







论文做到了LDA可视化
放一张效果图叭
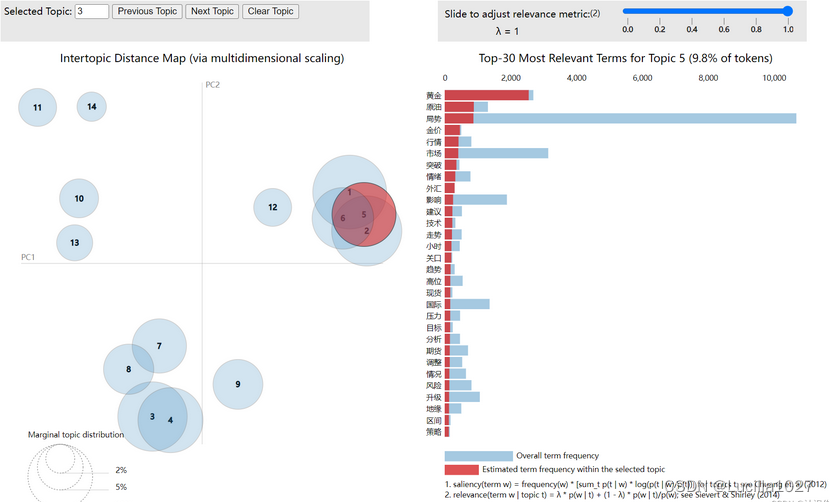 主要讲讲右上角那个参数
主要讲讲右上角那个参数
在pyLDAvis可视化结果中,右上角的参数是指lambda值。这个参数控制着文档中的词语权重和主题词语权重之间的比例。当lambda值趋近于0时,只有主题词语权重被考虑,而当lambda值趋近于1时,只有文档中的词语权重被考虑。因此,选择合适的lambda值可以使得可视化结果更加符合实际情况。默认情况下,lambda值为0.6。用户可以通过滑动滑块来调整lambda值,以获得最佳的可视化效果。
在pyLDAvis中,lambda值是通过pyLDAvis.prepare()函数中的mds参数进行控制的。具体来说,mds参数是一个包含以下四个元素的列表:
X:文档-主题分布矩阵,每行代表一个文档,每列代表一个主题。
tdm:文档-词语矩阵,每行代表一个文档,每列代表一个词语。
vocab:词汇表,即所有词语的列表。
doc_lengths:每个文档包含的词语数量的列表。
在mds参数中,lambda值可以通过将X矩阵中每一列的值与tdm矩阵中每一行的值加权平均来计算得到。具体来说,计算过程如下:
def _job(X, Y, l1, l2):
return ((X * l1 + Y * (1 - l1)) * l2 + Y * (1 - l2))
X = _job(doc_topic, topic_term, 1-lambda_value, lambda_value)
#其中,doc_topic和topic_term分别是主题-文档分布矩阵和主题-词语分布矩阵。
#lambda_value即为用户指定的lambda值。通过这样的方式,我们可以在可视化结果中控制词语权重和主题词语权重之间的比例。
pyLDAvis可视化结果中右上角的参数并不是TFIDF算法。
TFIDF算法是一种常用的文本特征提取方法,用于将文本转化为可用于机器学习算法的特征向量。
这个参数lambda的作用是调整主题-词语矩阵和文档-主题矩阵之间的关系,以获得更好的可视化效果。具体来说,当lambda值趋近于0时,主题-词语矩阵中的主题词语权重更重要,而当lambda值趋近于1时,文档-主题矩阵中的文档词语权重更重要。
———————————有其他想到的我会随时补充————————————
欢迎批评指正!!















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









