







原论文:1-Bit Stochastic Gradient Descent and its Application to Data-Parallel Distributed Training of Speech DNNs
该文的核心思想就是将32位单精度浮点数压缩成1位,从而降低训练过程的数据交换开销。为了进一步降低通信开销,作者设定在节点间只进行梯度的交换,不进行模型参数的交换。为了降低量化误差带来的负面影响,作者使用了误差补偿技术:每次量化时,把上一次迭代的量化误差加到本次迭代的梯度上,然后再进行量化,接着求出本次量化操作的误差。这种误差补偿机制可以确保所有的梯度都会再一定程度上对模型更新产生作用,只不过这种作用分散在不同的迭代中——类似于一种延迟更新的形式。作者指出,使用误差补偿后,就可以在几乎不损失模型精度的情况下将梯度由32位量化成1位。
在具体实现上,一种比较简单(且有效)的方法是将大于0的梯度值编码位1,小于等于0的梯度值编码为0。在反量化(解码)时,将1解码为+1,将0解码为-1,再进行聚合与更新操作。
(使用Ring-AllReduce是不行的;这里使用的是Shuffle-AllReduce,也就是:N台机器,每台把自己的梯度分成N份,
第1轮所有机器向id+1那台机器发送第id份,
第2轮所有机器向id+2那台机器发送第id份,
...
N-1次之后,每个机器上拿到第id份的N份量化值,进行反量化,加和,再次量化(保存下来误差),广播给其他节点)
对一个node而言:
它的量化前的梯度+其他节点发过来的量化后的梯度经反量化后的数值之和+误差=本次所有节点量化后经反量化再加和再量化对应的反量化数值;
由上,得到它的本轮误差;
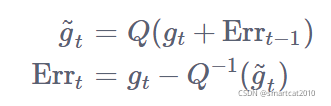
一种使用1-bit通信的Adam优化器 - 知乎 (zhihu.com)
论文:《1-bit Adam: Communication Efficient Large-Scale Training with Adam's Convergence Speed》
误差补偿的作用:(把上一个mini-batch里,多加或者少加的量,在本轮补加上)
Adam的二阶冲量项Vt,是量化压缩的障碍;
伪Adam算法:将导致Adam非线性依赖于梯度的Vt量变成一个常数,此时Adam退化为Momentum SGD,变成线性依赖于梯度的,并可以和压缩误差补偿结合使用。
观察得到:Vt在训练刚开始的较少步数之后,其变化趋势会变得稳定;
1-bit Adam算法分为以下两个阶段:
Warmup阶段(阶段1),此时运行原来的Adam,不对通信做压缩,当我们检测到vt变化趋势稳定后,再切换到压缩阶段(阶段2),在这个过程中,停止更新vt,并会把mt项进行压缩,同时进行误差补偿。
需要15%~25%的训练步数作为Warmup
注意:每个rank上,有一个量化误差;master上,还有一个量化误差;
通信实现:Seide的方法(这里的All-to-All,实际可用Shuffle-AllReduce实现)
我:如果使用ZeRO,则只有Gradient的Reduce-Scatter这步,会利用上1-bit量化的通信量优化;不会再需要Reduced Gradient进行广播的步骤;每个rank用自己own的Gradient更新完自己的optimizer和weights后,把weights(FP16)广播至所有rank;




0/1 Adam
1. adaptive variance state freezing:
原始版Adam,每轮要把g^2,在所有rank进行加和;占用通信量;
0/1 Adam要在一段steps上冻结这个加和,等g^2积累到一定程度,再通信一次;
2. 1-bit sync
每个rank,将local g积累过一定bar之后,才通信1个bit;

















 178
178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









