






一、Semantic-Segment-Anything(SSA)简介
详见博客(因为未知是否有权限可以发布):
人工标注或成过去式?SSA语义分割框架、SSA-engine自动类别标注引擎,大幅提升细粒度语义标注效率_semantic segment anything-CSDN博客
二、环境配置
本篇教程在windows下实现SSA的环境配置:
1、创建虚拟环境
这里的逻辑是:先将虚拟环境创建成功、再运行代码安装缺少的包
创建虚拟环境:先将包中==后的数字字母去掉,那是在作者本机上运行环境的机器包序列号之类的,相当于导出了作者自己的环境,我们创建环境的时候套用的话会不一致,所以将其删掉。
然后运行:
conda env create -f environment.yaml
conda activate ssa创建虚拟环境后查看是否创建成功, 若不成功,请重复以上步骤(特别是去掉包的序列号)
若成功,运行主代码,根据报错提示安装相应的包:
根据官方requirements.txt里的环境,SSA是在linux下进行的环境配置。要在windows环境下安装包,首先找到windows相应的whl,如这个安装的地址改成:https://download.pytorch.org/whl/cu111/torch-1.9.1%2Bcu111-cp38-cp38-win_amd64.whl
以此类推安装相应的whl,其他包根据报错提示进行安装,注意对应版本,比如我当时安装的时候在mmcv的安装版本上花了一些时间
2、下载SA模型
github地址:
然后将其放到SSA子目录下即可
三、ssa_main.py推理代码运行
windows下,nccl模式改为gloo模式,代码开头加上:
os.environ["PL_TORCH_DISTRIBUTED_BACKEND"] = "gloo"并且将主函数这里的nccl也改为gloo:
![]()
从hugging face下载模型时连接不上:换网(一般都是网络问题,多换几个节点或者换个vpn试试)或下载到本地,改路径为本地,如:

然后就可以推理和评估了,根据需要应用的不同数据集对代码进行微调即可,我用的是cityscapes数据集,评估时需要先下载cityscapes数据集中的createTrainIdLabelImgs.py生成用于语义分割的以xxx_labelTrainIds.png结尾的图片数据文件,否则会报错。
推理与评估命令详见简介中的博客或github
效果(使用自己的数据):

原图

结果图
四、evaluation.py评估代码运行
评估命令详见简介中的博客或github
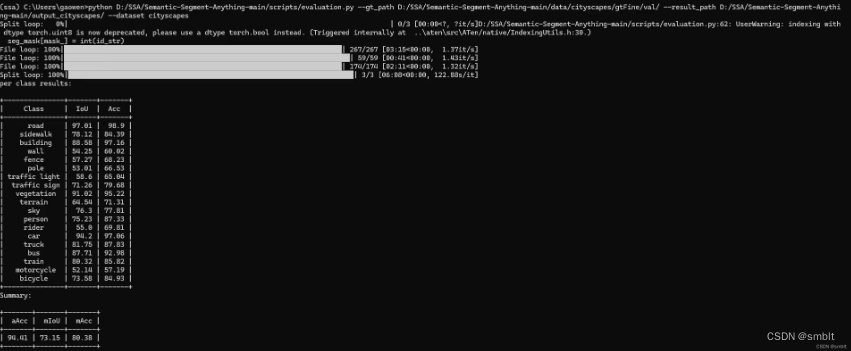
评估结果(评估cityscapes数据集为例):
五、ssa_main_engine.py推理代码运行
注意的点:
1、与ssa_main.py运行基本类似,nccl改为gloo模式
2、使指定在GPU上运行,修改if.args.sam后的代码为;
#改动:指定到GPU上
device = 'cuda' if torch.cuda.is_available() else 'cpu'
sam = sam_model_registry["vit_h"](checkpoint=args.ckpt_path).to(device)效果(使用自己的数据):
原图
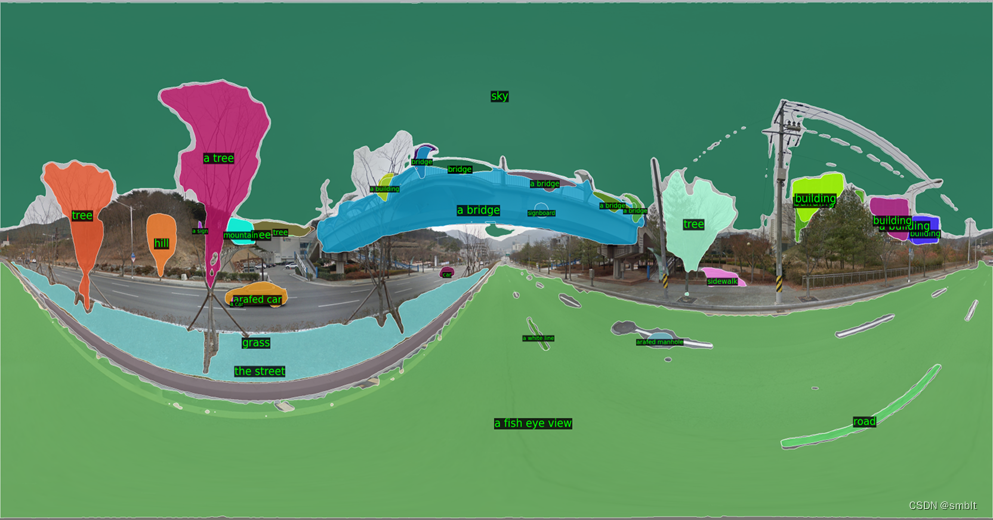
结果图
六、总结
SAM是一种强大的图像分割模型,但缺乏为每个mask预测语义类别的能力。因此提出一个基于SAM的语义分割框架SSA。本博客实验使用segformer B5模型,训练数据集通过统计,包含cocostuff、cityscapes和ade20k等数据集,类别丰富,因此能准确地分割mask、预测每个mask的语义类别
SSA也可以作为一个自动化的稠密开放词汇标注引擎,称为 SSA-engine,为任何其他数据集提供丰富的语义类别注释。该引擎显著减少了人工注释及相关成本的需求。通过对SSA-engine的训练数据集进行统计,其中类别极多、包含丰富的图文多模态样本,因此能提供丰富的语义注释。
经过实验,分割效果以及注释效果在目视情况下还是比较好的,但由于自己的数据集没有制作真实的分割标签,因此暂时没有对其进行分割精度的评估,在后续的实验中,本人也将根据实验精度对自己后续研究的影响再对这篇博客进行更新与解释
感谢您看到这里,这是我的第一篇博客,在整个模型到应用的这个阶段虽然深受折磨,但是运行成功的感觉让自己觉得一切都值得。当然这其中还存在很多不足,后续会虚心学习、继续改进,也欢迎大家批评与讨论,一切都是为了学到更多,加油!















 995
995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









