







系列文章目录
文章目录
- 系列文章目录
- 前言
- 一、张量的创建与转化(pytorch基础)
- 二、torch里面的一些数学函数
- 三、torch里面的逐点相乘和矩阵乘法
- 四、pytorch自动微分
- 1. torch.tensor(data, dtype=None, device=None, requires_grad=False)
- 2. .gard :就是用来获取梯度的。
- 3. function.backward():反向传播计算梯度(反向传播计算导数的一个算法),向前传播就是你定义function的这个过程
- 4. tensor.grad.zero()_ : 将tensor的梯度清零。
- 5. with torch.no_grad(): 将代码块使用 with torch.no_grad(): 包装起来,停止跟踪历史记录(和使用内存),简单来讲就是不需要梯度了在这个计算过程中 (重要!!!!!,今后实例中就会发现怎么用了)
- 总结
前言
在用pytorch进行搭建网络前需要先熟悉一下其中的一些主要API接口,本文会记录一些简单又很常用的接口,方便后续查阅。
一、张量的创建与转化(pytorch基础)
张量理解成numpy里面的数组就可以了,其实就是将numpy数组再封装了一层就变成了pytorch里面的基本数据结构。
1. tensor与numpy的相互转换
torch.tensor() 是 PyTorch 中用于创建张量(tensor)的主要函数之一。张量是 PyTorch 中最基本的数据结构,类似于 Numpy 中的数组,但具有 GPU 加速和自动求导等功能。
以下是 torch.tensor() 的详细介绍:
(1)torch.tensor()
1). 语法:
torch.tensor(data, dtype=None, device=None, requires_grad=False)
2). 参数:
data(必需):创建张量的数据。可以是 Python 数字、Python 列表、NumPy 数组、其他张量、等等。dtype(可选):张量的数据类型。默认为 None,表示根据输入数据推断数据类型。常用的数据类型包括torch.float32、torch.int64等。device(可选):张量的存储设备。默认为 None,表示张量存储在 CPU 上。可以设置为torch.device('cuda')或torch.device('cuda:0')等来将张量存储在指定的 CUDA 设备上。requires_grad(可选):指示是否需要对张量进行梯度跟踪以进行自动求导。默认为 False。
3). 返回值:
- 返回一个新的张量,其数据由参数
data提供,dtype 由参数dtype指定,存储设备由参数device指定。
4). 示例:
import torch
# 从 Python 列表创建张量
tensor1 = torch.tensor([1, 2, 3])
# 指定数据类型和设备
tensor2 = torch.tensor([1.0, 2.0, 3.0], dtype=torch.float32, device='cuda')
# 从 NumPy 数组创建张量(numpy数组转换成torch)
import numpy as np
numpy_array = np.array([[1, 2], [3, 4]])
tensor3 = torch.tensor(numpy_array)
print(tensor3)
# torch转换成numpy数组
np_data = np.array(tensor3)
print(np_data)
输出:

5). 注意事项:
- 如果输入数据是其他张量,则
torch.tensor()会尝试重用输入张量的属性,例如数据类型、设备等。 - 如果需要创建与现有张量具有相同属性但不同值的张量,推荐使用
torch.*_like()函数(如torch.zeros_like()、torch.ones_like()等)。 - 默认情况下,
torch.tensor()创建的张量不会进行梯度跟踪,如果需要梯度跟踪,请设置requires_grad=True。
(2)tensor.data.numpy()方法
【注】:其实现在用detach()更加常见,data属性可能未来版本要舍弃了,今后我们用tensor.detach().numpy()是更加多的
在 PyTorch 中,tensor.data 也曾经是一个常用的方式来访问张量的原始数据,但是它有一些潜在的危险性,因此在较新的版本中,不推荐直接使用 tensor.data。tensor.data 返回的是一个没有梯度历史的张量,它指向的是张量的实际数据,但它与原始张量共享内存,因此,如果修改 tensor.data,它会直接影响原始张量的内容。
为什么要用这个方法呢,np.array()不就可以解决吗?实际上如果你创建的tensor没有requires_grad = True,用np.array()就直接可以了,否者就必须用这个。我们比较常用的matplotlib画图是不支持tensor的,因此我们经常需要将一些带梯度的tensor转换成numpy数据类型。
w = torch.tensor([1,2,3],requires_grad=True)
w1 = np.array(w)
输出:
w = torch.tensor([1.,2,3],requires_grad=True)
w2 = w.data.numpy()
print(type(w2))
输出:
(3)tensor.detach().numpy() (重要!!!!)
.detach() ---- 移出计算图,这个更加常用今后
tensor.detach() 会返回一个新的张量(移出计算图的tensor,就是没有requires_grad了),并不会修改原始张量。
(4)tensor的shape属性和怎么改变形状 — tensor.view(a,b,c) 和tensor.reshape(a,b,c) (重要!!!!!)
这个改变形状shape维度的view方法,今后我们也经常会用到
view和reshape功能是一样的,随便用哪一个都可以。
二、torch里面的一些数学函数
1. torch.abs()
torch.abs(torch.tensor([-1, -2, 3]))
输出: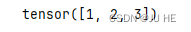
2. torch.sin()
a = torch.randn(4)
print(a)
torch.sin(a)
输出:
3. torch.mean()
torch.mean() 函数用于计算张量中所有元素的均值。下面是函数的基本用法和参数说明:
torch.mean(input_tensor, dim=None, keepdim=False, dtype=None)
参数说明:
input_tensor:输入的张量。dim:(可选)指定沿着哪个维度计算均值。如果不指定,将计算整个张量的均值。keepdim:(可选)如果设置为 True,则结果张量将保留与输入张量相同的维度数。默认为 False。dtype:(可选)输出张量的数据类型。
示例:
import torch
# 创建一个张量
x = torch.tensor([[1.0, 2.0],
[3.0, 4.0]])
# 计算整个张量的均值
mean_all = torch.mean(x)
print("整个张量的均值:", mean_all.item())
# 沿着指定维度计算均值
mean_dim0 = torch.mean(x, dim=0)
print("沿着第 0 维度的均值:", mean_dim0)
mean_dim1 = torch.mean(x, dim=1)
print("沿着第 1 维度的均值:", mean_dim1)
输出:
需要注意的是,torch.mean() 返回的是一个新的张量,而不是在原始张量上进行操作。
【注】:这里对0,1的解释是:
第0维度(轴)表示行,即沿着行的方向进行操作。在二维张量中,第0维度对应于沿着行的方向进行操作,例如计算每列的均值。
第1维度(轴)表示列,即沿着列的方向进行操作。在二维张量中,第1维度对应于沿着列的方向进行操作,例如计算每行的均值。
三、torch里面的逐点相乘和矩阵乘法
1. 逐点相乘 * 或torch.multiply()
a = torch.tensor([[2,3,1],
[4,5,1]])
b = torch.tensor([5,6,2])
print(torch.multiply(a,b))
输出:
2. 矩阵乘法
(1)torch.mm()
【注】:这个就是数学上严格的矩阵乘法,输入的必须必须都要是二维张量才行。向量都不行
a = torch.tensor([[2,3,1],
[4,5,1]])
b = torch.tensor([[5],[6],[2]])
print(torch.mm(a,b))
输出:
(2)torch.matmul() — 支持向量和更高维的矩阵乘法
维度不一致会采用专门的广播,注意别和逐点运算的那个广播机制混淆。两种广播机制不一样的是。
就是 np.matmul()再封装了,用法完全一样
a. 两个向量
a = torch.tensor([1,2,3])
b = torch.tensor([4,5,6])
print(torch.matmul(a,b),type(torch.matmul(a,b)))
输出:
b. 一个矩阵,一个向量
a = torch.tensor([[1,2],
[3,4]])
b = torch.tensor([4,5])
print(torch.matmul(a,b),type(torch.matmul(a,b)))
输出: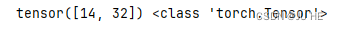
c. 两个矩阵
a = torch.tensor([[1,2],
[3,4]])
b = torch.tensor([[4,5],
[7,8]])
print(torch.matmul(a,b),type(torch.matmul(a,b)))
输出:
d. 高维
哈哈哈哈,乖乖看官方文档去吧。
四、pytorch自动微分
大家应该期待这个好久了吧!在之前学习数值分析的时候,或者最优化中是不是经常要手动计算梯度和导数呢?那简直是折磨,当时老师也没说导数梯度怎么用计算机算,哈哈哈没告诉你就是手算求出显示表达式在在代码里面封装成一个函数就能用了。是不是感觉好垃圾,最后还是不是我自己手算,要计算机有个屁用。------ 其实如果你发现了pytorch的自动微分就会发现真香,手算那还能叫编程吗,对吧。好了,吐槽就到这里了,开始正题。
1. torch.tensor(data, dtype=None, device=None, requires_grad=False)
前面是不是没有讲过requires_grad这个参数,因为这个参数就是和自动微分有关的,从英文名(需要梯度)每错就是这个字面意思,我需要梯度。默认是False,True就是需要梯度了
怎么解释呢?就是在tensor里面开辟了一个属性 .gard(类方法大家应该都知道)来存储对于的梯度。默认我记得应该里面都是0.
2. .gard :就是用来获取梯度的。
3. function.backward():反向传播计算梯度(反向传播计算导数的一个算法),向前传播就是你定义function的这个过程
【注】:在机器学习中我们只需要用到标量对向量(或矩阵)求梯度即可,因此这里的function大家理解成一个标量函数即可。当然pytorch肯定也支持矩阵对矩阵求偏导,这就不是我们的重点了,我们会标量对向量(矩阵)求梯度就够用了。
【注】pytorch里面反向传播计算梯度是累加的,因此在梯度更新参数时,每次都要清零梯度才能再次调用.backward();不然连续不清空梯度两次调用.backward()就会导致梯度是累加的。清零梯度方法如下:
4. tensor.grad.zero()_ : 将tensor的梯度清零。
另外还有一个很有用的语法,在训练模型的时候堆参数的tensor是需要梯度的,但当评估模型我们就不想要梯度参与计算了,不然会极大降低影响计算效率,因此我门可以采用以下语法将梯度移出计算过程:
5. with torch.no_grad(): 将代码块使用 with torch.no_grad(): 包装起来,停止跟踪历史记录(和使用内存),简单来讲就是不需要梯度了在这个计算过程中 (重要!!!!!,今后实例中就会发现怎么用了)
是不是感觉还是一头雾水,在所什么啊!当然,需要一定的数学求梯度基础,不需要你会手算,只要你有这个概念,看完下面的代码示例就能理解我上面在bb什么了。
(1). 示例1(简单例子):
# 创建一个存参数的 tensor,并分配一个存梯度的空间给它
w = torch.tensor([[1.,2],[3,4]],requires_grad=True)
print(w)
print(w.grad)
输出:
这里梯度默认是None啊,之前记错了,不是0
# 定义一个关于 w 的标量函数,只要 w 里面元素参与了运算就会是一个关于 w 的函数
# 有了函数我们就可以对w进行求导
function = w.sum()
# 反向传播求梯度
function.backward()
print(w.grad)
输出:
为什么会输出这么个东西呢?这就需要数学来解释了
w = torch.tensor([[1.,2],[3,4]],requires_grad=True)这行在数学上就是给了一个函数上的点,抽象成数学语言就是自变量(参数)为
w
=
[
w
1
w
2
w
3
w
4
]
\mathbf{w}=\begin{bmatrix} &w_1 &w_2 \\ &w_3 &w_4 \end{bmatrix}
w=[w1w3w2w4]
function = w.sum()这一行就相当于定义了一个标量函数
f
(
w
1
,
w
2
,
w
3
,
w
4
)
=
w
1
+
w
2
+
w
3
+
w
4
f(w_1,w_2,w_3,w_4)=w_1+w_2+w_3+w_4
f(w1,w2,w3,w4)=w1+w2+w3+w4
因此在具体的
w
w
w这个tensor处求偏导就是:
∂
f
∂
w
∣
w
=
[
1
2
3
4
]
=
[
∂
f
∂
w
1
∂
f
∂
w
2
∂
f
∂
w
3
∂
f
∂
w
4
]
∣
w
=
[
1
2
3
4
]
=
[
1
1
1
1
]
\frac{\partial f}{\partial \mathbf{w} } \mid_{\mathbf{w}=\begin{bmatrix} &1 &2 \\ &3 &4 \end{bmatrix} }=\begin{bmatrix} &\frac{\partial f}{\partial w_1} &\frac{\partial f}{\partial w_2} \\ &\frac{\partial f}{\partial w_3} &\frac{\partial f}{\partial w_4} \end{bmatrix}|_{\mathbf{w}=\begin{bmatrix} &1 &2 \\ &3 &4 \end{bmatrix} }=\begin{bmatrix} &1 &1 \\ &1 &1 \end{bmatrix}
∂w∂f∣w=[1324]=[∂w1∂f∂w3∂f∂w2∂f∂w4∂f]∣w=[1324]=[1111]
(2) 示例2(稍微复杂点例子)
# 创建一个存参数的 tensor,并分配一个存梯度的空间给它
w = torch.tensor([[1.,2],[3,4]],requires_grad=True)
# 定义一个关于 w 的标量函数,只要 w 里面元素参与了运算就会是一个关于 w 的函数
# 有了函数我们就可以对w进行求导
function = torch.mean(w*w)
# 反向传播求梯度
function.backward()
print(w.grad)
输出:
同样我们数学上解释一下为什么是这个结果:
自变量还是:
w
=
[
w
1
w
2
w
3
w
4
]
\mathbf{w}=\begin{bmatrix} &w_1 &w_2 \\ &w_3 &w_4 \end{bmatrix}
w=[w1w3w2w4]
标量函数相当于是:
f
(
w
1
,
w
2
,
w
3
,
w
4
)
=
m
e
a
n
[
w
1
2
w
2
2
w
3
2
w
4
2
]
=
1
4
(
w
1
2
+
w
2
2
+
w
3
2
+
w
5
2
)
f(w_1,w_2,w_3,w_4)=mean\begin{bmatrix} &w_1^2 &w_2^2 \\ &w_3^2 &w_4^2 \end{bmatrix}=\frac{1}{4} (w_1^2+w_2^2+w_3^2+w_5^2)
f(w1,w2,w3,w4)=mean[w12w32w22w42]=41(w12+w22+w32+w52)
求导后就是:
∂
f
∂
w
∣
w
=
[
1
2
3
4
]
=
[
1
2
w
1
1
2
w
2
1
2
w
3
1
2
w
4
]
∣
w
=
[
1
2
3
4
]
=
[
0.5
1
1.5
2
]
\frac{\partial f}{\partial \mathbf{w} } \mid_{\mathbf{w}=\begin{bmatrix} &1 &2 \\ &3 &4 \end{bmatrix} } =\begin{bmatrix} &\frac{1}{2}w_1 &\frac{1}{2}w_2 \\ &\frac{1}{2}w_3 &\frac{1}{2}w_4 \end{bmatrix}\mid_{\mathbf{w}=\begin{bmatrix} &1 &2 \\ &3 &4 \end{bmatrix} }=\begin{bmatrix} &0.5 &1 \\ &1.5 &2 \end{bmatrix}
∂w∂f∣w=[1324]=[21w121w321w221w4]∣w=[1324]=[0.51.512]
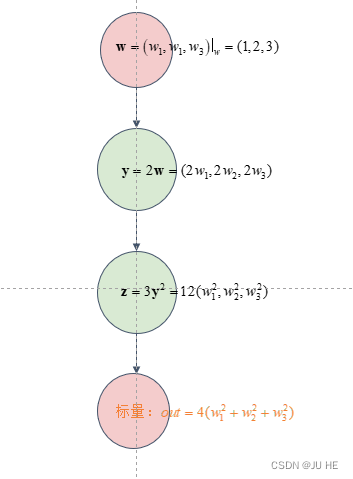
(3)示例3: 计算图
计算图在pytorch自动微分里面我感觉还是有必要粗略了解一下的,不然有写概念会混淆。计算图我更喜欢用数学语言叫它为复合函数,实际上的确也是复合函数。还记得function.backward()反向传播计算梯度吗,function是一个标量,同时function也是一个tensor,是不是只要是标量tensor就都能调用.backward()呢?当然不是,只有在计算图中除根节点外其他的标量tensor才能调用。这句话什么意思,下面会给出解释。
# 计算图根节点
w = torch.tensor([1.,2,3],requires_grad=True)
print(w)
输出:
注意到我标红的地方,表示已经分配空间存其grad了
# 创建计算图子节点,相当于已经是第一层函数了
y = w * 2
print(y)
输出:
可以看到出现了grad_fn属性表面其已经被计算机认为是一个y关于w的函数(因为y是w运算生成的),那么说明其如果是标量就可以调用.backward()计算偏导了,但它目前并不是标量,所以不能求偏导,所以只能算计算图的一部分,下面继续往下看
#第三层、第四层计算图(节点)
z = y * y * 3
out = z.mean()
print(f'第三层计算图:{z}')
print(f'第四层计算图(标量输出层):{out}')
print(out)
输出:
# 反向传播计算计算图梯度
out.backward()
print(w.grad)
输出:
下面用一张图表示上面计算图的过程就更好理解了:
(4)示例4:pytorch梯度累加的解释(用梯度下降的例子说明—特别重要)
【注】:本例在深度学习里面极其重要,会解决掉一些特别需要注意的bug,还好进一步加深你对pytorch自动微分的那几个方法函数的理解。本例解决了,pytorch最大的难关就基本没了。
a.对pytorch梯度累加的理解和pytorch里面梯度下降模版
## 对pytorch梯度累加的理解
w = torch.tensor([1., 2., 3.], requires_grad=True)
# 定义一个函数 f
def f(x):
return torch.sum(x ** 2)
# 计算梯度
f(w).backward()
# 打印梯度
print(f'w更新前的梯度{w.grad}')
with torch.no_grad():
w -= 0.01 * w.grad / 10
# 梯度清零
w.grad.zero_()
f(w).backward()
print(f'w更新后的梯度{w.grad}')
输出:
如果注释掉梯度清零w.grad.zero_()会输出: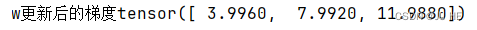
应该发现了,就是前面两个累加,这就是pytorch梯度累加这个名词的由来。
下面这个注释是一些特别注意的地方,后面有些bug就是这些注
【注1】:with torch.no_grad(): 语法就是将下面操作移出计算图,也就是所在里面进行的梯度更新w -= 0.01 * w.grad / 10 中的w不加入复合函数中,w只保持原有的requires_grad=True,没有grad_fn属性,简单来说就是更新后的w不能调用 .backward()。这是很重要的一件事情,不然就破坏了计算图。
【注2】:w -= 0.01 * w.grad / 10 中 -=(原地操作)和=(非原地,赋值一个新对象)w =w- 0.01 * w.grad / 10 会导致将计算图中原始的跟节点参数tensor w放到一个新地址,那么显然计算图就又崩了。解决办法是使用 -= 或者 w.data =w- 0.01 * w.grad / 10(以前看见过不少大神这样写还不理解哈哈)
【注3】:在进行参数w梯度更新时,必须先进行一次.backward()反向传播,不然w.grad是None,会导致w.grad.zero_()中w.grad没有.zero_()方法,然后报错。
b. 参数梯度更新需要移出计算图(bug演示)
## 对pytorch梯度累加的理解
w = torch.tensor([1., 2., 3.], requires_grad=True)
# 定义一个函数 f
def f(x):
return torch.sum(x ** 2)
# 计算梯度
f(w).backward()
# 打印梯度
print(f'w更新前的梯度{w.grad}')
# with torch.no_grad():
# w -= 0.01 * w.grad / 10
# # 梯度清零
# w.grad.zero_()
w -= 0.01 * w.grad / 10
# 梯度清零
w.grad.zero_()
f(w).backward()
print(f'w更新后的梯度{w.grad}')
输出:
报错显示在计算图中对跟节点w原地操作添加计算图,自动微分不可靠。
c. 使用 w =w- 0.01 * w.grad / 10不是原地操作,将w赋值到一个新地址破坏了计算图(bug演示)
## 对pytorch梯度累加的理解
w = torch.tensor([1., 2., 3.], requires_grad=True)
# 定义一个函数 f
def f(x):
return torch.sum(x ** 2)
# 计算梯度
f(w).backward()
# 打印梯度
print(f'w更新前的梯度{w.grad}')
with torch.no_grad():
w = w- 0.01 * w.grad / 10
# 解决办法,使用 -= 或者 w.data = w- 0.01 * w.grad / 10
# 梯度清零
w.grad.zero_()
f(w).backward()
print(f'w更新后的梯度{w.grad}')
输出: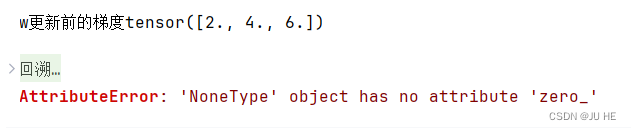
在深度学习中,通常会使用自动微分来计算梯度,以便对模型参数进行优化。这种自动微分通常通过构建一个计算图来实现,计算图记录了模型的前向传播过程,并且能够根据反向传播算法计算出梯度。在 PyTorch 中,张量对象上的操作会构建计算图,从而使得可以通过调用 .backward() 方法来计算梯度。然而,有时候我们需要手动更新模型参数,比如使用随机梯度下降算法。为了避免在参数更新过程中影响计算图和梯度计算,通常会在更新参数时使用 torch.no_grad() 上下文管理器,以防止计算梯度或者破坏计算图。但是,如果在更新参数时重新赋值了原始的参数,就可能会导致原始的参数对象和计算图中的参数对象不再指向同一个对象,从而破坏了计算图。这意味着,即使在 torch.no_grad() 上下文管理器中进行了更新操作,也无法保证更新后的参数对象和计算图中的参数对象是同一个,可能会导致意外的行为或错误。因此,为了避免这种情况,通常建议在更新参数时直接对参数对象进行操作,而不是重新赋值。这样可以确保参数对象仍然与计算图中的参数对象相同,不会破坏计算图的结构。
d. 进行参数w梯度更新时,必须先进行一次.backward()反向传播,不然w.grad是None,会导致w.grad.zero_()中w.grad没有.zero_()方法,然后报错。(bug演示)
## 对pytorch梯度累加的理解
w = torch.tensor([1., 2., 3.], requires_grad=True)
# 定义一个函数 f
def f(x):
return torch.sum(x ** 2)
# # 计算梯度
# f(w).backward()
# 打印梯度
print(f'w更新前的梯度{w.grad}')
with torch.no_grad():
w.data = w- 0.01 * w.grad / 10
# 梯度清零
w.grad.zero_()
f(w).backward()
print(f'w更新后的梯度{w.grad}')
输出:
好了,上面的内容是我个人学习中碰到的,在这里总结一下。
好了,看到这里,恭喜你,以后在也不用为了求导数而头疼了!这是一项很实用的技术。
总结
就介绍到这里吧。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









