







ConvolutionLayer
ConvolutionLayer 继承于 BaseConvolutionLayer。
一、层的初始化
1. BaseConvolutionLayer::LayerSetUp()
在BaseConvolutionLayer::LayerSetUp() 会对 blobs_ 进行初始化,以下是weights的初始化
// Initialize and fill the weights:
// output channels x input channels per-group x kernel height x kernel width
this->blobs_[0].reset(new Blob<Dtype>(weight_shape));
shared_ptr<Filler<Dtype> > weight_filler(GetFiller<Dtype>(
this->layer_param_.convolution_param().weight_filler()));
weight_filler->Fill(this->blobs_[0].get());
类似的还有bias项,weight_shape一般是(output channels, input channels, height, width)。而bias_shape是(output channels),也就是说bias是一个向量。
而在卷积层当中,是需要后向传播的。
this->param_propagate_down_.resize(this->blobs_.size(), true);
2. BaseConvolutionLayer::Reshape()
在BaseConvolutionLayer::Reshape()中,先对 top 进行 shape。
top[top_id]->Reshape(top_shape);
其中,top_shape为(batch_size, output channels, height, width)。
在对卷积层做卷积的时候,实际上,是先利用 im2col()函数把原始的bottom转化成 col_buffer_,然后再进行相关的计算,在卷积完成结束后,再利用 col2im() 函数转化成 top的形状。
其中, col_buffer_shape_为(kernel_dim_* group, output height, output width), 而 kernel_dim_的值为 input channel * kernel height * kernel width, group 一般为1.
同时,这里的col_buffer_ 只是存储一个图片的相关数据,因为考虑到内存空间的原因。下面的Forward()函数中也会提到,在一个循环中对每张图片进行计算处理。
top_dim_ = top[0]->count(channel_axis_);
num_kernels_im2col_ = conv_in_channels_ * conv_out_spatial_dim_; //conv_out_spatial_dim_为top 的 height * width
num_kernels_col2im_ = reverse_dimensions() ? top_dim_ : bottom_dim_;
二、前向传播
1. 我们先来看 CPU 版本的前向传播
ConvolutionLayer<Dtype>::Forward_cpu() {
...
for (int n = 0; n < this->num_; ++n) { // 这个num_可以理解为batch_size, 在卷积层的计算的时候,是一个一个图片的处理的.
this->forward_cpu_gemm(bottom_data + n * this->bottom_dim_, weight,
top_data + n * this->top_dim_);
...
this->forward_cpu_bias(top_data + n * this->top_dim_, bias);
...}
2. forward_cpu_gemm()
void BaseConvolutionLayer<Dtype>::forward_cpu_gemm(const Dtype* input,
const Dtype* weights, Dtype* output, bool skip_im2col) {
...
conv_im2col_cpu(input, col_buffer_.mutable_cpu_data()); // 先利用 im2col 将input 转换进 col_buffer_
...
for (int g = 0; g < group_; ++g) { // 一般的 group_ = 1
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, conv_out_channels_ /
group_, conv_out_spatial_dim_, kernel_dim_,
(Dtype)1., weights + weight_offset_ * g, col_buff + col_offset_ * g,
(Dtype)0., output + output_offset_ * g);
} }
gemm 的展开是
generalized matrix multiplication.,也就是说,这个caffe_cpu_gemm 实现的是一个矩阵相乘的功能。
3. im2col()
template <typename Dtype>
void im2col_cpu(const Dtype* data_im, const int channels,
const int height, const int width, const int kernel_h, const int kernel_w,
const int pad_h, const int pad_w,
const int stride_h, const int stride_w,
const int dilation_h, const int dilation_w,
Dtype* data_col)
im2col()的功能就是根据 input,一个三维的blob, 求得col_buff,也是一个三维的blob,但是实际上,col_buff 可以理解为一个按行主序展开的二维的矩阵(kernel_dim x conv_output_spatial_dim)。
其中,kernel_dim = kernel channel * kernel height * kernel width, conv_output_spatial_dim 则是通过 compute_output_shape() 函数求得的,表示的是output的output height * ouput width, 而 compute_output_shape() 函数的实现则是利用我们熟悉的公式:
kernel_extent = dilation * (kernel_size - 1) + 1;
output_size = (input_size + 2*pad - kernel_extent) / stride + 1;
下面举个简单的例子:
当input 的 channel = 3, height = 3, width = 3,
kernel_h = 2, kernel_w = 2, pad = 0, stride = 1, dilation = 1.
此时的input是一个 (3, 3, 3) 的blob,而计算可得 kernel_dim = channel * kernel_h * kernel_h = 12,
output_height = output_width = (height + 2 *pad - kernel_extent) / stride + 1 = (3 - 2) / 1 + 1 = 2。
所以,col_buff 是一个(12, 2, 2) 的blob, 按行主序展开是一个 12x4 的二维矩阵。
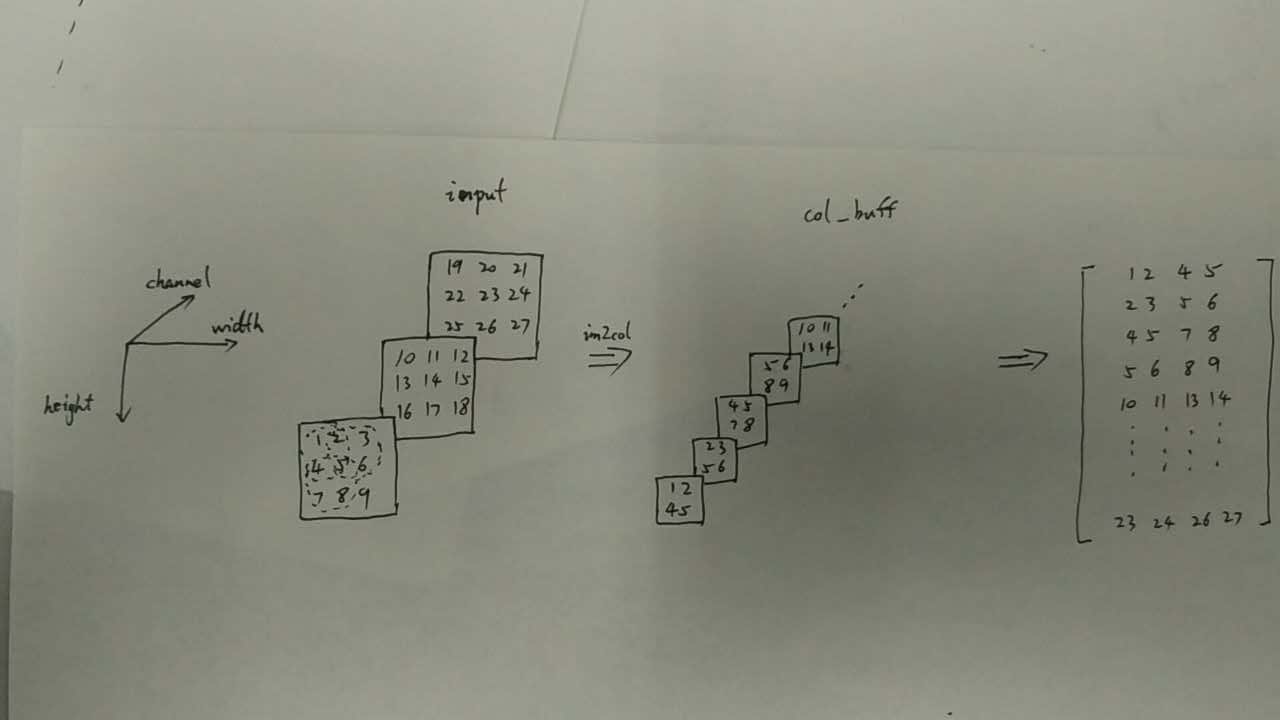
图1
4. caffe_cpu_gemm()
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, conv_out_channels_ /
group_, conv_out_spatial_dim_, kernel_dim_,
(Dtype)1., weights + weight_offset_ * g, col_buff + col_offset_ * g,
(Dtype)0., output + output_offset_ * g);
将 input 转化成 col_buff 之后,则可以利用 blas 矩阵相乘函数来加速计算,得到我们想要的output,最后再通过col2im 转换回对应的原始的blob形状。
cpu_gemm()的原型为
void caffe_cpu_gemm<float>(const CBLAS_TRANSPOSE TransA,
const CBLAS_TRANSPOSE TransB, const int M, const int N, const int K,
const float alpha, const float* A, const float* B, const float beta,
float* C) {
int lda = (TransA == CblasNoTrans) ? K : M;
int ldb = (TransB == CblasNoTrans) ? N : K;
cblas_sgemm(CblasRowMajor, TransA, TransB, M, N, K, alpha, A, lda, B,
ldb, beta, C, N);
}
我们再来看里面的cblas_sgemm()函数,
CblasRowMajor表示按行主序展开,类似于上图1,CblasNoTrans表示矩阵不进行转置。在这里,
M = conv_out_channels_ / group_ ; //取决于kernel的个数
N = conv_out_spatial_dim_;
K = kernel_dim_;
alpha = 1;
A 表示 weights 按行主序展开,不转置的矩阵A 。
lad = K;
B 表示 col_buff 按行主序展开,不转置的矩阵B 。
ldb = N;
beta = 0;
C 表示 输出矩阵C。
ldc = N;
在CblasRowMajor按行主序展开的条件下,且A,B 不转置,则 lda, ldb , ldc 分别表示A,B,C 的列数。
相应的有:
M,矩阵A的行,矩阵C的行
N,矩阵B的列,矩阵C的列
K,矩阵A的列,矩阵B的行
即 A 为 M行K列
B 为 K行N列
C 为 M行N列
函数执行后得到结果:
C = alpha*AB + beta*C
这里alpha = 1,beta = 0;
那么就有:
top_data = weight x col_buff,这里求得的top_data在内存顺序上,刚好对应于top_data相应的Blob形状的顺序。

图2
5.
forward_cpu_bias()
以上的前向传播计算是weight的计算,此外还有bias项。和weight的计算无太大区别。依然是利用caffe_cpu_gemm()进行矩阵计算。
相关公式为
C = alpha*AB + beta*C。
void BaseConvolutionLayer<Dtype>::forward_cpu_bias(Dtype* output,
const Dtype* bias) {
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num_output_,
out_spatial_dim_, 1, (Dtype)1., bias, bias_multiplier_.cpu_data(), // bias_multiplier_ 可以理解为一个长度为N的一维列向量,值全为1.
(Dtype)1., output);
}
三、后向传播
1. 先来看ConvolutionLayer::Backward_cpu()
void ConvolutionLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) {
for (int i = 0; i < top.size(); ++i) {
...
this->backward_cpu_bias(bias_diff, top_diff + n * this->top_dim_); //先是计算 bias 的梯度
...
this->weight_cpu_gemm(bottom_data + n * this->bottom_dim_, //然后是weight 的梯度
top_diff + n * this->top_dim_, weight_diff);
...
this->backward_cpu_gemm(top_diff + n * this->top_dim_, weight, //计算上一层数据的梯度
bottom_diff + n * this->bottom_dim_);
...}}
2. backward_cpu_bias()
void BaseConvolutionLayer<Dtype>::backward_cpu_bias(Dtype* bias,
const Dtype* input) {
caffe_cpu_gemv<Dtype>(CblasNoTrans, num_output_, out_spatial_dim_, 1.,
input, bias_multiplier_.cpu_data(), 1., bias);
}
void caffe_cpu_gemv<float>(const CBLAS_TRANSPOSE TransA, const int M,
const int N, const float alpha, const float* A, const float* x,
const float beta, float* y) {
cblas_sgemv(CblasRowMajor, TransA, M, N, alpha, A, N, x, 1, beta, y, 1);
}
cblas_sgemv()实现的是:
y = alpha*Ax + beta*y
其中,Y是一个向量 vector。
在这里,
A 是按行主序展开的top_diff,M行N列
M = num_output_
N = out_spatial_dim_
alphat = 1
beta = 1
x 是一个N全为1的列向量,即N行1列
y 表示的是 bias_diff,同样为 N行1列
所以有:
bias_diff = top_diff xbias_multiplier_ +
bias_diff
对应的数学公式(摘自NG的课程):
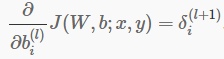
3. weight_cpu_gemm()
void BaseConvolutionLayer<Dtype>::weight_cpu_gemm(const Dtype* input,
const Dtype* output, Dtype* weights) {
const Dtype* col_buff = input;
if (!is_1x1_) {
conv_im2col_cpu(input, col_buffer_.mutable_cpu_data());
col_buff = col_buffer_.cpu_data();
}
for (int g = 0; g < group_; ++g) {
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasTrans, conv_out_channels_ / group_,
kernel_dim_, conv_out_spatial_dim_,
(Dtype)1., output + output_offset_ * g, col_buff + col_offset_ * g,
(Dtype)1., weights + weight_offset_ * g);
} }
这里的caffe_cpu_gemm() (参考图二)对应的,是实现:
weights = top_diff x (col_buff)T + weights , col_buff = im2col(bottom_data);
对应的数学公式:
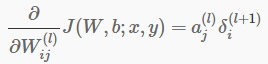
这里可以发现,把 bottom 转换为 col_buff 后,对于卷积层的参数求导计算方便了很多,这个求导过程就和全连接层的求导方式是一样的了。
4.backward_cpu_gemm()
void BaseConvolutionLayer<Dtype>::backward_cpu_gemm(const Dtype* output,
const Dtype* weights, Dtype* input) {
Dtype* col_buff = col_buffer_.mutable_cpu_data();
...
for (int g = 0; g < group_; ++g) {
caffe_cpu_gemm<Dtype>(CblasTrans, CblasNoTrans, kernel_dim_,
conv_out_spatial_dim_, conv_out_channels_ / group_,
(Dtype)1., weights + weight_offset_ * g, output + output_offset_ * g,
(Dtype)0., col_buff + col_offset_ * g);
}
...
conv_col2im_cpu(col_buff, input);
...}
这里的caffe_cpu_gemm()实现:
col_buff = (weights)T x top_diff
这个对应的数学公式,是求导的链式法则。
最后再通过conv_col2im_cpu()实现 col_buff 转换回原始对应的 bottom_diff 。
col2im 的过程有点像 im2col 的逆过程,但不是说 col2im 和 im2col 是一个可逆的过程,
也就是说,B = im2col(A),A != col2im(B)。
im2col 是一个图片展开成块的过程,而col2im 是把块累加合并成图片的过程:
在和图1相同的条件下,
即input 的 channel = 3, height = 3, width = 3,
kernel_h = 2, kernel_w = 2, pad = 0, stride = 1, dilation = 1.
把二维矩阵转化成2x2的块后,按stride=1进行累加拼接:
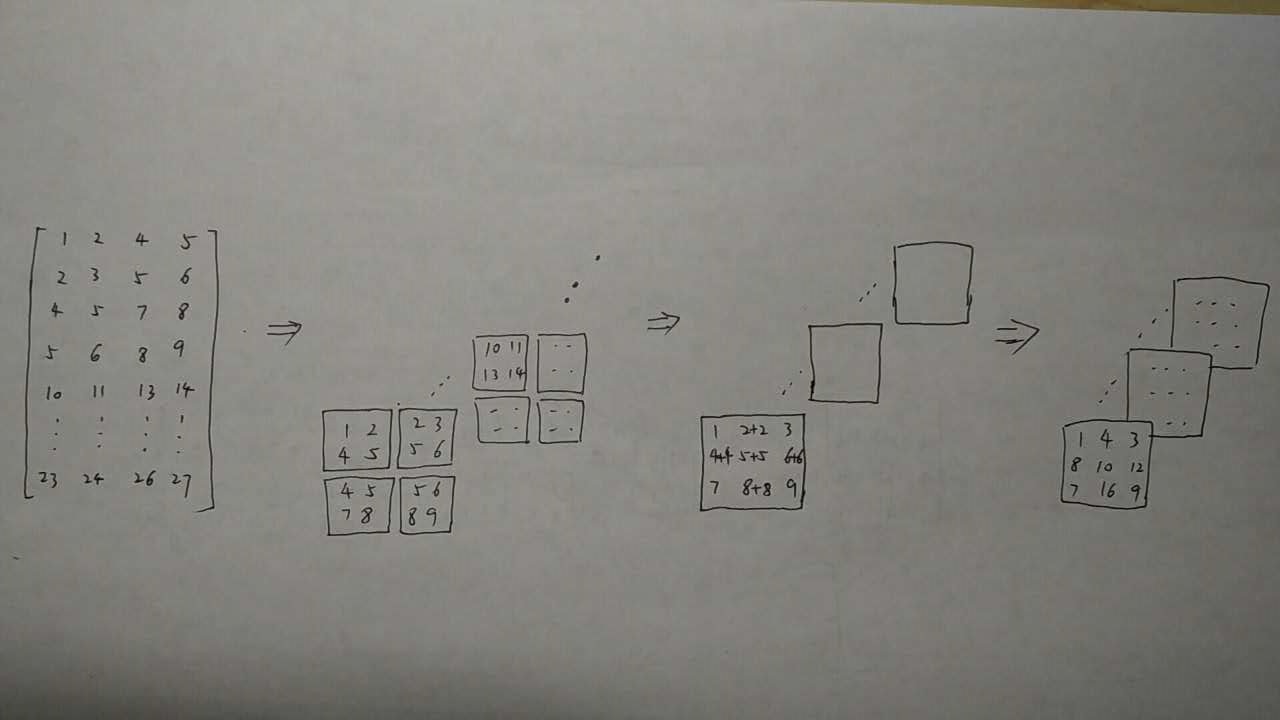
图3
到这里,ConvolutionLayer算是总结完了。
关于 gemm、sgemm 等 blas 的矩阵运算API,可以参考这里的总结:















 1829
1829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









