









Alluxio 简介
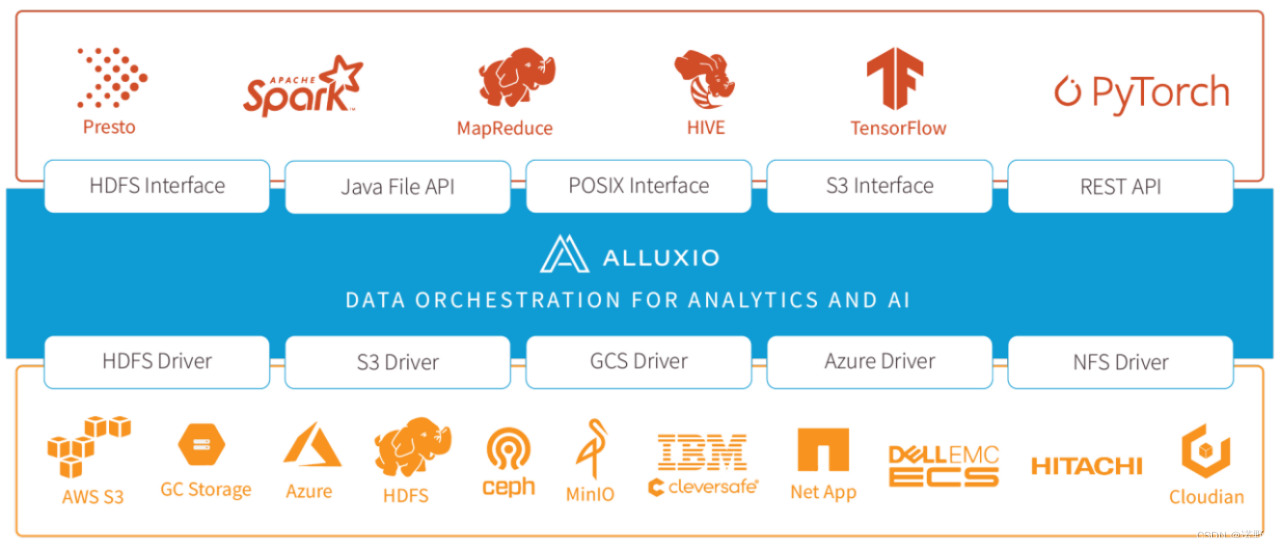
Alluxio,以内存为中心的分布式虚拟存储系统。是大数据和机器学习生态系统中的新数据访问层。 Alluxio在上层计算框架和底层存储系统之间架起了桥梁,应用层只需要访问Alluxio即可以访问底层对接了的任意存储系统的数据。
对于用户应用程序和计算框架(无论是哪种计算框架),Alluxio 提供快速存储访问,并促进应用程序之间的数据共享和本地化。 当数据在本地时,Alluxio 可以以内存速度提供数据;当数据在 Alluxio集群中时,可以以计算集群网络的速度提供数据。
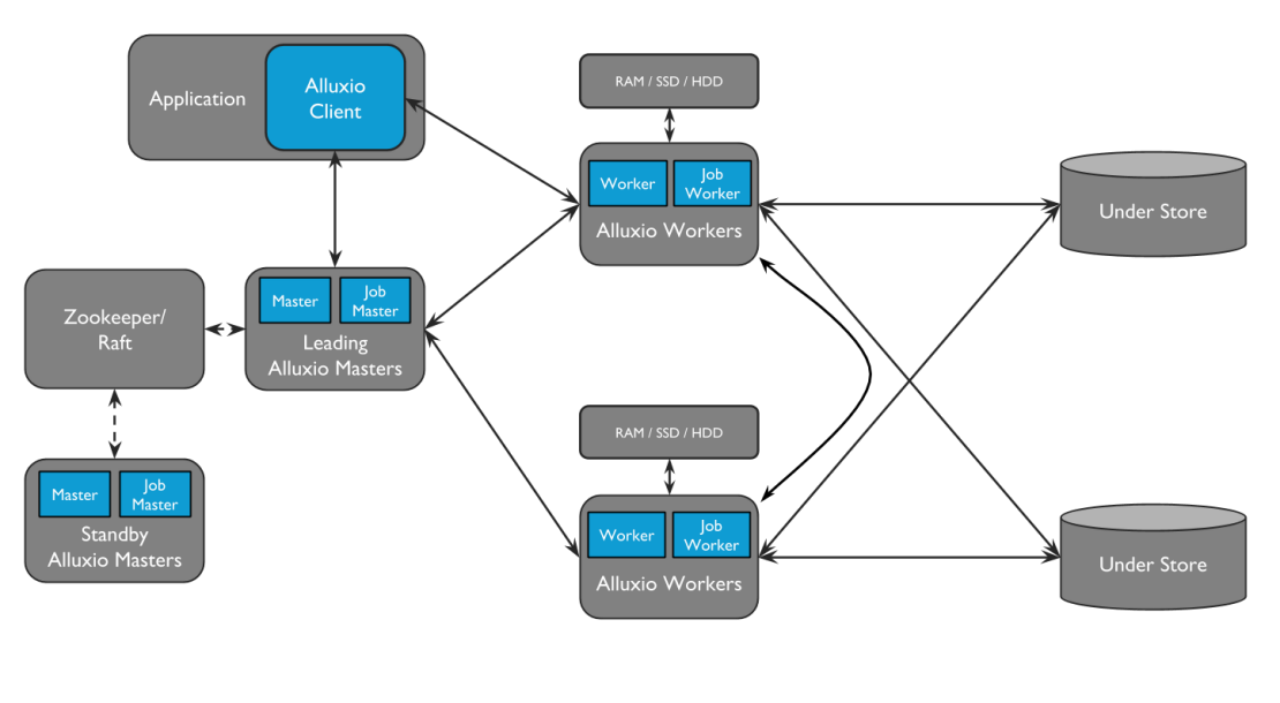
Master和Worker组成了Alluxio集群,其中master有 job master和Alluxio master ,Worker有job worker和Alluxio worker。
优点:
- 分布式内存文件系统,易扩展
- 提供了UFS接口,底层存储对上层计算引擎透明,适合多种计算引擎共同访问一种或者多种存储系统
- 提供了类hdfs命令及POSIX接口,用户可以像操作本地文件一样操作Alluxio文件
缺点:
- 体积大,对于Trino来讲,部署时需要额外增加一个组件,集群维护开销增加,集群可靠性会将降低
- 不适合iceberg表格式(iceberg location 一旦固定就无法修改[存量数据的])
- 需要建表时将表或者schema存储到alluxio中才可以使用,对于已有的表不支持使用缓存
- 资源消耗大,如果想达到更高的提速对本地机器配置要求高,比如内存,磁盘和集群内部网络
- 缓存本地访问率低,性能没有亮点
那么有没有一种轻量级嵌入到计算引擎的cache层呢?答案:Alluxio和Meta共同开发了Local Data Cache。
Local Data Cache 技术方案
如何使用Alluxio分布式缓存方案,那么就需要部署一套Alluxio集群。但是如果是构建Alluxio local data cache方案只需要alluxio-shaded-client.jar一个jar包就可以啦。对于Presto/Trino来说,在性能、易使用、易维护方面都比Alluxio集群方案更加优秀。
而trino集成Alluxio Local data cache方案的主要核心点在于:1、将数据缓存在计算Node的本地ssd中,不考虑集群节点间数据共享;2、依赖于soft affinity schedule,增加缓存命中率,尽量本地node处理本地的数据。
整体架构
首先,我们新增了trino-cache的模块, iceberg 与 trino-cache 之间的交互流程(以iceberg connector为例)大概是这样的:
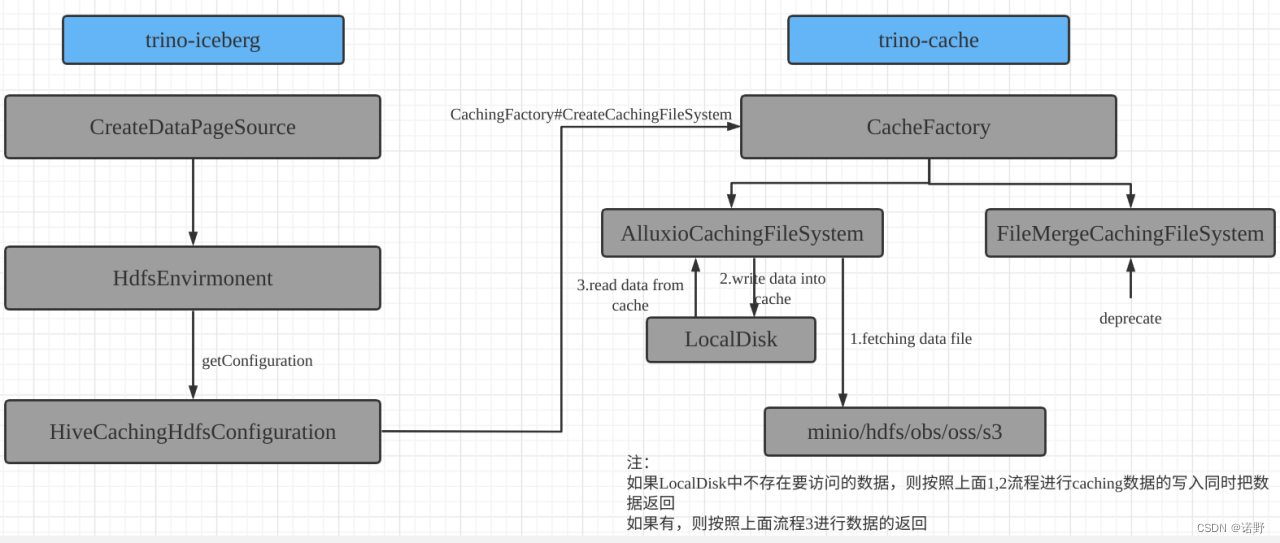 图左边部分是iceberg操作调用的地方,主要是访问文件系统时使用扩展的文件系统(ExtendedFileSystem)创建的代理层,根据cache开启和关闭在缓存系统和原始文件系统中进行切换;具体的缓存管理、数据写入、淘汰等维护管理任务均交给alluxio-client去处理;为了提高缓存的命中率,又引入了Affinity Schedule策略。
图左边部分是iceberg操作调用的地方,主要是访问文件系统时使用扩展的文件系统(ExtendedFileSystem)创建的代理层,根据cache开启和关闭在缓存系统和原始文件系统中进行切换;具体的缓存管理、数据写入、淘汰等维护管理任务均交给alluxio-client去处理;为了提高缓存的命中率,又引入了Affinity Schedule策略。
文件系统代理层
CachingFileSystem 在这里是文件系统的代理层,如果cache关闭,则直接返回原始文件系统;如果打开则使用缓存文件系统,底层缓存引擎由AlluxioCachingFileSystem实现(使用Alluxio的本地缓存实现Cache数据的写入、读取和过期维护管理)。
那么如何兼容原来的文件系统访问并实现缓存的目的呢?解决方案就是把Hadoop的FileSystem扩展成ExtendedFileSystem,并统一使用这个扩展的接口。
public abstract class ExtendedFileSystem
extends FileSystem
{
public FSDataInputStream openFile(Path path, HiveFileContext hiveFileContext)
throws Exception
{
return open(path);
}
...
}扩展最主要的目的是加入了 openFile 的方法,跟普通的 FileSystem#openFile 不同的是,这个方法添加了 HiveFileContext 参数。他并不是Hadoop FileSystem标准API的一部分,添加这个参数是为了传递当前要读取的文件是否可以被缓存的上下文信息。如果它是可以被缓存的,那么引擎会走缓存的代码路径,否则的话就走普通的代码路径。HiveFileContext构造方法如下:
public HiveFileContext(boolean cacheable, CacheQuota cacheQuota, Optional<ExtraHiveFileInfo<?>> extraFileInfo, Optional<Long> fileSize, long modificationTime, boolean verboseRuntimeStatsEnabled)
{
this.cacheable = cacheable;
this.cacheQuota = requireNonNull(cacheQuota, "cacheQuota is null");
this.extraFileInfo = requireNonNull(extraFileInfo, "extraFileInfo is null");
this.fileSize = requireNonNull(fileSize, "fileSize is null");
this.modificationTime = modificationTime;
this.verboseRuntimeStatsEnabled = verboseRuntimeStatsEnabled;
}在Icebeg connector中如何使用这个HiveFileContext呢?
#IcebergPageSourceProvider.java
private static ReaderPageSource createOrcPageSource(
HdfsEnvironment hdfsEnvironment,
ConnectorIdentity identity,
Configuration configuration,
Path path,
long start,
long length,
long fileSize,
List<IcebergColumnHandle> columns,
TupleDomain<IcebergColumnHandle> effectivePredicate,
OrcReaderOptions options,
FileFormatDataSourceStats stats,
TypeManager typeManager,
Optional<NameMapping> nameMapping)
{
OrcDataSource orcDataSource = null;
try {
ExtendedFileSystem fileSystem = hdfsEnvironment.getFileSystem(identity, path, configuration);
FileStatus fileStatus = fileSystem.getFileStatus(path);
fileSize = fileStatus.getLen();
long modificationTime = fileStatus.getModificationTime();
#创建HiveFileContext,并根据CacheConfig的开关标记为true/false
HiveFileContext hiveFileContext = new HiveFileContext(cacheConfig.isCachingEnabled(), NO_CACHE_CONSTRAINTS,
Optional.empty(), Optional.of(fileSize), modificationTime, false);
FSDataInputStream inputStream = hdfsEnvironment.doAs(identity, () -> fileSystem.openFile(path, hiveFileContext));
...
}
完整的访问调用路径如下:
NodeScheduler
-> createPageSource
-> IcebergPageSourceProvider
-> createDataPageSource
-> createOrcPageSource
-> hdfsEnvironment.doAs(identity, () -> fileSystem.openFile(path, hiveFileContext));
最后在 AlluxioCachingFileSystem 里面, 会使用通过 HiveFileContext 传递过来的缓存与否的信息判断是否走缓存逻辑:
if (hiveFileContext.isCacheable()) {
return cachingFileSystem.openFile(path, hiveFileContext);
}
return dataTier.openFile(path, hiveFileContext);如果可以被缓存,走缓存文件系统;否则直接走底层的文件系统。
配置及使用
在trino etc/catalog/iceberg.properties里面增加如下参数:
cache.enabled=true
cache.base-directory=file:///data/alluxio3,file:///data/alluxio4
cache.alluxio.max-cache-size=350GB,100GB
#缓存的数据文件在本地的存储形式
cache.alluxio.store-type=LOCAL #可选值LOCAL/ROCKS/MEM,默认值是LOCAL
#亲和性类别,可选值SOFT_AFFINITY/NO_PREFERENCE,默认值是SOFT_AFFINITY
iceberg.node-selection-strategy=SOFT_AFFINITY
cache.alluxio.eviction-policy=LRU #可选值LRU/LFU/FIFO/Unevictable,默认值是LRU在trino etc/config.properties或者etc/node.properties里面增加如下参数:
#节点调度策略,可选值UNIFORM/TOPOLOGY/SIMPLE,默认值UNIFORM
node-scheduler.policy=SIMPLE #当开启local data cache特性时,该值必须为SIMPLE
#亲和性hash策略,可选值MODULAR_HASHING/CONSISTENT_HASHING,默认值CONSISTENT_HASHING
node-scheduler.node-selection-hash-strategy=MODULAR_HASHING
#当使用CONSISTENT_HASHING时,虚拟节点的个数 默认100
node-scheduler.consistent-hashing-min-virtual-node-count=1000Cache的淘汰策略:
public enum EvictionPolicy
{
FIFO("alluxio.client.file.cache.evictor.FIFOCacheEvictor"),
LFU("alluxio.client.file.cache.evictor.LFUCacheEvictor"),
LRU("alluxio.client.file.cache.evictor.LRUCacheEvictor"),
UNEVICTABLE("alluxio.client.file.cache.evictor.UnevictableCacheEvictor"),
/**/;
}查看缓存的命中率
在cn和worker节点上jvm.config中增加如下配置 -Dalluxio.user.app.id=trino
//然后执行以下SQL来查看缓存命中率
show tables from jmx.current like '%hitrate%'
select * from jmx.current."org.alluxio:name=client.cachehitrate.trino,type=gauges";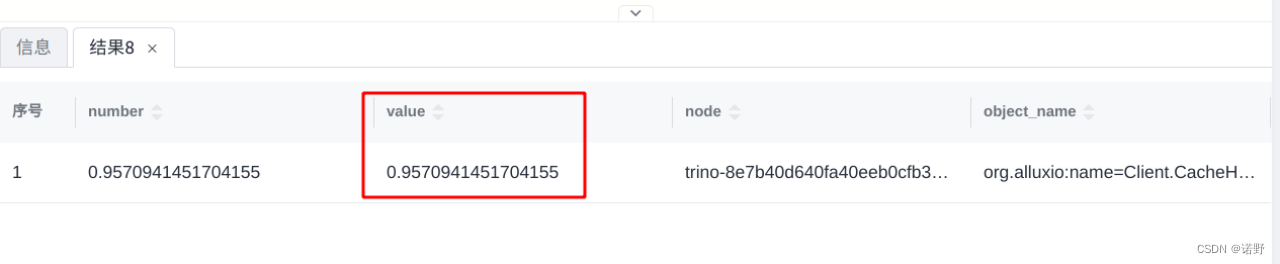
Shadow Cache
缓存的容量与缓存命中率对于性能的影响有多少?需要一些信息来判断当一个集群被缓存大小所限制时,扩大缓存容量是否能够帮助集群提高缓存命中率以及请求的响应速度。同时这些信息也能够对探索缓存算法潜在的优化策略提供一定的帮助。
总结下就是两个关注点:
- 运行的应用程序需要多大的缓存?
- 缓存的命中率提升的极限在哪里?
Alluxio提出Shadow cache:用于追踪工作集大小和缓存命中率的轻量级Alluxio组件。首先为解决第一个问题,Shadow cache会告知管理者在过去24小时之内缓存一共接受到了多少互不重复的bytes,依此可以估计出未来缓存的需求量。此外为解决另一个问题,Shadow cache将会告知管理者在缓存能够将过去24h的所有请求全部保留的情况下请求命中缓存的数量,也就是说,未命中的都是从未出现过的数据,而这就意味着得到了缓存最大命中率。
具体实现参见链接
Meta(Facebook): 基于Alluxio Shadow Cache优化Presto架构决策 - 知乎
新增Affinity Schedule
为了打造一个性能良好的缓存,不断提高缓存命中率,在Trino中引入了亲和性(Affinity)的task分配机制。也就说对于同一个文件的读取请求,我们应该尽量把它分配给相同的Worker来进行处理,这样才能使得我们第一次放入缓存的数据会被后续的读取请求利用上。
Affinity的类型NodeSelectionStrategy的值有三个:
- HARD_AFFINITY: Split必须分配给指定的节点(getPreferedNodes())
- SOFT_AFFINITY: Split“最好”分配给指定的节点,如果该节点非常繁忙也可以分配给其它的节点。
- NO_PREFERENCE: Scheduler可以把Split分配给任意节点而不影响性能。
注:Split在Trino中描述的是当前Worker从底层存储读取和处理的数据段,它也是并行执行和任务分配的单元。
PreferedNode计算
目前我们针对SOFT AFFINITY实现了两种算法:ModularHashing和ConsistentHashing。下面通过代码分别来介绍相关算法逻辑。
ModularHashingNodeProvider
#IcebergSplit.java
@Override
public List<HostAddress> getPreferredNodes(NodeProvider nodeProvider)
{
if (getNodeSelectionStrategy() == SOFT_AFFINITY) {
#For SOFT AFFINITY
return nodeProvider.get(path, 2);
}
#HARD AFFINITY,不支持Iceberg connector,在构建split时无法获取到节点ip
return addresses; #该值永远为0
}
#ModularHashingNodeProvider.java
@Override
public List<HostAddress> get(String identifier, int count)
{
int size = sortedCandidates.size();#当前节点总数量
int mod = identifier.hashCode() % size;#Split path hashCode%节点总数
int position = mod < 0 ? mod + size : mod;#在集群中选择一个位置
List<HostAddress> chosenCandidates = new ArrayList<>();
if (count > size) {
#单节点情况处理
count = size;
}
for (int i = 0; i < count && i < sortedCandidates.size(); i++) {
#生成候选节点列表
chosenCandidates.add(sortedCandidates.get((position + i) % size).getHostAndPort());
}
return unmodifiableList(chosenCandidates);
}可以看出,算法比较简单,就是hash+mod 的方式。如果集群中某个节点失联或者Down掉了,Split到worker节点的映射将全部需要重新分配,导致缓存命中率大幅下降。如果出现问题的worker稍后重新上线,也需要再次重新分配。为了解决这类场景,引入了一致性哈希算法。
ConsistentHashingNodeProvider
#IcebergSplit.java
@Override
public List<HostAddress> getPreferredNodes(NodeProvider nodeProvider)
{
if (getNodeSelectionStrategy() == SOFT_AFFINITY) {
#For SOFT AFFINITY
return nodeProvider.get(path, 2);
}
##HARD AFFINITY,不支持Iceberg connector,在构建split时无法获取到节点ip
return addresses; #该值永远为0
}
#ConsistentHashingNodeProvider.java
#生成虚拟节点和物理节点的映射,并存储到TreeMap中
static ConsistentHashingNodeProvider create(Collection<InternalNode> nodes, int weight)
{
NavigableMap<Integer, InternalNode> activeNodesByConsistentHashing = new TreeMap<>();
for (InternalNode node : nodes) {
for (int i = 0; i < weight; i++) {
activeNodesByConsistentHashing.put(murmur3_32_fixed().hashString(format("%s%d", node.getNodeIdentifier(), i), StringUtils.UTF_8).asInt(), node);
}
}
return new ConsistentHashingNodeProvider(activeNodesByConsistentHashing, nodes.size());
}
@Override
public List<HostAddress> get(String key, int count)
{
if (count > nodeCount) {
count = nodeCount;
}
ImmutableList.Builder<HostAddress> nodes = ImmutableList.builder();
Set<HostAddress> unique = new HashSet<>();
int hashKey = HASH_FUNCTION.hashString(format("%s", key), StringUtils.UTF_8).asInt();
#顺时针取第一个
Map.Entry<Integer, InternalNode> entry = candidates.ceilingEntry(hashKey);
HostAddress candidate;
SortedMap<Integer, InternalNode> nextEntries;
#如果找到,获取到对应节点信息
if (entry != null) {
candidate = entry.getValue().getHostAndPort();
#并顺时针获取下一个节点对信息
nextEntries = candidates.tailMap(entry.getKey(), false);
}
else {
#没找到,取lowest key element的节点
candidate = candidates.firstEntry().getValue().getHostAndPort();
nextEntries = candidates.tailMap(candidates.firstKey(), false);
}
#加入到候选列表里
unique.add(candidate);
nodes.add(candidate);
#将剩余所有节点都加入候选列表里
while (unique.size() < count) {
for (Map.Entry<Integer, InternalNode> next : nextEntries.entrySet()) {
candidate = next.getValue().getHostAndPort();
if (!unique.contains(candidate)) {
unique.add(candidate);
nodes.add(candidate);
if (unique.size() == count) {
break;
}
}
}
nextEntries = candidates;
}
#返回候选列表
return nodes.build();
}当增加或删除节点时,一致性哈希可以使工作负载重新分配所产生的的影响降到最低。当集群的worker节点发生变化时,基于一致性哈希算法进行工作负载在worker节点间的分配,可以尽量降低对现有节点上缓存命中率的影响。因此,在集群规模按照工作负载的需要扩缩容的场景下,或者部署环境中的硬件设备不完全受控而导致worker节点可能随时被重新分配和调整的场景下,一致性哈希策略都会成为一种更好的选择。
性能测试
这里针对10T TPC-DS数据集来测试开启local data cache功能的性能对比。
机器实例:5个计算节点+3个存储节点
测试报告:
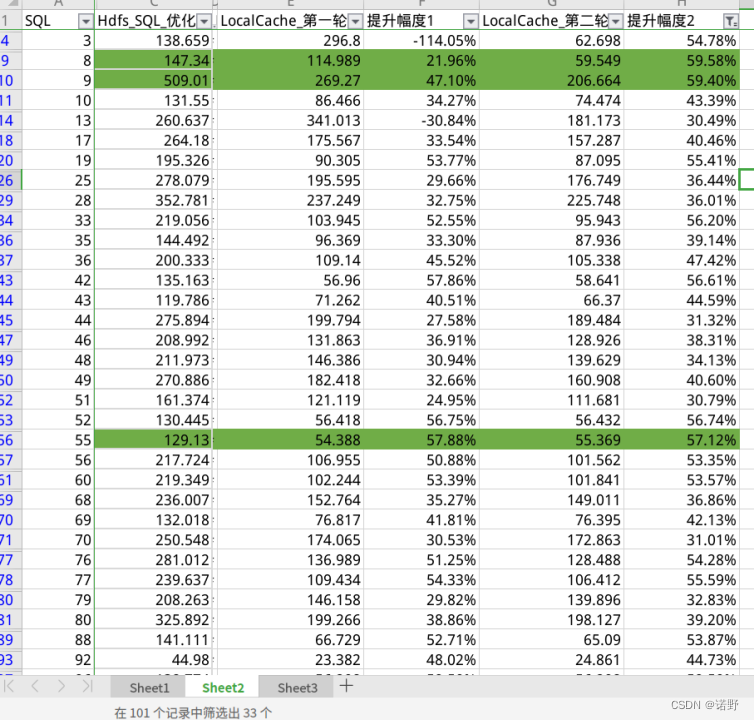
测试报告分析:
- 对于CPU 计算密集型的query, 像Q4/Q11/Q23/Q78提升不明显(个位数提升)。
- 对于IO密集型的query,其中14条SQL 提升超过50%,其中33条SQL 提升超过30%。
- cache命中率的指标通过Metrics监控来看,第一次执行cache命中率在77%,第二次执行在86% 。















 1380
1380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









