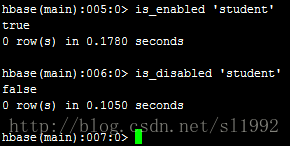
返回true/false
7.6添加记录put
put 'student','zhangsan','info:age','24';
put 'student','zhangsan','info:birthday','1987-06-17';
put 'student','zhangsan','info:company','alibaba';
put 'student','zhangsan','address:contry','china';
put 'student','zhangsan','address:province','zhejiang';
put 'student','zhangsan','address:city','hangzhou';
put 'student','lisi','info:birthday','1987-4-17';
put 'student','lisi','info:favorite','movie';
put 'student','lisi','info:company','alibaba';
put 'student','lisi','address:contry','china';
put 'student','lisi','address:province','guangdong';
put 'student','lisi','address:city','jieyang';
put 'student','lisi','address:town','xianqiao'7.7查看记录
①获取一个行键的所有数据get 'student','zhangsan'
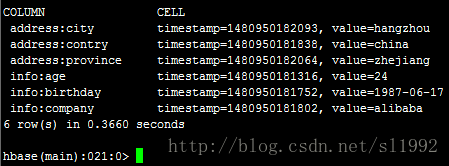
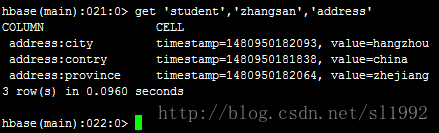
②获取一个行键,一个列簇的所有数据get 'student','zhangsan','address'
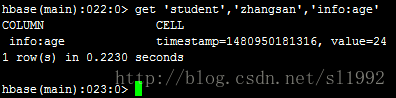
③获取一个行键,一个列簇中的一个列的所有数据get 'student','zhangsan','info:age'
7.8查看表中记录总数count 'student'

两个行键,所以是两条数据。
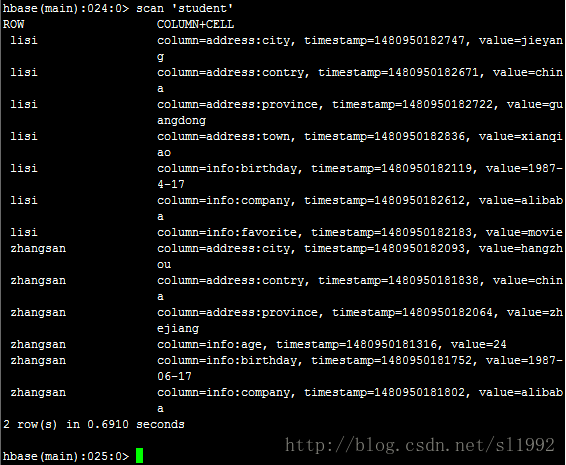
7.9查看所有记录scan 'student'
7.10获取表某个列中的版本数据
get 'student','zhangsan',{COLUMN=>'info:age',VERSIONS=>1}

7.11更新/修改操作
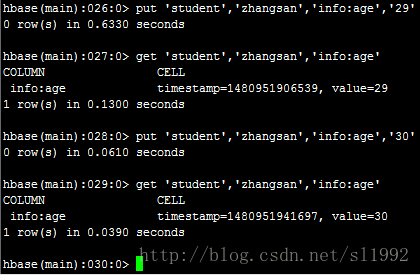
put 'student','zhangsan','info:age','29'
get 'student','zhangsan','info:age'
put 'student','zhangsan','info:age','30'
get 'student','zhangsan','info:age'可以看出age的覆盖,HBase获取的是最新的数据,以前的数据也是存在的,可通过版本获取。
7.12获取版本数据
get 'student','zhangsan',{COLUMN=>'info:age',VERSIONS=>2}
get 'student','zhangsan',{COLUMN=>'info:age',VERSIONS=>3}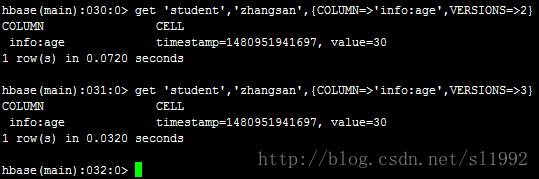
根据时间戳获取版本数据
get 'student','zhangsan',{COLUMN=>'info:age',TIMESTAMP=>1480951906539}

7.13删除一列数据delete 'student','zhangsan','info:age'
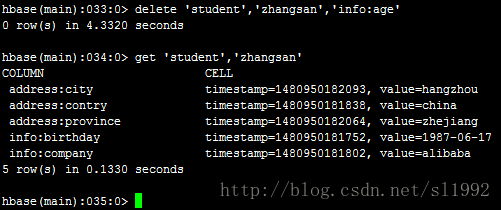
7.14删除一行数据deleteall 'student','zhangsan'
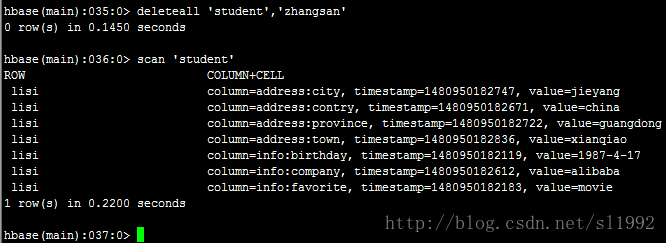
7.15清空表truncate 'student'
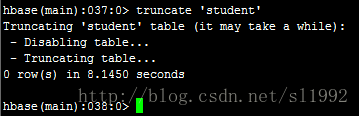
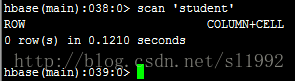
7.16删除表
disable 'student'
drop 'student'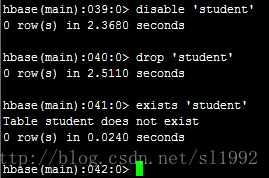
7.17退出quit

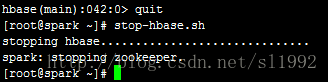
8.停止HBase
stop-hbase.sh















 3161
3161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









