









前言:众所周知,Python的编码解码是一个令人头疼的问题。正好笔者最近做项目时遇到了这个问题,且编码解码问题在大多数语言中都会遇到。遂借此机会重新深入学习一下并写此学习笔记。
- 在讲编码解码之前,需要先引入几个常用的编码方式,即:
- ASCII码
- Unicode码
- UTF-8码(UTF-16码、UTF-32码…)
- GB2312码(中文)、Shift_JIS码(日语)、Euc-kr码(韩语)和TIS-620码(泰语)…
一、ASCII码的来源
【背景】:我们都知道,在计算机中底层的机器指令都是由二进制0-1组成,我们存储在计算机中的文字(字符串)和数字等信息均在底层被转换成0-1代码运行。
【出现问题】:那么,如何将我们所表达的文字和数字等信息转换成对应的0-1代码呢?ASCII编码方式应运而生。
【初步解决方法】:在美国人最初设计计算机时,使用127个含有大小写字母、数字和一些符号的字符编码成对应的0-1代码,其中每个字符用一个字节(byte)表示,一个字节有8个bit。如下面字符A的ASCII码表示:
| 字符 | 十进制ASCII码 | 二进制ASCII码 | 特点 |
|---|---|---|---|
| A | 65 | 0100 0001 | 每个字符用一个字节(byte)表示 |
这样我们就可以通过ASCII编码方式在计算机存储英文、数字和基本标点符号等字符。
二、Unicode码的来源
【ASCII码的局限性】:虽然有了ASCII编码方式可以让我们在计算机中进行基本英文操作,但这种方式对于非英语为母语的外国人来说很不友好。
【初步解决】:因此,各国将自己的文字整合成各国语言的编码方式。如GB2312码(中文)、Shift_JIS码(日语)、Euc-kr码(韩语)和TIS-620码(泰语)。
【引出问题1】:不同的国家使用不同的编码,编码的不统一导致其所写的文本用其他编码方式就无法展现或出现乱码,信息交流效率降低。那如何解决呢?Unicode编码方式应运而生。
【解决方案】:把全球的编码方案都添加到统一的一套方案中。这套方案称为Unicode编码方案。这样对于各种语言,只要使用Unicode编码成对应二进制码,就可以顺利在计算机中存储、读取。
【引出问题2】:而由于Unicode编码要表达的字符更多,所以仅仅通过一个字节8bit来表示一个字符(如ASCII码)是不够的,【一个字节可以表示的字符有2^8-1=255个<127个,所以ASCII码可以满足需求,而Unicode码不行】
【解决方案】:通过用两个字节16bit来表示一个字符,这样最多就可以表示2^16-1=65535个字符。【因此,如果以后需要表达的字符继续增多,还可以通过扩充字节来解决,用3个字节、4个字节乃至更多来表示一个字符】(若不够,前方补零即可)
| 字符 | 二进制ASCII码 | 二进制Unicode码 | Unicode码特点 |
|---|---|---|---|
| A | 0100 0001 | 00000000 01000001 | 每个字符用两个字节表示 |
三、UTF-8码的来源
【Unicode码的问题】:虽然有了Unicode编码方式可以让使用不同语言的人在计算机中进行读写,但随着Unicode添加的编码方案增多,每个字符都用2个或更多字节来表示很浪费空间,尤其是在①存储和②网络传输的时候(一个字符A能用8bit01000001表示干嘛还要用16bit00000000 01000001表示?)。可不可以用最少的字节表示不同的字符?UTF-8编码方式应运而生。
【解决方案】:UTF全称Unicode Transformation Format(Unicode转换格式)。顾名思义就是根据不同字符将对应Unicode码在能唯一标识的条件下进行变短处理。如针对字符A的Unicode码00000000 01000001转换成01000001以减少存储字节。
| 字符 | 二进制Unicode码 | 二进制UTF-8码 | UTF-8码特点 |
|---|---|---|---|
| A | 00000000 01000001 | 01000001 | 每个字符用尽可能少的字节表示 |
【补充】:
- UTF-8码表示使用
1、2、3、4个字节表示所有字符,在能唯一标识的条件下,优先使用最小的字节表示某个字符,以下同理。 - UTF-16码表示使用
2、4个字节表示所有字符。 - UTF-32码表示使用
4个字节表示所有字符。 - 综上所述,UTF-X中的X表示Unicode码转换使用的最小bit数。
- 由以上表格也可发现,ASCII码是UTF-8码的部分表示形式(故对于只支持ASCII码的文档在UTF-8码下也能正常打开显示)。
【总结】:UTF系列编码是为了最大程度减少Unicode码浪费的空间,在①存储和②网络传输中减轻编码体量。
| 编码方案 | 区别 |
|---|---|
| ASCII码 | ①每个字符用1个字节表示;②仅能表达英文、数字和基本的标点符号 |
| Unicode码 | ①每个字符用2个或更多字节表示;②能表达全球所有的语言 |
| UTF-X码 | 在Unicode码基础上,每个字符用尽可能少的字节表示 |
四、Python3中的编码和解码
4.1 什么时候使用Unicode码?什么时候使用UTF-8码?
由于Unicode码是包含了全球所有语言的较完善的编码方式,所以平常我们在编辑文档的时候均使用Unicode码,而在进行存储和网络传输的时候便转换成UTF-8码减少体量。
- 编辑文档——>使用Unicode码
- 存储和网络传输——>使用UTF-8码
在Python3中,使用encode表示编码;使用decode表示解码:
- 【编码】Unicode码——>其他编码
- 【解码】其他编码——>Unicode码
4.2 Python3编码解码使用案例
1.在Python3中,在字符串str前面加u表示为Unicode码,不过str默认为Unicode码,所以即便不加也表示为Unicode码。
>>> u'aA1,aA1'
'aA1,aA1'
>>> 'aA1,aA1'
'aA1,aA1'
2.当我们对文档进行存储或网络传输时需要把Unicode码编码为UTF-8码,使用encode函数将Unicode码转换为UTF-8或ASCII码,b表示后面引号里的数据类型是bytes,即字节。则后面每个字符对应一个字节。
>>> 'aA1,aA1'.encode('utf-8')
b'aA1,aA1'
>>> 'aA1,aA1'.encode('ASCII')
'aA1,aA1'
3.如果将含有中文汉字或标点符号的Unicode码表示的str转换为UTF-8码表示的字节,则每个中文字符会用三个字节表示。如下:我→\xe6\x88\x91;。→\xe3\x80\x82,其中无法用ascii码表示的字节用\x##表示;
而如果将含有中文的Unicode码表示的str转换为ASCII码表示的字节,则会报UnicodeEncodeError。
>>> 'aA1.我aa。'.encode('utf-8')
b'aA1.\xe6\x88\x91aa\xe3\x80\x82' // UTF-8编码方式用三个字节表示
>>> 'aA1.我aa。'.encode('gbk')
b'aA1.\xce\xd2aa\xa1\xa3' // GBK编码方式用两个字节表示
>>> 'aA1.我aa。'.encode('ASCII')
UnicodeEncodeError: 'ascii' codec can't encode character '\u6211' in position 4: ordinal not in range(128)
4.当我们编辑文档时需要把utf-8码解码为Unicode码。
>>> b'aA1.\xe6\x88\x91aa\xe3\x80\x82'.decode()
'aA1.我aa。'
4.3 Python3不同编码方式之间的转换
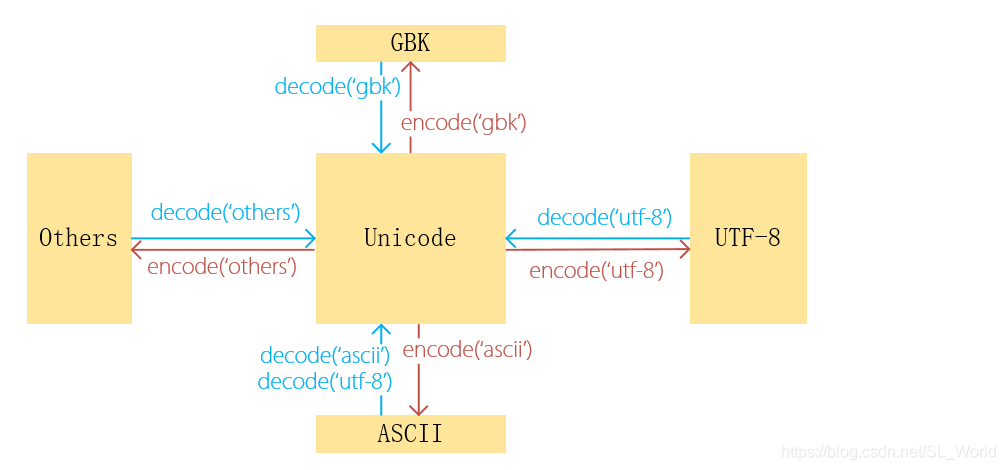
下图是不同编码方式之间的转换图:
【解释】:
1)其中,ASCII码可以用UTF-8码解码,因为之前说过ASCII码是UTF-8码中的一部分。
>>> u'aA1.aa'.encode('ascii').decode('utf-8')
'aA1.aa'
>>> u'aA1.aa'.encode('ascii').decode('ascii')
'aA1.aa'
2)含有中文的GBK码表示的字节,也可以转换为UTF-8码表示的字节:
// 含有两个字节的\x##是GBK码
>>> b'aA1.\xce\xd2aa\xa1\xa3'.decode('gbk').encode('utf-8')
b'aA1.\xe6\x88\x91aa\xe3\x80\x82'
// 含有三个字节的\x##是UTF-8码
>>> b'aA1.\xe6\x88\x91aa\xe3\x80\x82'.decode('utf-8')
aA1.我aa。
3)对于不兼容的两种编码方式(如GBK码和UTF-8码),无法相互直接进行编解码,常见错误如下:
>>> 'aA1.我aa。'.encode('gbk')
b'aA1.\xce\xd2aa\xa1\xa3' // GBK码
>>> 'aA1.我aa。'.encode('gbk').decode('utf-8') // 无法对GBK码进行UTF-8解码
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xce in
position 4: invalid continuation byte
报错信息显示,UTF-8编码方案无法对字节\xce进行解码,该字节0xce在当前字节数组的索引是4(从0开始计数)















 335
335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











