







sqoop作为很常用的数据同步工具,用于RDBMS和HDFS的数据迁移,但是不支持NoSql,比如说MongoDB,那如果我们需要同步mongoDB的数据到hive该怎么处理呢?下面提供下我的思路:
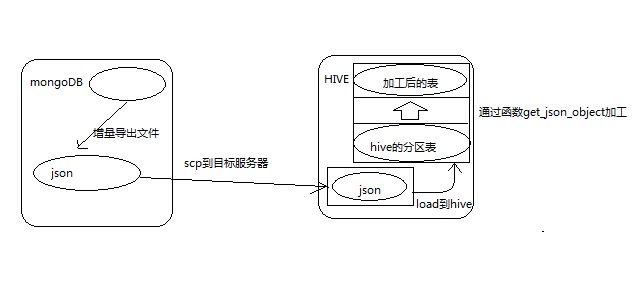
1.我先去查询了一下mongoDB可以导出数据为CSV格式或者json格式的文件,CSV是以逗号分隔的,这样可以直接把这个文件put到hdfs中然后load到hive,但是有个问题就是:如果数据本身就自带一个或者多个逗号,那么这样做就会造成字段错位的问题。那我们就可以使用生成json的这种文件。
2.然后了解了下mongoDB可以条件导出,那么就可以进行增量操作了,这样我们可以每次只导出增量的数据到文件中进行操作。
3.如果使用json这样的文件,那么数据就相当于在hive中只有一列,导入增量的话,我们可以每天或者每月、周(看需求)只导出增量的数据,那每次同步数据的时候都把这次的数据放到一个分区(第一次同步之前需要建立好分区表)可以以昨天的时间为分区字段,然后通过scp命令将文件发送到hive的客户端上(需要提前进行ssh免密码登录),然后通过调度器每天或者每月、周定时执行任务去把接受到的文件直接load到hive分区表中。
4.导入到hive表中之后,这个hive表只有1个主要字段以及分区字段,我们可以对这个表进行加工,将json解析成一个一个字段和值,可以通过hive的函数get_json_object(name,’$.xxxx’)解析,导入一个新表里面,新表的字段就是json中的key。
比如json格式如下:
{
"a1": "hehe",
"b1": "heihei",
"c1": {
"c2": "lala"
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
hive中解析如下:
select
get_json_object(name,'$.a1') as a1,
get_json_object(name,'$.b1') as b1,
get_json_object(get_json_object(name,'$.c2'</span>),<span class="hljs-string">'$.c1') as c2
from
table_name
- 1
- 2
- 3
- 4
- 5
- 6
其中有个注意点就是,怎么判断mongDB的数据已经导入到文件并发送过来?
其实可以在调度器上面配置一检查个任务,当到了定时执行同步任务的时候让同步任务依赖一个检查任务,检查任务就是去不断检查scp的文件传输过来没,如果没有过来间隔一段时间再去检查(时间自己配置),直到检查到数据来了,检查任务就结束,后面的同步任务就开始执行。
<link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/production/markdown_views-68a8aad09e.css">
</div>















 4172
4172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









