







系列文章目录
二,pandas之聚合函数agg的使用
文章目录
前言
在pandas中, 为了统一计算多列数据的不同值不如求和,计数,最大值,最小值,中位数,平均值等,引入agg聚合函数,agg和aggregate两个函数指向同一个方法,使用时写任意一个即可。
一、pandas是什么?
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
二、使用步骤
1.引入库
代码如下:
import numpy as np
import pandas as pd
2.读入数据
agg前的DataFrame数据new_nor_sum2_df, debug一下展示数据结构如下:
3.统计相同'的代发薪公司'的数据,各列求和汇总
代码如下:
new_nor_sum2_group = new_nor_sum2_df[
~new_nor_sum2_df[('发薪公司', '')].str.endswith('小计')].groupby(
[('代发薪公司', '')]).agg(
{('中国籍', '人数'): 'sum', ('中国籍', '工资个税'): 'sum', ('非中国籍', '人数'): 'sum',
('非中国籍', '工资个税'): 'sum',
('合计', '人数'): 'sum', ('合计', '工资个税小计'): 'sum'})分三大步:
(1)筛选出new_nor_sum2_df中不以"小计"两个字结尾的"发薪公司"的数据,因为带有"小计"尾缀的数据针对具有相同"代申报公司"数据的求和,不应该计入总计.如下图所示的
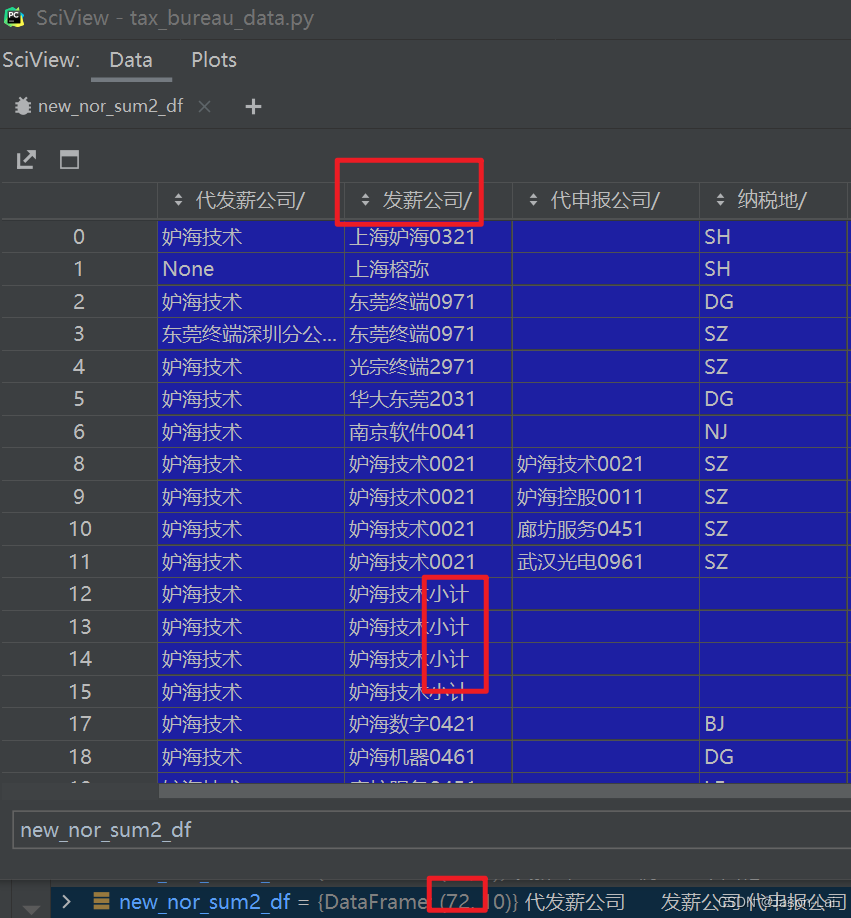
筛选前有72条数据
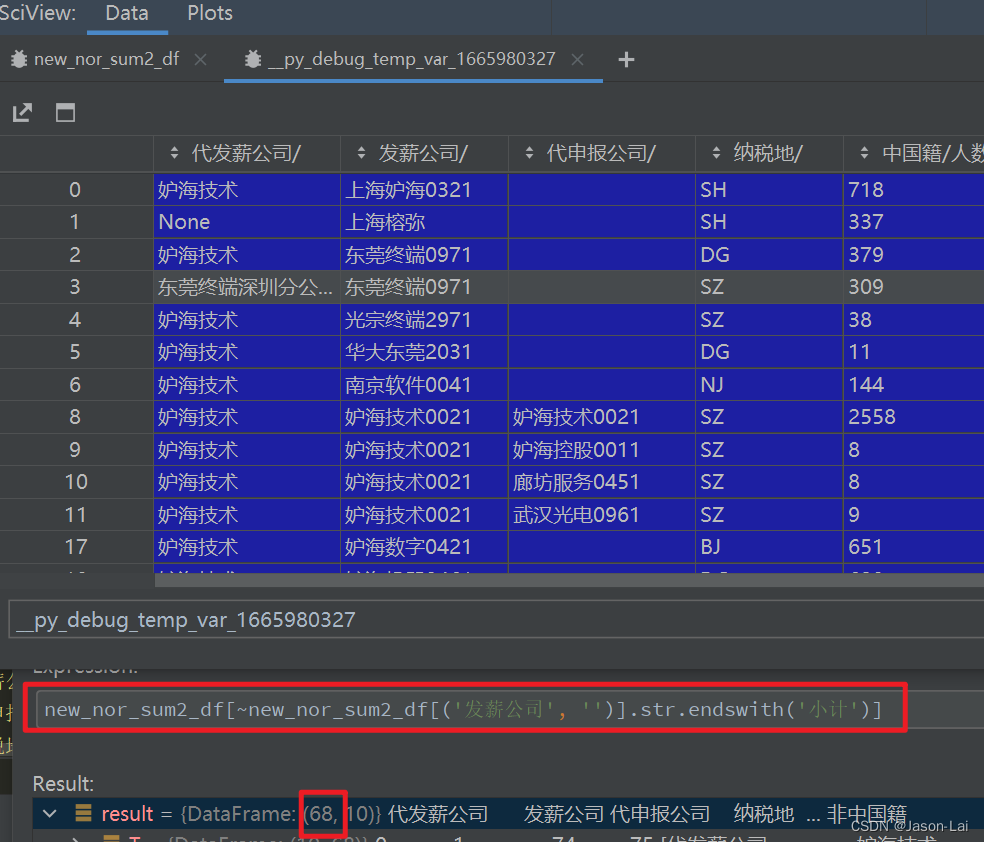
筛选后有68条数据
(2)按照"代发薪公司"的不同用groupby进行分组;
new_nor_sum2_df[
~new_nor_sum2_df[('发薪公司', '')].str.endswith('小计')].groupby(
[('代发薪公司', '')])(3)groupby分组后接上agg聚合函数,写入每列的统计方法时用大括号括起来
聚合的方法有: 计数count,求和sum,最大值max,最小值min平均值mean,中位数median等
new_nor_sum2_group = new_nor_sum2_df[
~new_nor_sum2_df[('发薪公司', '')].str.endswith('小计')].groupby(
[('代发薪公司', '')]).agg(
{('中国籍', '人数'): 'sum', ('中国籍', '工资个税'): 'sum', ('非中国籍', '人数'): 'sum',
('非中国籍', '工资个税'): 'sum',
('合计', '人数'): 'sum', ('合计', '工资个税小计'): 'sum'})4.聚合后的group对象的数据在前面新增4列("代发薪公司",'发薪公司','代申报公司', '纳税地'),'发薪公司'的值为'总计'
new_nor_sum2_group.insert(0, "代发薪公司", list(new_nor_sum2_group.index))
new_nor_sum2_group.insert(1, '发薪公司', '总计')
new_nor_sum2_group.insert(2, "代申报公司", '')
new_nor_sum2_group.insert(3, "纳税地", '')
new_nor_sum2_df = new_nor_sum2_df.append(new_nor_sum2_group)5.对各个要统计的列进行求和
group_cn_per = new_nor_sum2_group[('中国籍', '人数')].sum() # 中国籍'人数'总和
group_cn_tax = new_nor_sum2_group[('中国籍', '工资个税')].sum() # 中国籍'工资个税'总和
group_ncn_per = new_nor_sum2_group[('非中国籍', '人数')].sum() # 非中国籍'人数'总和
group_ncn_tax = new_nor_sum2_group[('非中国籍', '工资个税')].sum() # 非中国籍'工资个税'总和
group_total_per = new_nor_sum2_group[('合计', '人数')].sum() # 合计'人数'总和
group_total_tax = new_nor_sum2_group[('合计', '工资个税小计')].sum() # 合计'工资个税小计'总和最后,把该group对象的所有值放回到原来的new_nor_sum2_df中
new_nor_sum2_df = pd.DataFrame(
np.insert(new_nor_sum2_df.values, len(new_nor_sum2_df.index),
values=new_nor_sum2_group, axis=0))debug一下展示效果

因为篇幅原因,若展示全图,CSDN显示会模糊,故展示部分图片
总结
使用agg聚合函数进行统计各种类型的值时,先要进行groupby分组操作,按照需要统计的某一个维度(某一列)统一进行聚合计算(count,sum,max.mean等)















 2139
2139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









