







系列文章目录
机器学习算法(一):1. numpy从零实现线性回归
机器学习算法(一):2. 线性回归之多项式回归(特征选取)
前言
本博客主要是将线性回归推广到多项式线性回归,主要实现手段就是进行特征选择来实现多项式线性回归。
一、特征选取(特征构建)
这里说特征选取有点大了,说特征构建吧!看下面例子

这是一个二次函数,可以看到用简单的线性回归拟合效果永远无法实现拟合曲线的效果。要达到这种拟合曲线的情况就要用多项式回归了,其本质还是线性回归。我们主要对特征做一些手脚就可以实现这种效果了。上图中只有一个特征
x
x
x,我们进行特征组合,加入一个新的特征
x
2
x^2
x2,记
x
1
=
x
,
x
2
=
x
2
x_1 = x , x_2 = x^2
x1=x,x2=x2,这样模型就变成了:
y
=
w
1
x
+
w
2
x
2
=
w
1
x
1
+
w
2
x
2
\begin{align} y&=w_1x+w_2x^2 \\ &=w_1x_1+w_2x_2 \end{align}
y=w1x+w2x2=w1x1+w2x2
最终还是变成了线性回归问题。这种特征组合是属于特征工程的一种,通过不同的特征组合,可以实现不同的效果。
二、代码实现
1.生成数据
x = np.arange(0,20,1)
X = x.reshape(-1,1)
y = X**2 + 1
fig = plt.figure()
plt.scatter(X,y)
输出: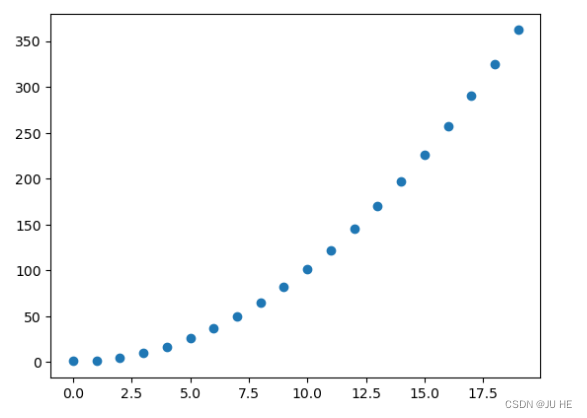
2.搭建线性回归模型
本节在上个博客里已经有详细说明,看不懂可以参考机器学习算法(一):1. numpy从零实现线性回归
def predict(X,w,b):
'''
模型预测函数
:param X:
:param w:
:param b:
:return:
'''
return np.dot(X,w) + b
def loss(X,y,w,b):
'''
:param X: 训练集特征
:param y: 标签
:param w: 参数
:param b: 参数
:return:
'''
m = X.shape[0]
return 1/(2*m)*np.sum(((np.dot(X,w)+b)-y)**2)
def compute_gradient(X, y, w, b):
'''
计算梯度,用逐点相乘的思路
:param X:
:param y:
:param w:
:param b:
:return:
'''
m, n = X.shape[0], X.shape[1]
dj_dw = np.zeros((n, 1))
dj_db = np.zeros((1,))
err = np.dot(X, w) + b - y
for j in range(n):
dj_dw[j, 0] = (1/m) * np.sum(err * X[:, j].reshape((y.shape))) # 使用广播机制计算
# dj_dw[j, 0] = (1/m) * np.sum(err * X[:, j]) 这样err是二维数组,X[:, j]是一维数组广播进行逐点会广播出错,都改变成二维
# 这个坑我排除了一下午才发现,进行向量化操作时刻注意进行广播时的维度要特别特别注意,看大神写代码经常reshap一下,就是为了防止广播出错
dj_db = (1/m) * np.sum(err)
return dj_db, dj_dw
def gradient_descent(X, y, w_in, b_in, loss, gradient_function, alpha, num_iters):
J_history = []
# 用来存每进行一次梯度后的损失,方便查看损失变化。如果要画损失变化也是用这个
# w = copy.deepcopy(w_in) #avoid modifying global w within function
w = w_in
b = b_in
for i in range(num_iters):
dj_db,dj_dw = gradient_function(X, y, w, b)
w = w - alpha * dj_dw
b = b - alpha * dj_db
if i<100000:
J_history.append( loss(X, y, w, b))
if i % math.ceil(num_iters / 10) == 0:
# 控制间隔 打印出一次损失结果
# 总迭代次数分成均分10组,在每组最后打印一次损失
print(f"迭代次数(梯度下降次数) {i:9d}: Cost {float(J_history[-1]):0.5e}")
return w, b, J_history
3. 使用简单线性回归,不组合新特征
w_init = np.zeros((X.shape[1],1))
b_init = np.array([[0]])
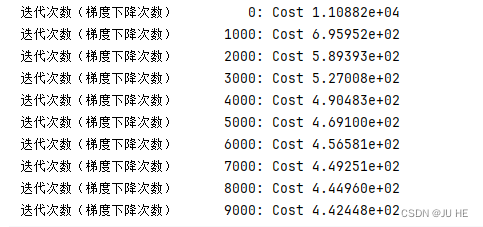
w_final, b_final, J_history = gradient_descent(X,y,w_init,b_init,loss,compute_gradient,0.001,10000)
输出:
y_hat = predict(X,w_final,b_final)
fig = plt.figure()
plt.scatter(X,y,color='r',label='true')
plt.plot(X,y_hat,color='b',label='predit')
plt.xlabel('x')
plt.legend()
plt.show()
输出: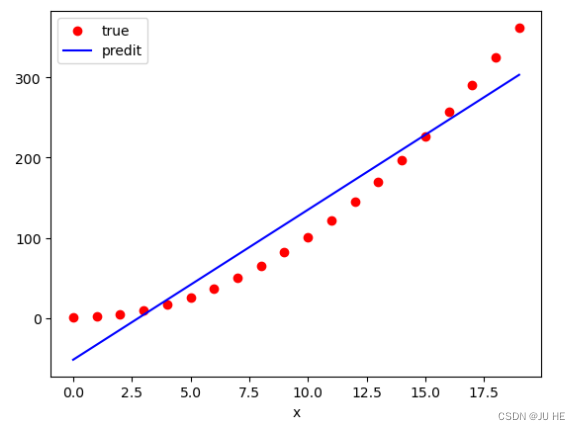
4. 使用组合特征(多项式回归)
X_1 = X
X_2 = X**2
X_ = np.concatenate((X_1,X_2),axis=1)
y_ = X_1**2
print(X_)
print(y_)
输出: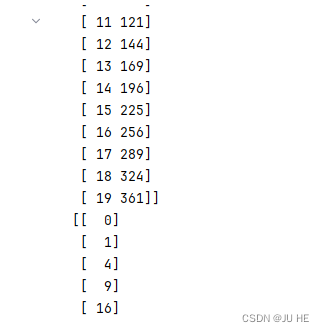
w_init2 = np.zeros((X_.shape[1],1))
b_init2 = np.array([[0]])
w_final, b_final, J_history2 = gradient_descent(X_,y_,w_init2,b_init2,loss,compute_gradient,0.000001,100000)
# 这里学习率尤为注意,设置过大会导致loss一直变大,最后溢出。0.0001好像都不行,还有更小才行
输出:
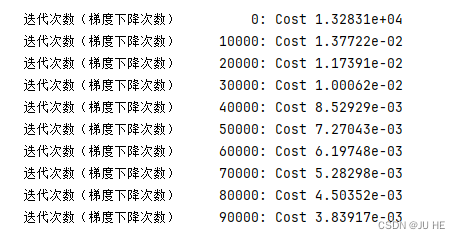
【注】:这里尤其注意学习率要足够小,不然loss一直变大,最后数据值太大计算机溢出
y_hat = predict(X_,w_final,b_final)
fig = plt.figure()
plt.scatter(X_1,y_,color='r',label='true')
plt.plot(X_1,y_hat,color='b',label='predit')
plt.legend()
plt.show()
输出: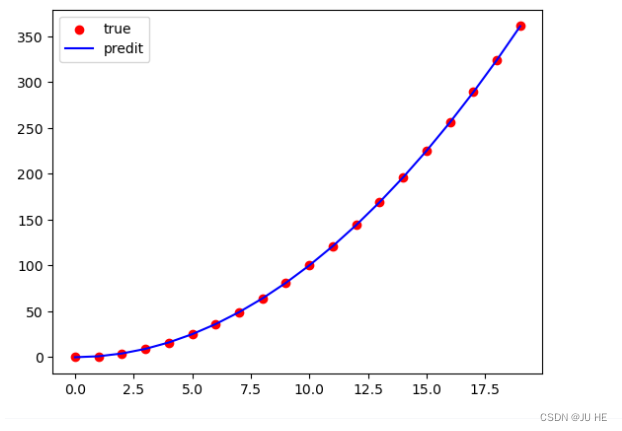
总结
以上就是今天关于多项式回归的简单实现了,

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









