







 本文详细介绍了Spark Streaming的架构、原理和优化。它是一个可伸缩的实时流处理框架,处理数据源包括Kafka、Flume等。核心概念Discretized Streams (DStreams)是一系列RDD的集合,数据按时间切片处理。文章讨论了无状态、有状态和窗口操作,并展示了Twitter数据收集、窗口操作的实际应用。同时,提到了性能优化策略,如调整Batch Size、内存使用和数据清理。
本文详细介绍了Spark Streaming的架构、原理和优化。它是一个可伸缩的实时流处理框架,处理数据源包括Kafka、Flume等。核心概念Discretized Streams (DStreams)是一系列RDD的集合,数据按时间切片处理。文章讨论了无状态、有状态和窗口操作,并展示了Twitter数据收集、窗口操作的实际应用。同时,提到了性能优化策略,如调整Batch Size、内存使用和数据清理。
1.1概述:
Spark Streaming架构概述和原理
Spark Streaming案例集锦
源码分析与性能优化
1.2 Spark Streaming架构概述和原理
What is Spark Streaming?
是规模的,可伸缩的,实时流处理。

Spark Streaming的数据来源除了上述kafka,flume,HDFS/S3,Kinsesis,Twitter之外,还可以来源TCP sockets网站发来的数据,并且可以使用高级函数例如,map,join,reduce和window,来构建复杂的算法。最后被处理过的数据也可以被保存在hdfs,Databases, Dashboards里面。并且可以用流处理来处理图计算和机器学习。

在Spark Streaming内部实现是接收到输入数据之后,以时间为分片对数据进行批次处理。,切分好数据分片之后,Spark Engine对数据进行计算,最后,产生一批又一批的处理后的数据。对于每一批的处理batch是并行处理的。例如,一秒产生一批,如果前一秒的还没处理完,下一秒的将不会被计算,这时候就会产生阻塞。因此这里面的时间设置也是一个优化点。
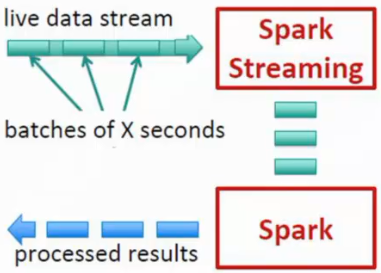
数据是串行输入的,每个batch处理是并行的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 140
140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









