一、结果预示

二、制作过程
2.1 图片准备
- 准备一张背景白色的图片

2.2 数据准备
import akshare as ak
covid_19_163_df = ak.covid_19_163(indicator="实时资讯新闻播报")
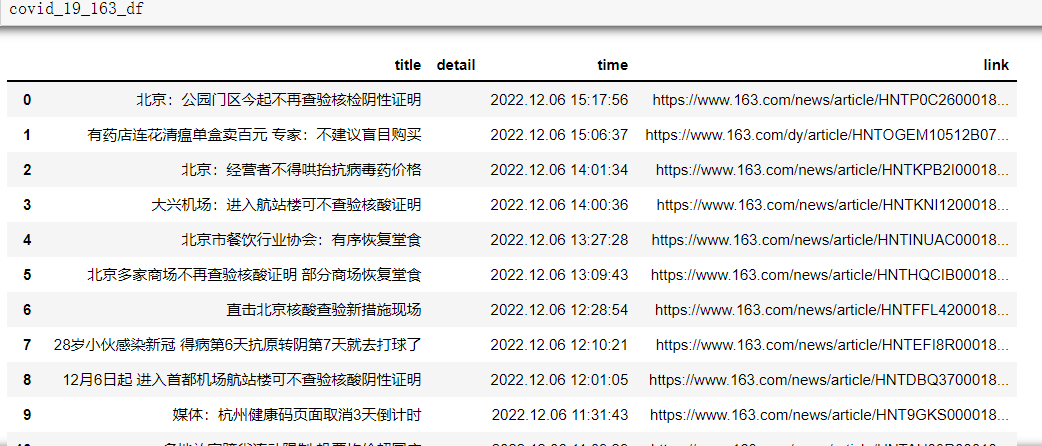
2.3 数据处理
import re
title = "".join(covid_19_163_df.title.tolist())
text = "".join(re.findall('[\u4e00-\u9fa5]', title))

- jieba 分词处理:含去掉自定义词语、新增自定义词语
import jieba
drop_words = ['你','不']
for word in drop_words:
jieba.del_word(word)
jieba.add_word('社会面')
seg_list = ",".join(jieba.cut(text,cut_all=False,HMM=True))

三、绘制词云图
import numpy as np
from wordcloud import WordCloud
from PIL import Image
mask = np.array(Image.open("小鸟.png"))
wordcloud = WordCloud(
font_path="C:\\Windows\\Fonts\\simsun.ttc",
background_color="black",
width = 800,
height = 600,
max_words = 100,
max_font_size = 80,
mask = mask,
collocations=False
).generate(seg_list)
wordcloud.to_file('词云图_小鸟.png')

四、完整代码
import re
import jieba
import numpy as np
from wordcloud import WordCloud
from PIL import Image
import akshare as ak
covid_19_163_df = ak.covid_19_163(indicator="实时资讯新闻播报")
title = "".join(covid_19_163_df.title.tolist())
text = "".join(re.findall('[\u4e00-\u9fa5]', title))
drop_words = ['你','不']
for word in drop_words:
jieba.del_word(word)
jieba.add_word('社会面')
seg_list = ",".join(jieba.cut(text,cut_all=False,HMM=True))
mask = np.array(Image.open("小鸟.png"))
wordcloud = WordCloud(
font_path="C:\\Windows\\Fonts\\simsun.ttc",
background_color="black",
width = 800,
height = 600,
max_words = 100,
max_font_size = 80,
mask = mask,
collocations=False
).generate(seg_list)
wordcloud.to_file('词云图_小鸟.png')





















 4116
4116











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









