






目录
一、引言:
- pandas是Python的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系数据、标记数据。因为pandas建造在NumPy的基础之上,所以在以NumPy为中心的应用中,pandas易于使用,而 pandas库在与其他第三方科学计算支持库结合时也能够较完美地进行集成。
- 在本文中,我们将探讨pandas库在读取数据时因电脑文件路径差异而可能遇到的报错情况,并提供相应的解决方法和建议。在数据处理和分析的过程中,数据读取是第一步也是至关重要的一步。然而,由于不同电脑的文件系统、用户权限、路径设置等因素的差异,pandas在尝试读取文件时可能会遇到各种路径相关的报错。这些报错可能包括文件不存在、路径错误、权限不足等。本文主要讲解因为路径格式化差异不同操作系统(如Windows、Linux、macOS)使用不同的路径分隔符(如
\、/)的问题而造成的pandas读取数据的报错处理。
二、前期准备
2.1数据读取的意义
数据读取在数据分析中具有重要的核心地位。正确读取数据是确保分析准确、可靠和高效的关键步骤。因此,在进行数据分析时,应充分重视数据读取环节,确保数据的正确性和完整性,为后续的分析提供有力的支持。
2.2pands可读取的常见数据源
Pandas是一个强大的数据处理库,能够读取多种类型的数据源。以下是一些常见的数据源类型及其读取方法:
文本文件
文本文件是Pandas可以读取的常见数据源之一,包括csv、txt等格式。
读取方法
使用read_csv()函数读取csv文件。
对于其他文本文件,可以使用read_table()函数,并通过sep参数指定分隔符。
Pandas可以通过read_excel()函数读取Excel文件。
三、安装pandas库
安装Python和pip之后,可以使用pip来安装Pandas库。以下是安装Pandas库的步骤:
-
打开终端或命令提示符窗口。在Windows上,可以通过开始菜单搜索“cmd”或按下Win+R键并输入“cmd”来打开命令提示符。在macOS或Linux上,可以打开终端应用程序1234。
-
输入以下命令以安装Pandas库:
pip install pandas四、对路径格式差异的问题导致的读取数据的报错处理
4.1 路径格式差异的原因
在数据分析和处理的课程中,课本通常会通过具体的示例来演示如何读取数据。其中,一个常见的例子就是使用pandas库来读取存储在本地或远程服务器上的数据集。
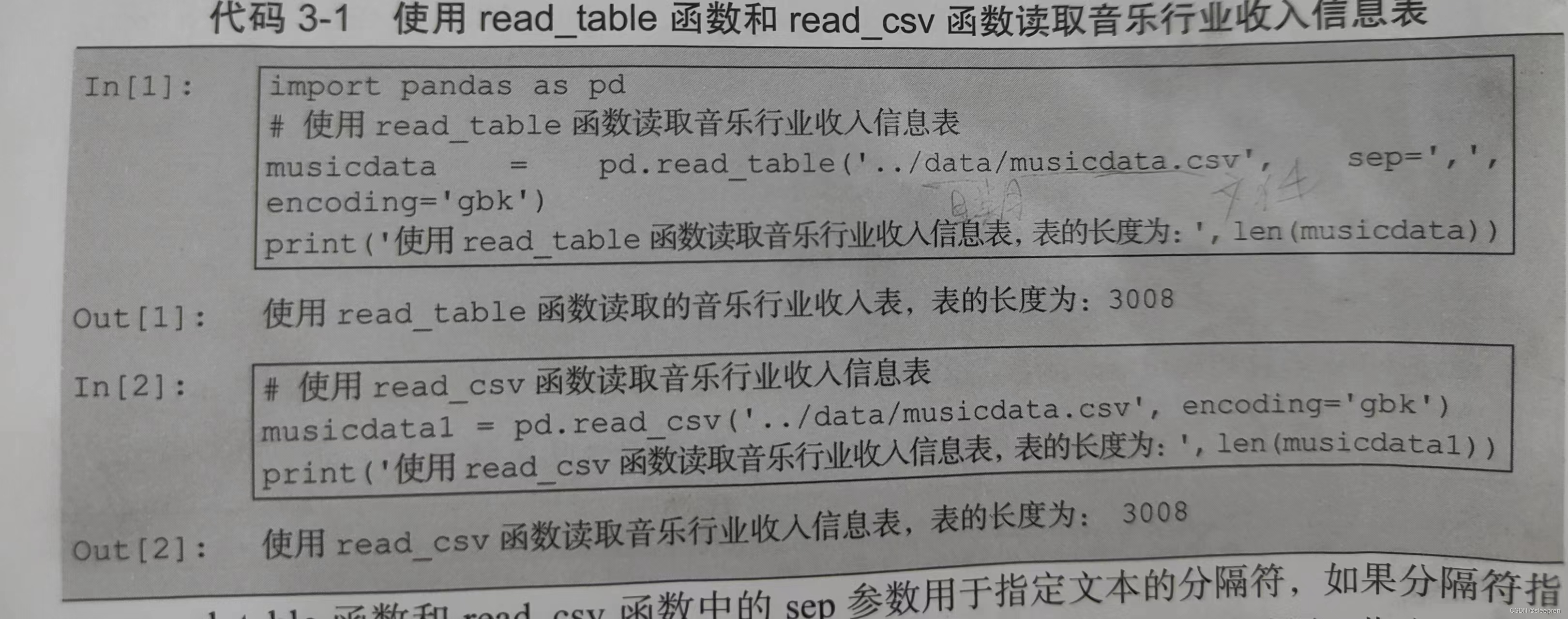
在数据分析和处理的实践中,经常需要从本地文件系统中读取数据。然而,由于不同用户的操作系统、文件存储习惯以及项目结构设置的不同,实际在读取文件时可能会遇到与书本示例中的路径格式差异的问题。
书上的示例通常会提供一个标准或通用的路径格式,比如基于Unix或Linux系统的路径格式(使用正斜杠/作为目录分隔符),或者是一个相对路径(相对于当前工作目录的路径)。但是,在Windows操作系统中,路径格式通常使用反斜杠\作为目录分隔符,这就会与书上的示例产生差异。
此外,用户的文件可能存储在电脑的不同位置,比如C盘、D盘或其他自定义的文件夹中,这也会导致路径的差异。另外,项目的组织结构和命名习惯也会影响文件的路径。
4.2 解决路径格式差异的方法:
当自己电脑上的文件路径与书上的示例不匹配时,就需要根据实际情况修改路径字符串。在Python中,可以使用原始字符串(在字符串前加上r)来避免转义字符的问题,或者将反斜杠替换为双反斜杠\\或正斜杠/(在Windows系统中,这两种写法通常都可以被识别为目录分隔符)。
例如,如果书本上给出的示例路径是../data/musicdata.csv,而你的数据文件存储在Windows系统的D:\musicdata.csv,为了解决这个问题,我们可以使用以下几种方法之一:
因此,在实际操作中,需要根据自己电脑上的文件路径来修改代码中的路径字符串,以确保能够正确地读取数据。
-
使用原始字符串(raw strings):在字符串前加上
r或R来表示原始字符串,这样Python就不会将反斜杠作为转义字符。
import pandas as pd
# 使用pandas的read_csv函数读取CSV文件,文件路径使用原始字符串
musicdata = pd.read_csv(r'D:\musicdata.csv')2.将反斜杠替换为正斜杠(/):在Windows系统中,正斜杠也可以用作路径分隔符,并且Python不会将其视为转义字符。
import pandas as pd
# 将反斜杠替换为正斜杠
musicdata= pd.read_csv('D:/musicdata.csv')3.使用双反斜杠:在每个反斜杠前再加一个反斜杠来进行转义
# 导入pandas库并为其指定别名pd
import pandas as pd
# 使用pandas的read_csv函数读取CSV文件,文件路径使用双反斜杠进行转义
musicdata = pd.read_csv('D:\\musicdata.csv')| 使用原始字符串来避免转义字符问题 | musicdata=pd.read_csv(r'D:\musicdata.csv') |
| 使用双反斜杠来替代单个反斜杠 | musicdata=pd.read_csv('D:\\musicdata.csv ') |
| 将反斜杠替换为正斜杠(/) | 在Windows系统中, musicdata=pd.read_csv('D:/musicdata.csv ') |
4.3运行成功代码展示
经过适当的修改后代码可正常运行。

五、总结
Pandas,作为Python数据分析的基石,为数据科学家和分析师提供了高效且灵活的数据处理能力。在数据分析的旅程中,数据的读取是第一步,而不同数据源需要适配不同的读取策略。Pandas支持从文本文件(如CSV、TXT)、Excel文件以及数据库等多种来源读取数据。然而,在读取过程中,可能会遭遇各种挑战,其中路径格式差异就是一个常见问题。
路径格式差异主要源于不同操作系统对文件路径的约定不同。例如,Unix和Linux系统倾向于使用正斜杠(/)作为目录分隔符,而Windows系统则使用反斜杠(\)。在Python中,反斜杠(\)被用作转义字符,这可能导致在Windows系统中编写文件路径时出现错误。
解决路径格式差异的方法有多种,可以使用原始字符串来避免转义字符问题,也可以将反斜杠替换为双反斜杠或正斜杠。这些方法在Windows系统中通常都能被识别为有效的目录分隔符。 因此,在使用Pandas读取数据时,需要注意路径格式的正确性,并根据实际情况进行调整。同时,也需要了解不同数据源的读取方法和可能遇到的问题,以便更好地进行数据预处理和分析工作。















 5816
5816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









