









我们现在数据湖产品,开发基本上都是大数据人员操作,能不能java 开发,比如用java web 开发在线创建表,创建分区,在线修改表字段。做数据湖Iceberg的元数据管理呢,因为我们大部分的表修改希望通过应用修改,并查看应用。
对java人员,最麻烦就是安装hadoop,hive,现在这个例子,不需要hadoop和hive,对Iceberg数据湖进行表管理开发。
网上找了一圈,没有java对iceberg的开发,自己实验完成的例子。
接下来将在window上,通过一个demo例子来实现java 版的iceberg开发和应用。
环境准备:
idea
java8
minio
winutils(hadoop.dll) 放在C:/windows/system32 下面
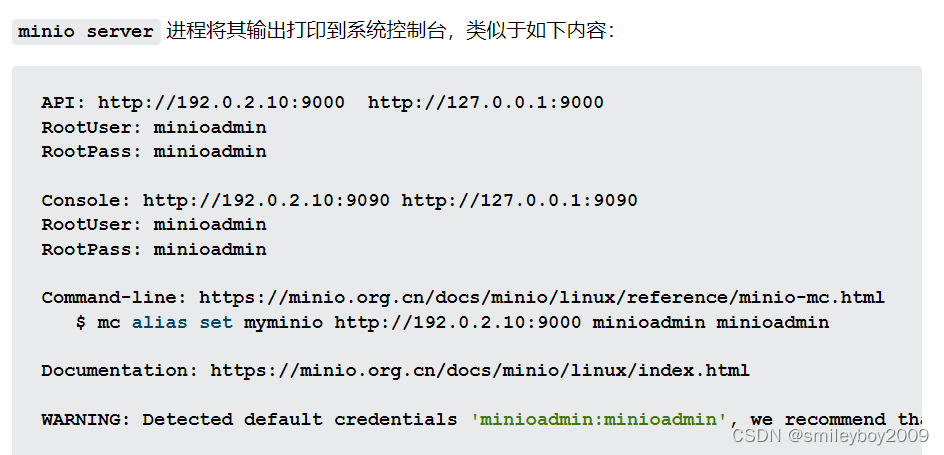
第一步:启动minio
window 下载minio ,通过cmd运行
.\minio.exe server C:\minio --console-address :9090
登录后创建一个buckets ,名字叫:datalake
第二步:idea配置pom文件
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-core</artifactId>
<version>1.4.2</version>
</dependency>
<dependency>
<groupId>io.minio</groupId>
<artifactId>minio</artifactId>
<version>8.5.7</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.amazonaws/aws-java-sdk-s3 -->
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>aws-java-sdk-s3</artifactId>
<version>1.12.620</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-aws</artifactId>
<version>3.2.2</version>
</dependency>maven包介绍:
iceberg-core :是iceberg 的核心包
minio:是minio的客户端
aws-java-sdk-s3:s3协议需要的sdk
hadoop-aws:是s3和hadoop转换包
第三步:进行java开发
配置iceberg Configuration
Configuration conf = new Configuration();
conf.set("fs.s3a.aws.credentials.provider"," com.amazonaws.auth.InstanceProfileCredentialsProvider,org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider,com.amazonaws.auth.EnvironmentVariableCredentialsProvider");
conf.set("fs.s3a.connection.ssl.enabled", "false");
conf.set("fs.s3a.endpoint", "http://127.0.0.1:9000");
conf.set("fs.s3a.access.key", "minioadmin");
conf.set("fs.s3a.secret.key", "minioadmin");
conf.set("fs.s3a.path.style.access", "true");
conf.set("fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem");
conf.set("fs.s3a.fast.upload", "true");创建HadoopCatalog
String warehousePath = "s3a://datalake/";//minio bucket 路径
System.out.println(warehousePath);
HadoopCatalog catalog = new HadoopCatalog(conf, warehousePath);定义表
TableIdentifier name = TableIdentifier.of("logging", "logs");定义表结构
// 定义表结构schema
Schema schema = new Schema(
Types.NestedField.required(1, "level", Types.StringType.get()),
Types.NestedField.required(2, "event_time", Types.TimestampType.withZone()),
Types.NestedField.required(3, "message", Types.StringType.get()),
Types.NestedField.optional(4, "call_stack", Types.ListType.ofRequired(5, Types.StringType.get()))
);定义表分区
// 分区定义(以birth字段按月进行分区)
PartitionSpec spec = PartitionSpec.builderFor(schema)
.hour("event_time")
.identity("level")
.build();
添加表熟悉
Map<String, String> properties = new HashMap<String, String>();
properties.put("engine.hive.enabled", "false");创建表
Table table = catalog.createTable(name, schema, spec);修改表结构
table.updateSchema()
.addColumn("count", Types.LongType.get())
.commit();运行效果如下:
查看表是否已经存在minio
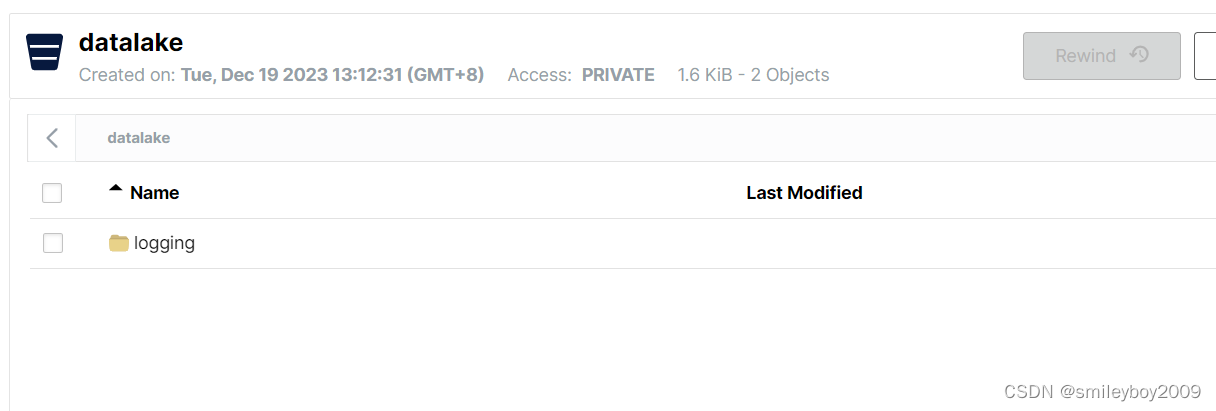
通过java 对表的catalog进行定义,可以利用flink,spark,presto等工具进行批量实时处理,可以实现完整的一个数据湖系统,如果通过web构建一个对表管理的产品,数据湖才能真正实现湖的治理工作。java 也可以写入数据,这里不再演示,官网有介绍。
附带完整例子:
pom.xml 定义
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>gbicc.net</groupId>
<artifactId>data-lake</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.13</artifactId>
<version>3.5.0</version>
</dependency>
<dependency>
<groupId>io.delta</groupId>
<artifactId>delta-spark_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.iceberg/iceberg-core -->
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-core</artifactId>
<version>1.4.2</version>
</dependency>
<dependency>
<groupId>io.minio</groupId>
<artifactId>minio</artifactId>
<version>8.5.7</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.amazonaws/aws-java-sdk-s3 -->
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>aws-java-sdk-s3</artifactId>
<version>1.12.620</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-aws</artifactId>
<version>3.2.2</version>
</dependency>
</dependencies>
</project>java main方法定义
public static void main(String[] args)
throws IOException, NoSuchAlgorithmException, InvalidKeyException {
Configuration conf = new Configuration();
conf.set("fs.s3a.aws.credentials.provider"," com.amazonaws.auth.InstanceProfileCredentialsProvider,org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider,com.amazonaws.auth.EnvironmentVariableCredentialsProvider");
conf.set("fs.s3a.connection.ssl.enabled", "false");
conf.set("fs.s3a.endpoint", "http://127.0.0.1:9000");
conf.set("fs.s3a.access.key", "minioadmin");
conf.set("fs.s3a.secret.key", "minioadmin");
conf.set("fs.s3a.path.style.access", "true");
conf.set("fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem");
conf.set("fs.s3a.fast.upload", "true");
String warehousePath = "s3a://datalake/";//minio bucket 路径
System.out.println(warehousePath);
HadoopCatalog catalog = new HadoopCatalog(conf, warehousePath);
System.out.println(catalog.name());
TableIdentifier name = TableIdentifier.of("logging", "logs");
// 定义表结构schema
Schema schema = new Schema(
Types.NestedField.required(1, "level", Types.StringType.get()),
Types.NestedField.required(2, "event_time", Types.TimestampType.withZone()),
Types.NestedField.required(3, "message", Types.StringType.get()),
Types.NestedField.optional(4, "call_stack", Types.ListType.ofRequired(5, Types.StringType.get()))
);
// 分区定义(以birth字段按月进行分区)
PartitionSpec spec = PartitionSpec.builderFor(schema)
.hour("event_time")
.identity("level")
.build();
// 数据库名,表名
TableIdentifier name1 = TableIdentifier.of("iceberg_db", "developer");
// 表的属性
// Map<String, String> properties = new HashMap<String, String>();
//properties.put("engine.hive.enabled", "true");
// 建表
// Table table = catalog.createTable(name, schema, spec, properties);
System.out.println("创建遍完成");
Table table = catalog.createTable(name, schema, spec);
}














 502
502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









