









项目背景
Tardigrade这个项目是trino社区最近一年启动的项目,核心目标是为了补充trino在批处理ETL场景可以提供更稳定可靠的使用体验。
为什么trino需要批处理场景
很多人会疑惑trino作为一个即席分析的分析引擎,为什么需要用来做批处理ETL任务。而提到批处理ETL任务,大家往往想到Spark、Hive等主流批处理引擎,我们为何不直接选择这些批处理引擎来做ETL任务?
实际上使用trino做批处理ETL的用户场景是真实存在,举几个场景:
- 当一个BI分析人员使用trino写了大概200行的分析SQL,通过trino执行并拿到想要的结果。同时又希望把这个SQL脚本作为一个ETL任务T+1调度执行的时候,他就需要将SQL脚本转换成spark sql或者hive sql来执行,这中间需要他分析和解决引擎之间语法上的差异问题,对比数据来确定没有因为不同引擎之间函数实现差异带来的最终数据正确性问题。这大大增加了数据开发的时间成本。
- 当一个BI分析人员执行一个比较复杂的分析SQL而因为trino集群内存资源不足而失败,如果trino可以提供更稳定但查询响应可能稍微延长,用户会更倾向于使用批处理模式的trino来运行,而不是花大量时间改写成其他引擎的SQL来执行。
- trino的物化视图。视图的物化就是一种ETL任务,有更可靠的批处理模式运行是最佳的。
为什么批处理场景不适用
trino或者说presto的最初设计的场景面向数据分析人员提供一种比Hive/Spark更快的交互式查询,为了达到更快的响应,在架构设计上采用了基于内存计算、Pipeline方式(或者说Stream方式)的任务执行架构。同时考虑到adhoc交互式查询一般都响应很快,所以在设计之初就没考虑task的容错等问题。
当使用trino用于做批处理ETL的场景时,原来的设计就会存在以下一些问题:
- 对于 long-running的ETL,task失败的可能性就比较大;而每次个别task失败,需要整个query重新运行,浪费比较多的计算资源同时也很难满足任务在预估时间可靠完成的需求。
- All-At-Once的stage执行模式对整个集群内存压力是比较大,当query的查询数据集比较大的情况下,小集群出现内存资源不足导致query失败的概率将会非常大。
核心架构原理
Tardigrade为了更好的支持批处理场景,在之前的query调度执行架构上新增了更适合批处理场景的架构模型。
接下来从以下个方面来描述一下Tardigrade在核心架构对比之前有哪些差异。
- query调度执行模型
- exchange的实现变化
- task的约束
调度执行模型
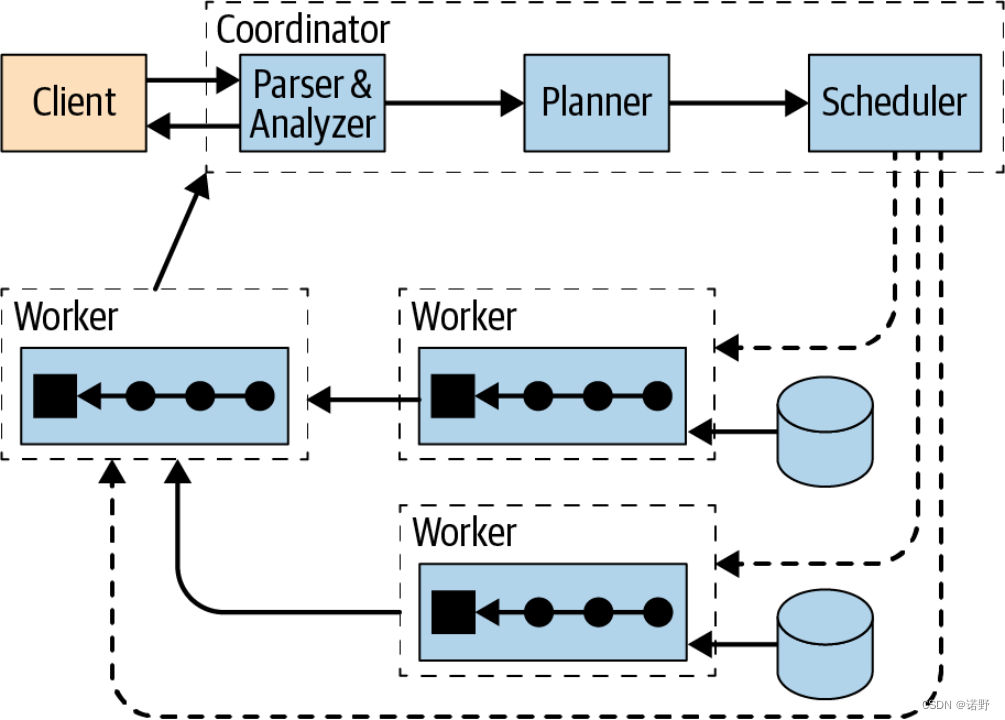
从上图trino整体架构来看,一个SQL经过parser、analyner、optimize和planner,最终生成物理执行计划交给scheduler执行。下面要说的两个调度执行模型指的就是图中scheduler这个模块的两个不同实现:Pipeline和Fault-tolerant。scheduler会基于物理执行计划去生成相应stage DAG,而两种不同的调度模型实现,对于如何调度stage和task会有比较大的差异。
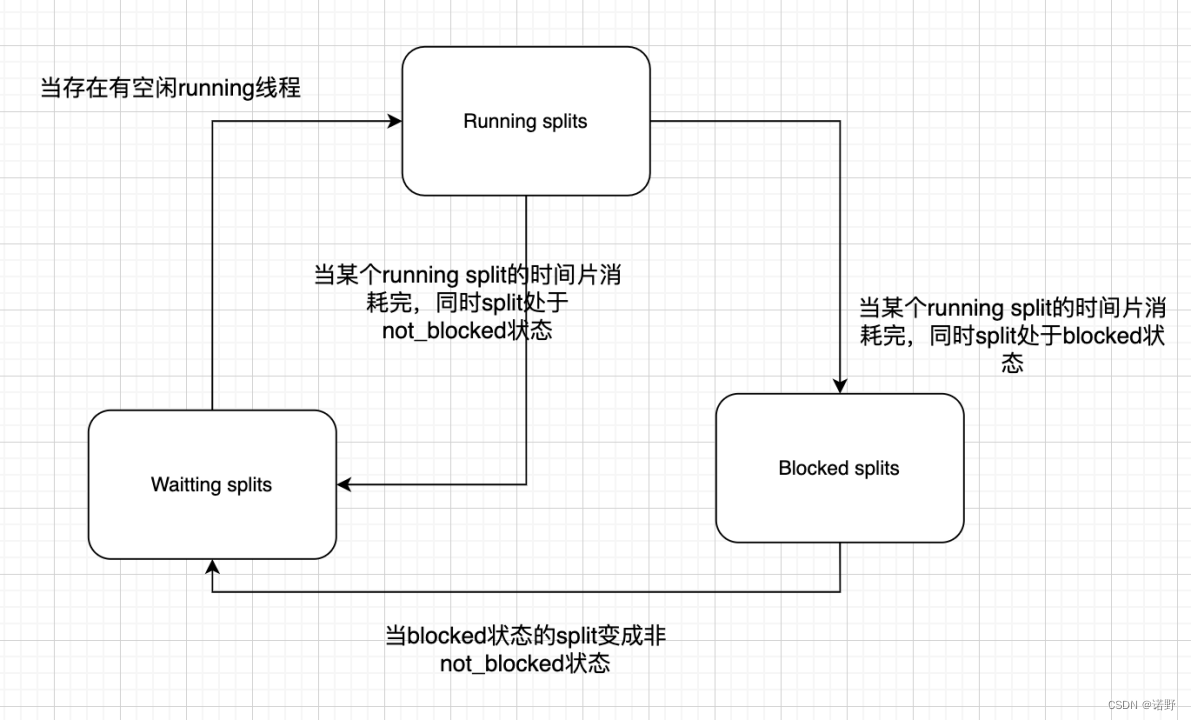
再说一下worker内部的task执行模型,首先worker基于task.concurrency来确定执行task的工作线程数。
- 当新的task请求过来会先进入waitting队列(严谨的说是driverRunner,这里假设等价于task),等待被执行。
- 当worker存在空闲的running线程,会从Waitting队列拿一个task来运行,并将task放入Running队列。
- running线程每次分配1s的时间片来执行,当时间片结束后判断task状态,如果是完成状态,则task结束;如果未完成状态同时是blocked状态,放入Blocked队列;如果不是blocked状态,则重新放入Waitting队列。
- 当Blocked队列的某些task状态变成了non-blcoked状态,则再放回Waitting队列。
Pipeline Execution
Pipeline调度执行模型是最初的执行模型,通过Pipeline这个名字就可以大致猜测出上下游stage之间的task是相互连接的(虚拟的),即上下游stage的task是同时运行(run all at once),数据通过exchange这个管道传递。这个执行模型跟流式计算Flink的一致,所以这种执行模型也可以被看成stream way。
这里通过一个案例来来描述一下pipeline调度执行模型的细节。以下的SQL最终会生成两个stage,stage 1 主要是Table scan的算子;stage 0 主要是Aggregate算子。
select d_year, count(1) as c from date_dim group by d_year;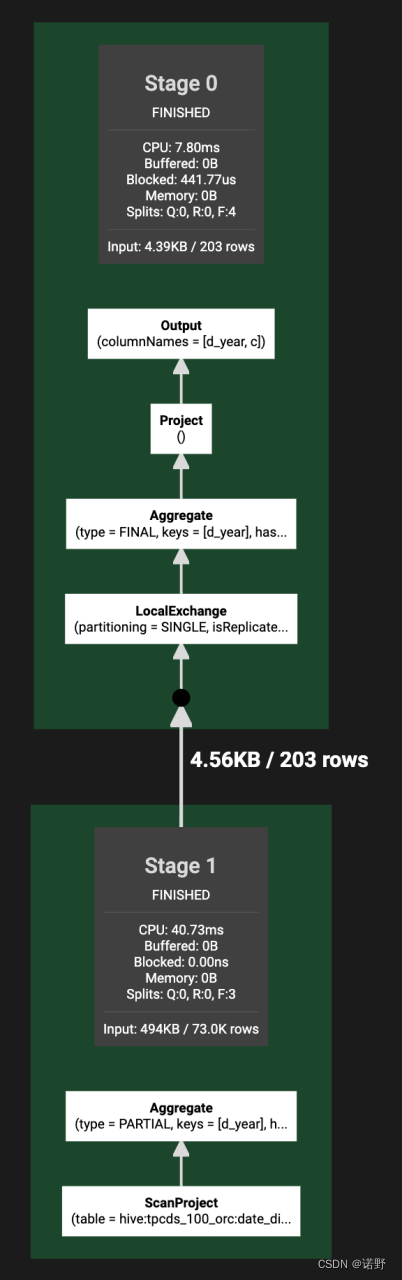
假设现在有一个trino集群只有一个woker实例,同时task.concurrency为1。
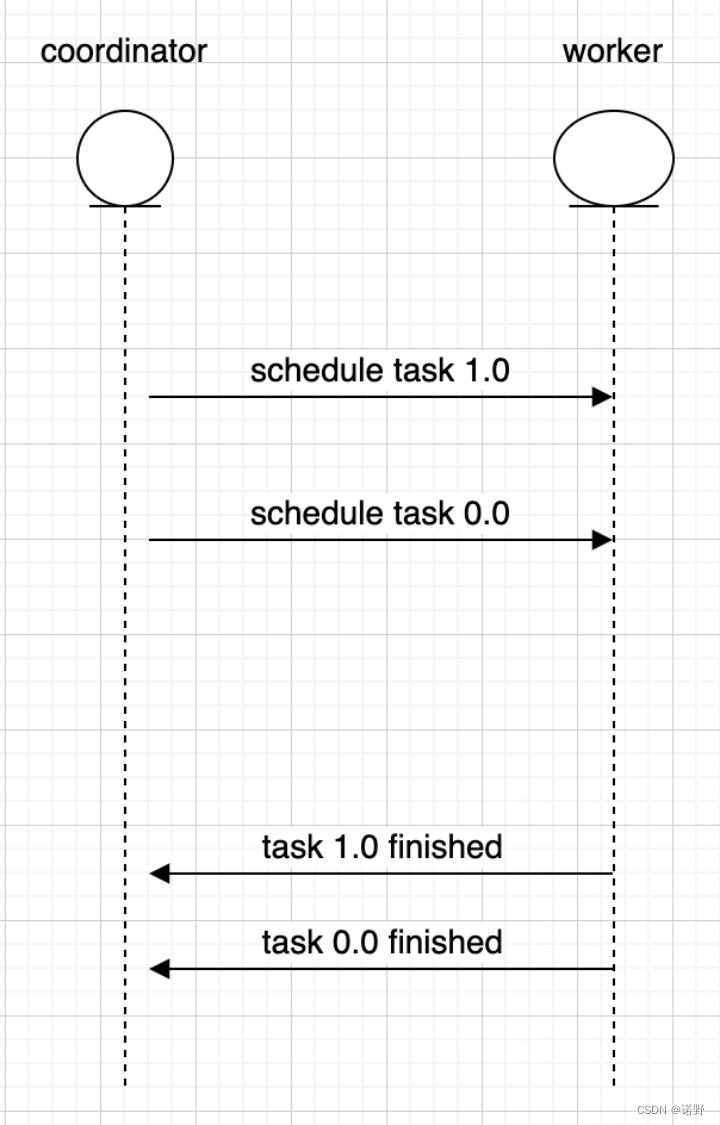
这种调度执行模型的好处是显而易见的:由于下游的stage只要有数据就可以先处理,而不需要等待上游stage的task全部处理完再启动,sql执行时间会相对快一些;同时即使数据没有全部处理完,客户端也可以拿到部分数据进行展示,给用户感觉响应比较快的体验。
当然相应的坏处也有不少:
- 由于worker需要同时处理多个stage的task,内存资源上的压力也会更加大,task OOM失败率也就更大。
- 无法做task的重试,只要一个task失败,整个query就重新执行。(想一下flink是怎么做,flink是从上一个checkpoint开始重新计算,trino没有这个机制就只能从开头重新执行。)
Fault-tolerant Execution
Fault-tolerant调度执行模型是本次Tardigrade项目新增的一个调度模型,不同于流式的Pipeline调度执行模型,它是一个批处理式的调度执行模型。调度执行模型的逻辑基本和spark/hive等批处理引擎的调度模型一致。
在Fault-tolerant调度执行模型下,stage的调度会按照dag依赖关系来调度,即下游stage是在依赖的上游stage没有完成前是不会被调度。我们还是以上面的query例子来说明:stage 1是DAG最上游的stage,先被调度;目前stage 1只有一个task 1.0,当task 1.0被调度执行完成了后,stage 1就算完成了,这个时候再调度stage 0的task;当stage 0的task完成后,整个query就完成了。
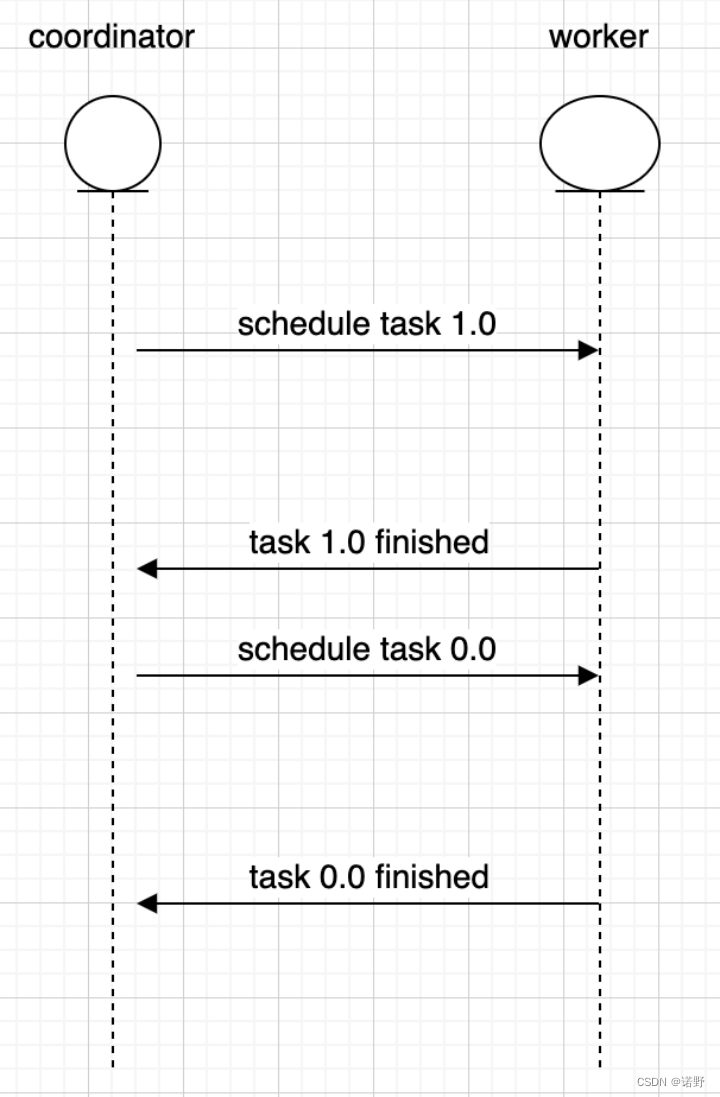
在Pipeline调度执行模型,stage之间的task通过exchange buffer(默认大小为25MB)来传递数据,当下游stage task处理慢了,exchange buffer满了会对上游的task进行反压,从而避免exchange消耗太多的内存;但是在Fault-tolerant模型下,如果还是使用内存exchange buffer,那么数据大的情况下,势必exchange数据将内存撑爆,所以这就引入了基于磁盘存储的exchangeStorage用于shuffle数据的持久化。
另外,为了支持在Fault-tolerant模型下具备task级别的重试,对task需要有新的约束,比如确定性(deterministic)和原子性(atomic)。这块下面会更详细的解释和说明。
Exchange持久化
Direct Exchange
在Pipeline调度执行模型使用direct exchange来传输shuffle数据,由于上下游之间stage的task同时运行,下游stage的task直接通过DirectExchangeClient远程调用(http接口)来拉取上游产生的exchange数据。产生exchange数据的上游task为exchange sink端,而消费exchange数据的下游task为exchange source端。两边task各自独立运行,从而使exchange数据一边被不停地生产的同时一边被不停地消费。
显然这种模式下,exchange数据也只能被消费一次,task失败重启没办法读取之前消费过的数据,所以也就做不了task级别重试。
Exchange Storage
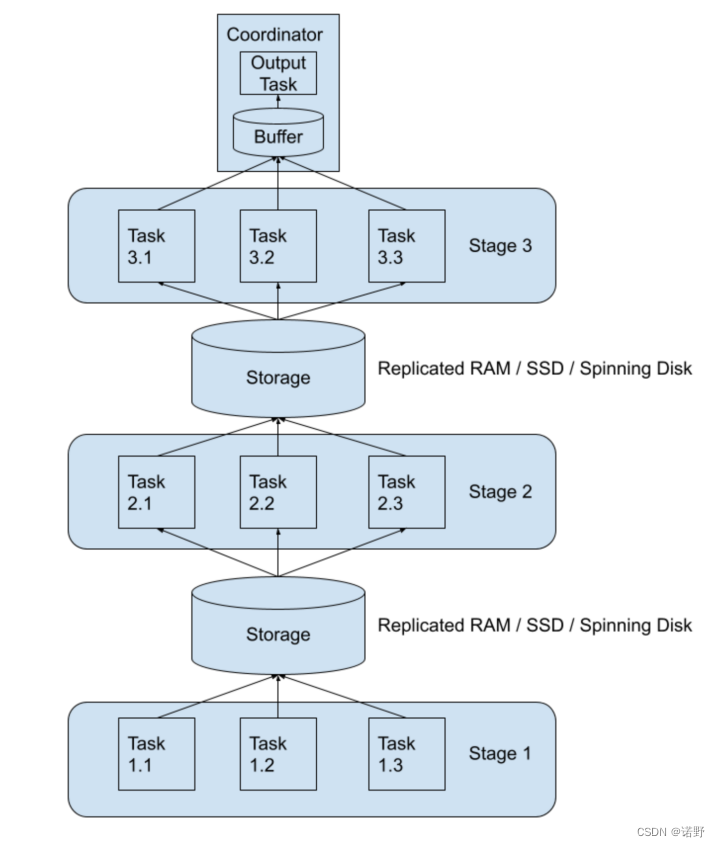
在Fault-tolerant模型下,我们需要使用Exchange Storage来临时存储exchange中间shuffle数据,一般来说Exchange Storage是选择磁盘存储的分布式存储(存储空间比较大),shuffle数据一直存储到query结束才删除,所以shuffle数据可以被多次重复消费,这为task重试提供了前置条件。
目前社区针对Exchange Storage机制实现了以下几种存储实现:
- S3-compatible storage system
- Azure Blob Storage
- Google Cloud Storage
- Local filesystem storage
我们在此基础上实现了Hdfs filesystem storage来满足在hdfs的场景。不过Local filesystem storage只适用于单机模式,无法作为生产级的解决方案,所以当前Fault-tolerant模型还是需要依赖一个分布式的存储系统作为exchange storage才能工作。
Task约束
在原来Pipeline调度执行模型下,不需要考虑task重试或者同一个分区的多个task实例同时执行的情况,所以task比较简单,也没有太多约束。当在Fault-tolerant模型,为了保证最终数据结果的正确性,需要对task做一些逻辑实现上的约束,这主要体现在task的确定性、可重启性和原子性。
确定性(Deterministic)
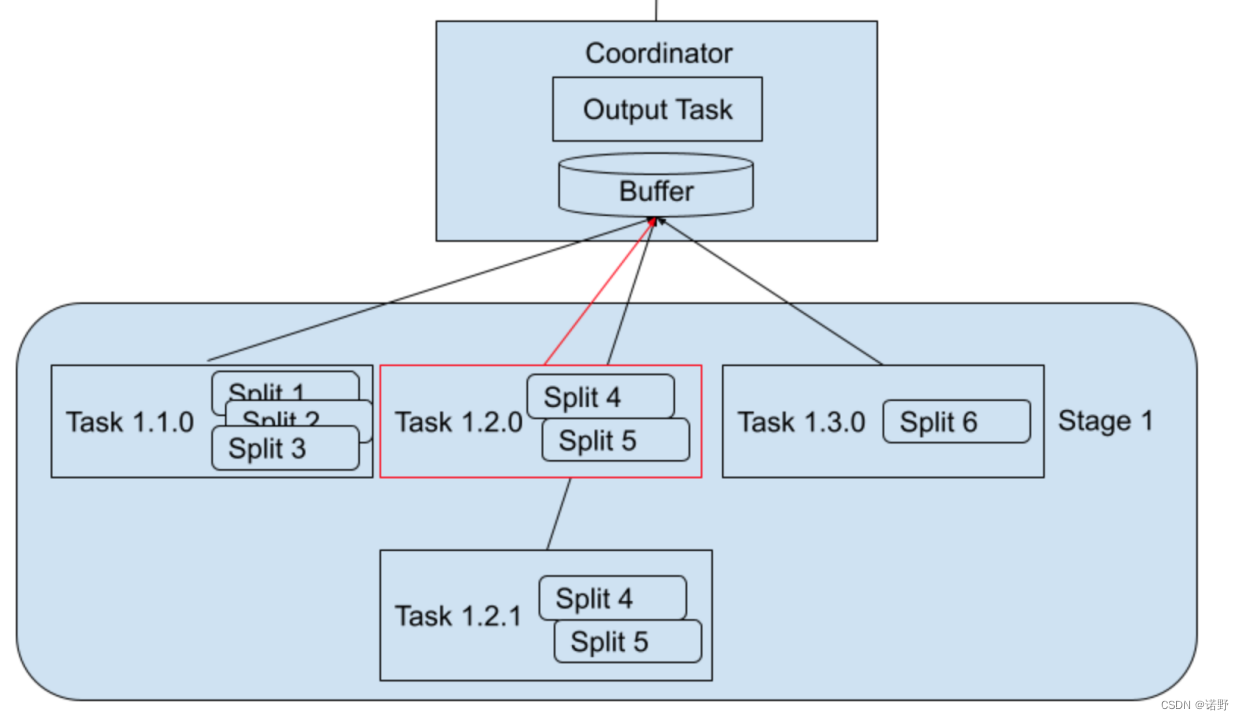
task的确定性指是每一个task实例的input split集合需要被确定下来的。在原来Pipeline调度执行模型,input spilt是随机地分配给各个task实例,input split只会被处理一次,所以没什么问题;但这对于Fault-tolerant调度执行模型,一个partition的task可能存在多个attempt实例,每一个attempt实例只有保证相同的输入才能保证相同的输出结果。
比如下面案例里中:处理split 4和 split 5的task 1.2.0 failed,那么新产生的第二个task attempt (task 1.2.1)也必须只能处理split 4和 split 5的数据,才能保证最终stage 1的输出结果是正确的。
可重启性(Restartable)
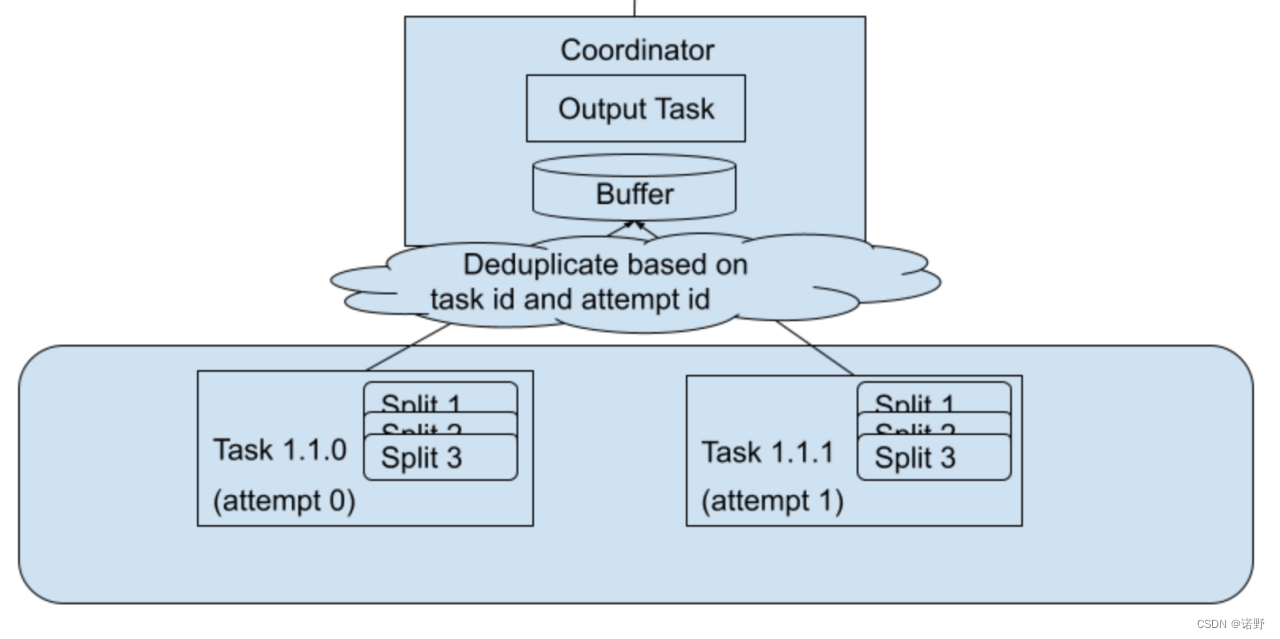
task的可重启性指的是task调度器发现某个task attempt为“fault”状态,那么就可以重新启动一个新的task attempt实例来执行。这里需要考虑被认为“fault”状态的上一个attempt实例可能还在运行,因为被认为“fault”可能是因为worker超时未响应task的运行状况。所以在同一个task多个attempt实例并行运行是有可能的,需要保证不会发生冲突的情况,同时最终只需要取一个attempt成功实例的结果,而忽略其他attempt实例。
原子性(Atomic)
task的原子性指的是在多次task attempt实例的情况下,需要保证输出的最终结果没有什么不正确的副作用。一个query的最后一个stage一般是写数据到某个表或者返回客户端一个select结果。
对应一个select查询的query的最终结果也需要写到exchange storage,然后等最后的stage都完成结束了,客户端才能拿到结果并返回(区别于之前Pipeline调度执行模型可以提早返回结果)。
而对应insert操作,需要各个connector来保证写的原子性,如果无法保证,Fault-tolerant模式的写操作就无法使用。比如下面是Hive connector写的场景,task 1.2 产生了2个task attempt实例,在finishInsert没有执行table commit之前,stage 1产生的数据文件必须是不可见的;产生的数据文件先是在tmp临时目录,同一个task的多次attempt只取第一个成功attempt的结果,在finishInsert中将最终数据移到表的正式目录;这样的流程就保证写过程的原子性。所以其他connector也需要类似的流程去保证写的原子性。
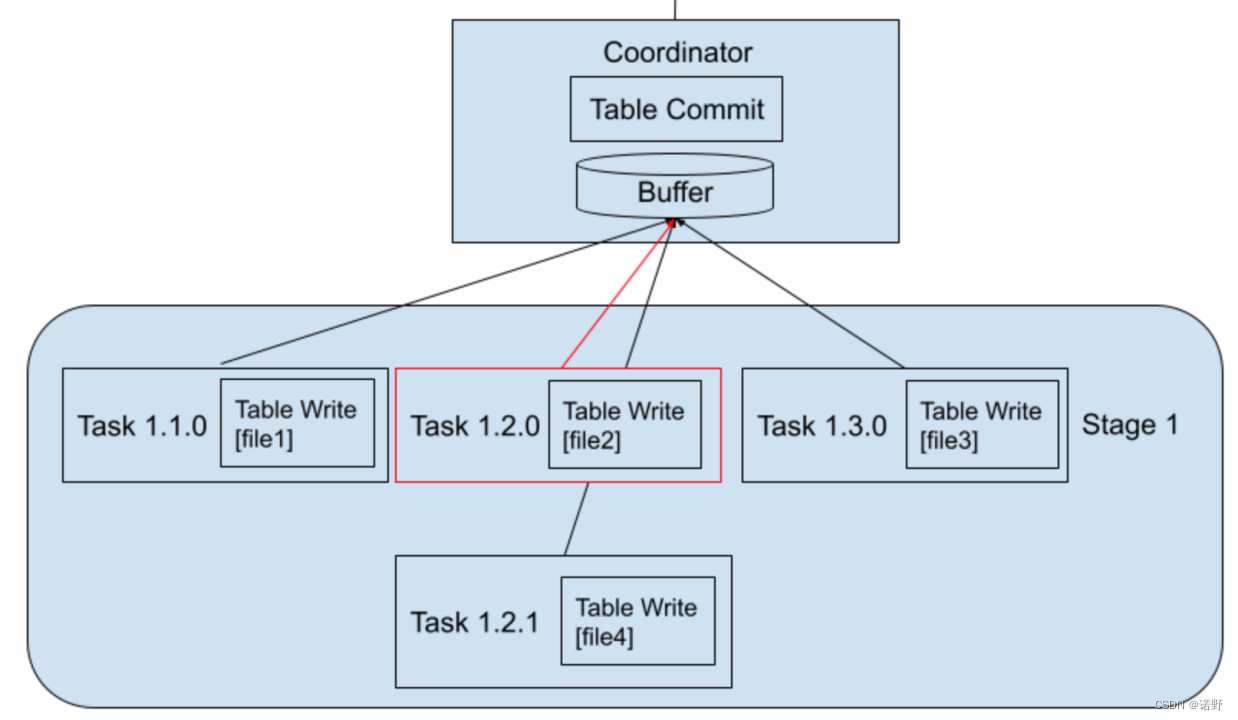
目前Fault-tolerant模型支持写操作原子性的connector有这么几个(trino 401版本):Hive、Iceberg、Delta Lake、MySQL、PostgreSQL和SQL Server。
下一步改进计划
社区的Tardigrade项目初步让trino具备了批处理的能力,但需要不停的迭代才能达到一个相对可靠稳定的版本。 当下我们对Tardigrade也做了部分的优化和增强,比如exchange shuffle压缩优化、增加hdfs exchange storage以及task sizing的优化等。
额外的,我们构思了一下批处理能力的后续改进计划。
自适应query优化
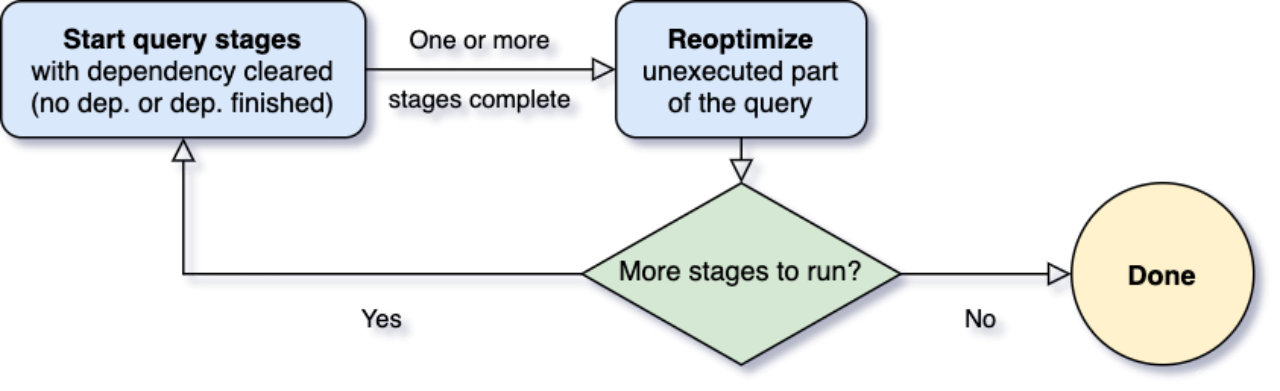
可能大家听说过spark 3.0的Adaptive Query Execution功能,spark AQE功能描述的是当spark每一个stage完成之后,可以基于完成stage的shuffle数据情况,对剩余的执行计划进行重新优化。(AQE介绍:Spark 3.0 - AQE浅析 (Adaptive Query Execution)_spark3 aqe_Deegue的博客-CSDN博客)
本次trino这个功能计划也是为了实现类似runtime的optimize能力。这个功能在Pipeline调度模式下是无法做到的,因为所有stage在开始的时候就被调度起来,最终物理执行计划在最开始的时候就被确定了。由于在optimize阶段往往只有获取到表的统计信息,所以第一层stage往往评估的比较准确,后续的stage就比较难评估准确了。
但对于Fault-tolerant调度模式,下游stage在调度前就可以感知到上stage真实产生了多少数据,那么就可以对还没有开始的stage部分进行重新optimize优化。
总结一下自适应query优化的几个方向:
- 自适应task resizing。比如上游stage设定的hash partition数比较大,但是实际数据量产生比较小,那就可以将多个小的partition数据合成一个task来处理,减少task数量(最终减少小文件数)
- 自适应join类型选择。比如在运行过程中,发现需要join的sub query产生的数据比较少,那么就可以从hash partition join切换成broadcast join。
- 自适应倾斜处理。当发现shuffle数据中某个partition的数据比其他的大很多,那么就将这个partition拆分出多个task来并行处理,从而缩短query的运行时间。(目前这个优化适合部分join类型,比如inner join和left join等)。
- 自适应join reordering。比如发现某些表经过几层stage计算后,表变的比较小,就可以考虑重新优化join顺序。
- 自适应partitioning优化。比如优化接下来stage的partition数量,从而减少小的shuffle文件数和task数。
目前spark已经实现了a、b和c。
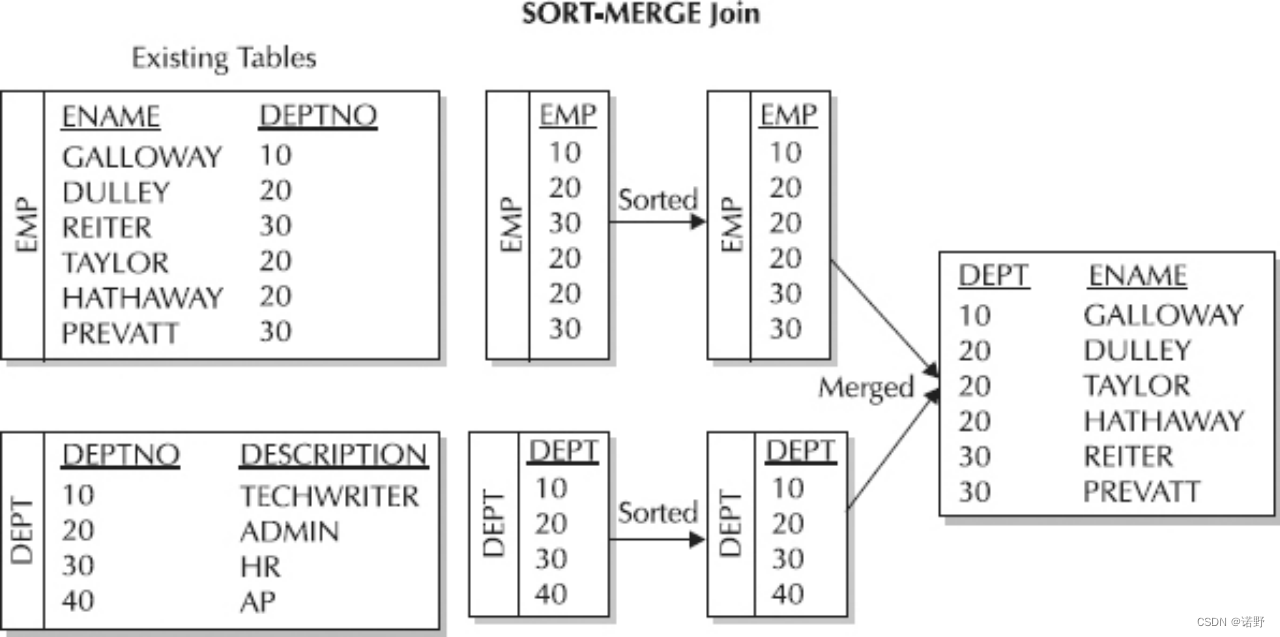
Sort Merge Join
目前trino支持broadcast join和hash join两种join实现。broadcast join适合于大表与小表的Join,当join端build side的数据量比较小的情况,用broadcast小表来换取避免probe端大表的hash exchange,所以性能上最好。而hash join适用于大表与大表的join,两表都需要经过hash exchange,同时probe端每一个partition数据处理需要将build side端对应的分区数据全部加载到内存来计算;所以表如果比较大的情况就需要增加partition来避免内存OOM,但是如果partition数据存在倾斜,就比较难避免OOM问题了。
Sort merge join是目前批处理spark主流的处理大表之间join的实现方式,虽然性能上差一些,但对内存需求少,可以提供更稳定可靠的join实现方式。
Embedded Shuffle Service
当下使用trino的Fault-tolerant模型的批处理能力,就需要配置一个exchange storage来支持。目前支持s3协议的对象存储和hdfs存储作为exchange storage,如果仅仅是为了开启trino批处理能力而需要部署一个新的分布式存储显得有点过重。
对比于spark引擎,它的exchange shuffle并不依赖于分布式存储,而是内部实现了shuffle service,对shuffle数据基于本地磁盘的local write,然后依赖内部的shuffle service提供remote read能力。目前的trino使用分布式存储,相当于将分布式存储作为了一个“shuffle service”来使用,所以如果trino可以实现一个内嵌的shuffle service,就可以不需要任何分布式存储,部署时就可以提供一个比较轻量的方式。
其他
推测执行(Speculative execution)
在hadoop mapreduce计算框架中实现了一套推测执行(Speculative Execution)机制,它根据一定的法则推测出“拖后腿”的任务,并为这样的任务启动一个备份任务,让该任务与原始任务同时处理同一份数据,并最终选用最先成功运行完成任务的计算结果作为最终结果。这样的机制可以避免整个query因为某个task拖慢了整体的运行时间。在spark计算框架也有类似的实现。
Node黑名单
在Fault-tolerant执行框架下具备task retry的能力,如果task第一次attempt在某个worker实例失败了,第二次attempt就可以考虑屏蔽之前的worker节点(task失败很有可能是worker实例或者节点有异常问题),从而提高task的成功概率,这就是node黑名单机制。

















 924
924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









