






问题背景
在对trino在小内存配置(jvm内存为5G)情况测试1TB tcpds数据集的稳定性,我们发现一个比较奇怪的现象,很多query会因为ScanFilterAndProjectOperator算子引发高频的OOM task失败。而尝试使用简单的测试query也会有同样的问题,而ScanFilterAndProjectOperator只是一个简单的table scan的操作,不应该有太大的内存消耗才对。
本文通过这个问题来分析根本原因以及相应的解决方案。
测试环境:
一个cn实例,jvm内存配置为5G。
coordinator的config.properties核心配置如下:
coordinator=true
node-scheduler.include-coordinator=true
memory.heap-headroom-per-node=2GB
query.max-memory-per-node=3GB
fault-tolerant-execution-target-task-input-size=1GB
fault-tolerant-execution-task-memory=1GB原因分析
以下是task失败的异常栈信息,从异常来看Parquet读数据不足内存而OOM。
2023-01-11T10:41:54.688+0800 ERROR SplitRunner-50-156 io.trino.execution.executor.TaskExecutor Error processing Split 20230111_024128_00000_kenex.4.2.0-26 {path=hdfs://k8s-master0:8020/user/hive/warehouse/tpcds_1000_iceberg.db/store_sales/data/00088-1272-253264cd-c5e6-4bc8-957d-3d5f5c184d7c-00001.parquet, start=4, length=34377745} (start = 3.013025069064342E9, wall = 3193 ms, cpu = 0 ms, wait = 8 ms, calls = 1)
java.lang.OutOfMemoryError: Java heap space
at io.trino.parquet.AbstractParquetDataSource$ReferenceCountedReader.read(AbstractParquetDataSource.java:285)
at io.trino.parquet.AbstractParquetDataSource$1.read(AbstractParquetDataSource.java:186)
at io.trino.parquet.reader.ParquetReader.allocateBlock(ParquetReader.java:486)
at io.trino.parquet.reader.ParquetReader.readPrimitive(ParquetReader.java:445)
at io.trino.parquet.reader.ParquetReader.readColumnChunk(ParquetReader.java:553)
at io.trino.parquet.reader.ParquetReader.readBlock(ParquetReader.java:536)
at io.trino.parquet.reader.ParquetReader.lambda$nextPage$3(ParquetReader.java:278)
at io.trino.parquet.reader.ParquetReader$$Lambda$4950/0x0000000802726660.readBlock(Unknown Source)
at io.trino.parquet.reader.ParquetBlockFactory$ParquetBlockLoader.load(ParquetBlockFactory.java:72)
at io.trino.spi.block.LazyBlock$LazyData.load(LazyBlock.java:407)
at io.trino.spi.block.LazyBlock$LazyData.getFullyLoadedBlock(LazyBlock.java:386)
at io.trino.spi.block.LazyBlock.getLoadedBlock(LazyBlock.java:293)
at io.trino.operator.project.DictionaryAwarePageProjection$DictionaryAwarePageProjectionWork.setupDictionaryBlockProjection(DictionaryAwarePageProjection.java:208)
at io.trino.operator.project.DictionaryAwarePageProjection$DictionaryAwarePageProjectionWork.lambda$getResult$0(DictionaryAwarePageProjection.java:196)
at io.trino.operator.project.DictionaryAwarePageProjection$DictionaryAwarePageProjectionWork$$Lambda$5133/0x00000008027751d0.load(Unknown Source)
at io.trino.spi.block.LazyBlock$LazyData.load(LazyBlock.java:407)
at io.trino.spi.block.LazyBlock$LazyData.getFullyLoadedBlock(LazyBlock.java:386)
at io.trino.spi.block.LazyBlock.getLoadedBlock(LazyBlock.java:293)
at io.trino.operator.project.PageProcessor$ProjectSelectedPositions.processBatch(PageProcessor.java:360)
at io.trino.operator.project.PageProcessor$ProjectSelectedPositions.process(PageProcessor.java:221)
at io.trino.operator.WorkProcessorUtils$ProcessWorkProcessor.process(WorkProcessorUtils.java:391)
at io.trino.operator.WorkProcessorUtils.lambda$flatten$7(WorkProcessorUtils.java:296)通过jmap dump下进程的堆内存,使用MAT来分析堆内存的使用情况。
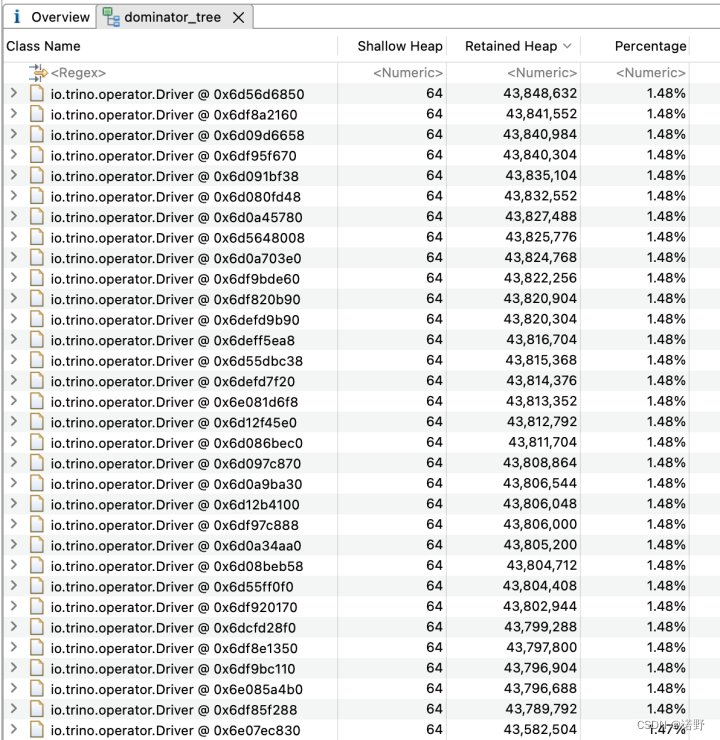
- 从下面第一张图可以看出,内存主要被Driver对象消耗,而这样的driver对象一共有62个。
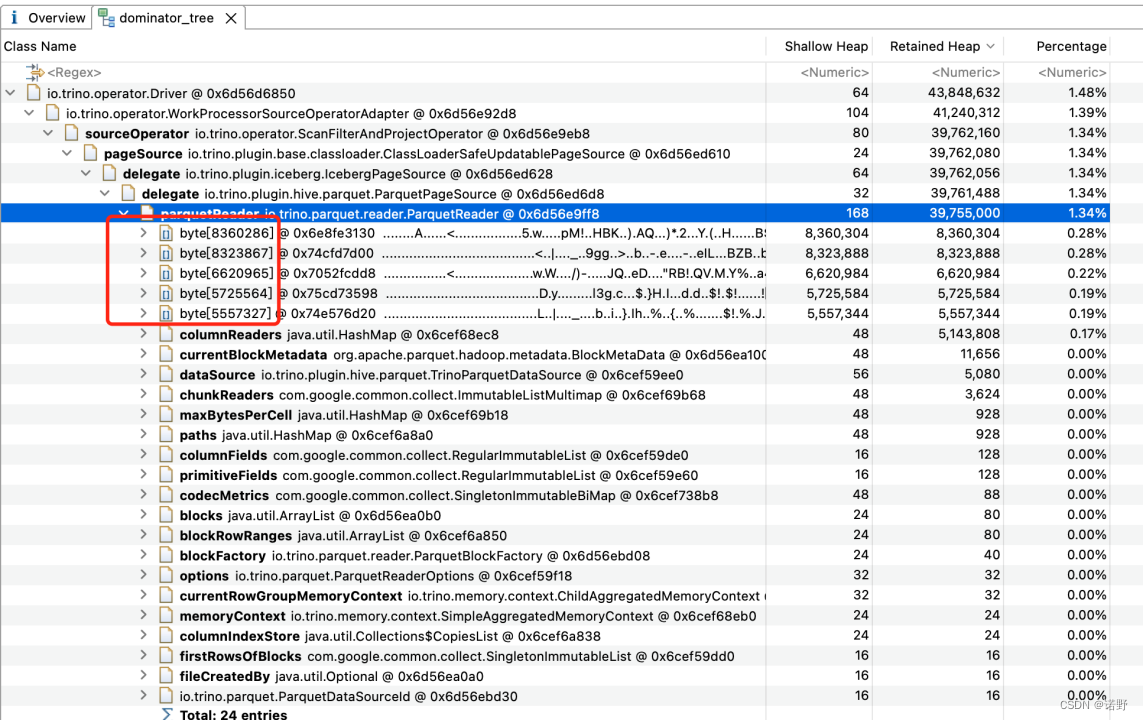
- 而进一步分析发现主要由ParquetReader消耗了比较多的内存,每一个实例大概消耗35MB字节。(第二张图)
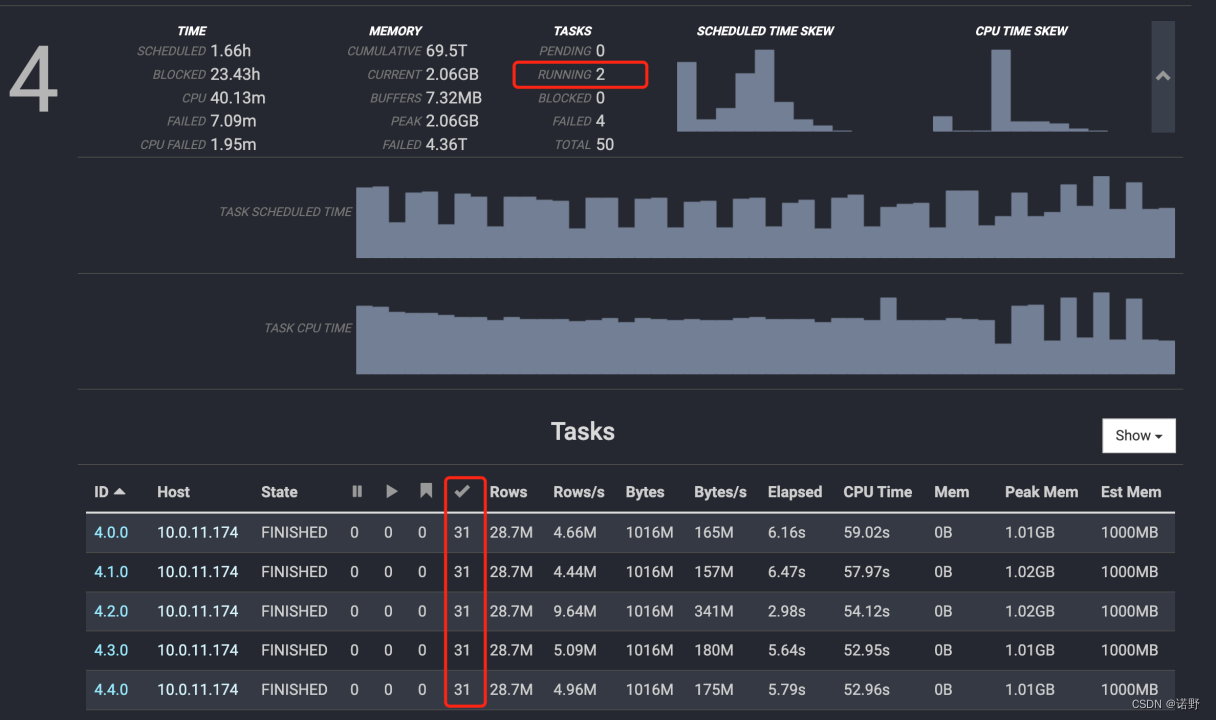
- 从trino web ui来看(第三张图),每一个task会运行31个split driver,基于fault-tolerant-execution-task-memory=1GB的配置,实例可以同时运行2个task,所以刚好是62个driver。
原因总结
从上面的分析可以得到内存消耗过大的主要原因是:
- ParquetReader消耗的内存比较多。
- 每一个task的split数量过大,导致并行处理的driver数过大。 基于fault-tolerant-execution-target-task-input-size=1GB需要处理1GB的数据文件,但产生了31个split,说明每一个文件大小在32MB的样子
解决方案
需要优化以上的问题,可以考虑几种方式:
- 将fault-tolerant-execution-target-task-input-size调小,这样最终并行的driver数也会变小。但是可能影响吞吐性能(导致小task比较多)
- 将表的数据文件进行小文件合并,将小文件合并成大文件,那split数量也会变小。
- 调整ParquetReader的配置,比如控制batchSize,降低buffer的内存消耗。
- 优化trino的worker的task执行模型,比如一个task的split集合按FIFO的顺序去处理(即控制split消费并发度)。(需要进一步调研可行的优化方案,需要新增一种对批处理场景更稳定的worker task调度模型)















 1131
1131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









