







一、相关概念:
1、隐语义模型(LFM)
通过矩阵分解建立用户和隐类之间的关系,物品和隐类之间的关系,最终得到用户对物品的偏好关系。
假设我们想要发现 F 个隐类, 我们的任务就是找到两个矩阵 U 和 V,使这两个矩阵的乘积近似等于R,即将用户物品评分矩阵 R 分解成为两个低维矩阵相乘,然后定义损失函数,利用随机梯度下降法处理损失函数,求出U和V。
隐语义模型具有以下特点:
(1)从数据出发,进行个性化推荐。
(2)隐含因子表达了用户和物品之间的联系。
(3)隐含因子让计算机能理解就好。
(4)将用户和物品通过中介隐含因子联系起来。
利用隐语义模型主要解决了以下问题:
(1)分类的可靠性。分类来自对用户行为的统计,代表了用户对物品分类的看法。
(2)可控制分类的粒度。允许我们自己指定有多少个隐类。
(3)将一个物品多类化。通过统计用户行为来决定某物品在每个类中的权重。
2、隐语义模型中矩阵分解的基本思想:
矩阵分解的基本思想简单来说就是每一个用户和每一个物品都会有自己的一些特性,特性即可作为隐语义模型的隐含因子,用矩阵分解的方法可以从评分矩阵中分解出用户--特性矩阵,特性--物品矩阵,这样做的好处一是得到了用户的偏好和每件物品的特性,二是见底了矩阵的维度。图示如下:

以用户与电影间的关系进行举例:
每个用户看电影的时候都有偏好,这些偏好可以直观理解成:恐怖片,喜剧片,武侠片,爱情片等,称作电影特性。用户---特性矩阵表示的就是用户对这些因素(偏好)的喜欢程度,如下。

同样,每一部电影也可以用这些因素描述,因此特性--物品矩阵表示的就是每一部电影这些因素的含量,也就是电影的类型。这样子两个矩阵相乘就会得到用户对这个电影的喜欢程度。

矩阵分解的形式化描述:
由于评分矩阵的稀疏性(因为每一个人只会对少数的物品进行评分),因此传统的矩阵分解技术不能完成矩阵的分解,即使能分解,那样计算复杂度太高,不现实。因此通常的方法是使用已存在评分计算出预测误差(或代价函数),然后使用梯度下降算法调整参数使得误差(代价函数)最小。
物品的预测得分的计算公式:

(1)式中,戴帽子的 rui 表示预测用户 u 对物品 i 的打分,qi 表示物品 i 每个特性的归属度向量,pu 表示用户 u 对每个特性的喜欢程度的向量。
接下来需要根据已有的数据计算误差并修正 q 和 p 使得误差最小,误差(代价函数)的通常表示方式如下:
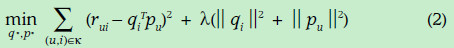
(2)式可以利用评分矩阵中存在的评分数据,通常使用随机梯度下降方法进行参数的优化,在此不做介绍。注意第二项是正则式,为防止过拟合。
以电影推荐系统为例:
式(2)中对应的代价函数的实际计算公式如下:

式中,X 与 θ 是上面所提到的特性-物品矩阵(电影内容矩阵)和用户-特性矩阵(用户喜好矩阵);J(X,θ) 即代表该方法的代价函数(误差);r 是用户对电影的评分记录表(矩阵),在其中,具有评分的记录用1表示,没有则用0表示,故 r(i,j)=1 代表了一种过滤条件,即 j 用户对 i 电影具有评分;u 代表用户数量;θj 代表 j 用户的喜好向量(对不同类型电影的喜欢程度值),xi代表了 i 电影的内容(即一个电影的各个特征类型如喜剧片恐怖片等所占数值,如(0.2,0.2,0.4,0.1)^T),y(i,j) 是 j 用户对 i 电影的实际评分。
后面两项是正则化项,n 是特征数量即电影特性(喜剧片,爱情片等)的数量,m 是电影总数,u 是用户总数。
同理,![]() 即为 j 用户对 i 电影的评分预测值。
即为 j 用户对 i 电影的评分预测值。
二、Python推荐系统实战:
本实例使用MovieLens 数据集(下载地址:http://files.grouplens.org/datasets/movielens/ml-latest-small.zip,或者https://download.csdn.net/download/smart3s/10946693)中的ratings.csv(用户ID对电影ID的评分)以及movies.csv(电影类别明细)。如下:
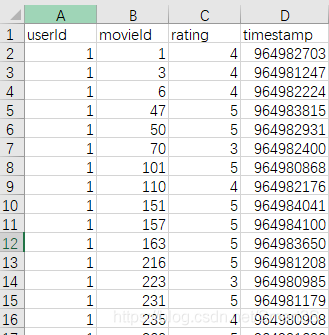
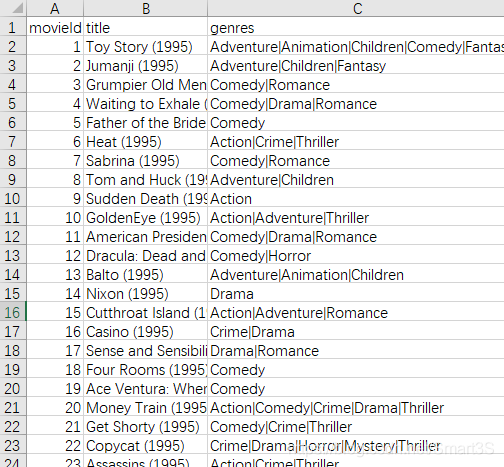
ratings.csv movies.csv
2、实现功能所需要的模块:
博主使用jupyter notebook进行python代码编写。
import pandas as pd
import numpy as np
import tensorflow as tf3、数据集准备与处理:
#读取用户评分矩阵
ratings_df=pd.read_csv('E:/ml-latest-small/ratings.csv')
#读取电影信息矩阵
movies_df=pd.read_csv('E:/ml-latest-small/movies.csv')
#在电影信息矩阵中添加行号(此步非必须,因为直接使用电影id的话
#由于id值过长,会降低算法性能,因此用行号代替)
movies_df['movieRow']=movies_df.index
#筛选movies_df中的特征
movies_df=movies_df[['movieRow','movieId','title']]
#存储至本地
movies_df.to_csv('E:/moviesProcessed.csv',index=False,header=True,encoding='utf-8')
#将ratings_df中的movieId替换为行号
ratings_df=pd.merge(ratings_df,movies_df,on='movieId')
ratings_df=ratings_df[['userId','movieRow','rating']] #筛选ratings_df中的特征
#存储至本地
ratings_df.to_csv('E:/ratingsProcessed.csv',index=False,header=True,encoding='utf-8')
#创建电影评分矩阵rating和评分记录矩阵record
userNo=ratings_df['userId'].max()+1 #用户最大数量,考虑到id可能从0开始,故+1
movieNo=ratings_df['movieRow'].max()+1 #电影最大数量,同上
#创建电影评分矩阵矩阵rating
rating=np.zeros((movieNo,userNo))#先创建空矩阵
#进行rating矩阵的填充
flag=0 #记录处理进度
ratings_df_length=np.shape(ratings_df)[0] #ratings_df的样本个数,即行数
for index,row in ratings_df.iterrows():
rating[int(row['movieRow']),int(row['userId'])]=row['rating']
flag+=1
print('processed %d , %d left' %(flag,ratings_df_length-flag))
#创建评分记录矩阵record,含有评分记录为1,否则为0
record=rating>0 #出来的是布尔值矩阵
record=np.array(record,dtype=int)#布尔值转整型值阶段结果(矩阵显示了部分结果):
movies_df 矩阵: ratings_df 矩阵:


rating矩阵: 即用户(每一行)对电影(每一列)的评分。 record矩阵:有评分为1,无评分为0。


4、标准化处理:
#标准化处理方法
def normalizeRatings(rating,record):
m,n=rating.shape #将矩阵的行列数赋给m和n
rating_mean=np.zeros((m,1))
rating_norm=np.zeros((m,n))
for i in range(m):
idx=record[i,:]!=0 #每部电影评分用户的下标
rating_mean[i]=np.mean(rating[i,idx]) #第i部电影评过分的用户的评分的平均值
rating_norm[i,idx]-=rating_mean[i]
return rating_norm,rating_mean
#调用标准化处理方法
rating_norm,rating_mean=normalizeRatings(rating,record)注,运行该部分代码会报警告:

不影响程序运行无需理会,原因是因为np.mean在求均值时出现了全是0的情况,求出的结果是NAN,所以还需要将NAN转成0值进行处理。
#因为计算多个0的平均值结果是NAN,所以需要将NAN转成0
rating_norm=np.nan_to_num(rating_norm)
rating_mean=np.nan_to_num(rating_mean)5、对电影内容矩阵(特性-物品矩阵)X 和用户喜好矩阵(用户-特性矩阵) θ 的处理:
由于本文并未取得 X 和 θ 的数据,因此采用生成正态随机数的方式:
#随机初始化电影内容矩阵X 用户喜好矩阵θ
num_features=10 #假设有10种类型的电影
#生成正态随机数,stddev是正态分布的标准差
X_parameters=tf.Variable(tf.random_normal([movieNo,num_features],stddev=0.35))
Theta_parameters=tf.Variable(tf.random_normal([userNo,num_features],stddev=0.35))6、构建模型:
#代价函数定义(乘record是为将没有评分的电影用0代替)
loss=1/2*tf.reduce_sum(((tf.matmul(X_parameters,Theta_parameters,transpose_b=True)-rating_norm)*record)**2+1/2*(tf.reduce_sum(X_parameters**2)+tf.reduce_sum(Theta_parameters**2)))
#训练模型
optimizer=tf.train.AdamOptimizer(1e-4)#使用Adam优化器并将学习速率设置为10^-4
train=optimizer.minimize(loss)#以使代价函数值最小的目标进行训练
tf.summary.scalar('loss',loss) #训练可视化定义
summaryMerged=tf.summary.merge_all()#将所有summary信息汇总
filename='E:/movie_tensorboard'
writer=tf.summary.FileWriter(filename) #把训练信息保存到文件当中
#创建tensorflow会话
sess=tf.Session()
init=tf.global_variables_initializer()#初始化
sess.run(init)
#开始训练模型,训练5000次
for i in range(5000):
#记录每次loss变化,train到_,summaryMerged到movie_summary
_,movie_summary=sess.run([train,summaryMerged])
writer.add_summary(movie_summary,i)若要查看训练过程信息,则需使用以下步骤:
(1)打开cmd,通过cd指令进入存储训练信息的文件夹,本例为E盘的movie_tensorboard文件夹。
(2)输入指令:tensorboard --logdir=./
运行结果如下:
![]()
(3)打开浏览器,输入网址 http://localhost:6006 即可查看训练结果即loss数值的变化图(时间原因只展示500次训练图)。

7、若要对模型进行评估,则使用:
#评估模型
Current_X_parameters,Current_Theta_parameters=sess.run([X_parameters,Theta_parameters])
predicts=np.dot(Current_X_parameters,Current_Theta_parameters.T) +rating_mean
errors=np.sqrt(np.sum((predicts-rating)**2))8、构建完整的推荐系统:
#构建完整的电影推荐系统
user_id=input('您要向那位用户进行推荐?请输入用户编号:')
#获取对该用户的预测电影评分列表,按照从大到小排序(argsort()从小到大排序,[::-1],逆转)
sortedResult=predicts[:,int(user_id)].argsort()[::-1]
idx=0
print('为该用户推荐的评分最高的20部电影是:'.center(80,'=')) #一种字符串格式化输出形式
for i in sortedResult:
print('评分:%.2f,电影名:%s'%(predicts[i,int(user_id)],movies_df.iloc[i]['title']))
idx+=1
if idx==20:break #输出前20个推荐结果运行结果:

三、参考资料:
(1)https://blog.csdn.net/lissanwen/article/details/51214275
(2)https://blog.csdn.net/qq_19446965/article/details/82079367
(3)https://blog.csdn.net/weixin_41362649/article/details/82848132
(4)https://blog.csdn.net/m0_37788308/article/details/78846429
(5)https://www.imooc.com/learn/990
(6)王升升, 赵海燕, 陈庆奎, et al. 个性化推荐中的隐语义模型[J]. 小型微型计算机系统, 2016, 37(5):881-889.
(7)徐梦锦, 赵晓东. 基于隐语义模型的协同过滤推荐研究[J]. 电脑知识与技术, 2016, 12(7).














 4052
4052











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









