










A group of n cities is connected by a network of roads. There is an undirected road between every pair of cities, so there are 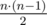 roads in total. It takes exactly y seconds to traverse any single road.
roads in total. It takes exactly y seconds to traverse any single road.
A spanning tree is a set of roads containing exactly n - 1 roads such that it's possible to travel between any two cities using only these roads.
Some spanning tree of the initial network was chosen. For every road in this tree the time one needs to traverse this road was changed from y to x seconds. Note that it's not guaranteed that x is smaller than y.
You would like to travel through all the cities using the shortest path possible. Given n, x, y and a description of the spanning tree that was chosen, find the cost of the shortest path that starts in any city, ends in any city and visits all cities exactly once.
The first line of the input contains three integers n, x and y (2 ≤ n ≤ 200 000, 1 ≤ x, y ≤ 109).
Each of the next n - 1 lines contains a description of a road in the spanning tree. The i-th of these lines contains two integers ui and vi(1 ≤ ui, vi ≤ n) — indices of the cities connected by the i-th road. It is guaranteed that these roads form a spanning tree.
Print a single integer — the minimum number of seconds one needs to spend in order to visit all the cities exactly once.
5 2 3 1 2 1 3 3 4 5 3
9
5 3 2 1 2 1 3 3 4 5 3
8
In the first sample, roads of the spanning tree have cost 2, while other roads have cost 3. One example of an optimal path is 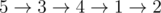 .
.
In the second sample, we have the same spanning tree, but roads in the spanning tree cost 3, while other roads cost 2. One example of an optimal path is 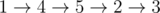 .
.
#include<stdio.h>
#include<iostream>
#include<string.h>
#include<string>
#include<ctype.h>
#include<math.h>
#include<set>
#include<map>
#include<vector>
#include<queue>
#include<bitset>
#include<algorithm>
#include<time.h>
using namespace std;
void fre() { freopen("c://test//input.in", "r", stdin); freopen("c://test//output.out", "w", stdout); }
#define MS(x,y) memset(x,y,sizeof(x))
#define MC(x,y) memcpy(x,y,sizeof(x))
#define MP(x,y) make_pair(x,y)
#define ls o<<1
#define rs o<<1|1
typedef long long LL;
typedef unsigned long long UL;
typedef unsigned int UI;
template <class T1, class T2>inline void gmax(T1 &a, T2 b) { if (b>a)a = b; }
template <class T1, class T2>inline void gmin(T1 &a, T2 b) { if (b<a)a = b; }
const int N = 2e5+10, M = 0, Z = 1e9 + 7, ms63 = 0x3f3f3f3f;
int n;
LL X, Y;
vector<int>a[N];
int link;//link表示我们需要的额外链数
int dfs(int x, int pre)
{
int son = 0;
for (int i = a[x].size() - 1; ~i; --i)
{
int y = a[x][i];
if (y != pre)son += dfs(y, x);
}
if (pre == -1)
{
link += max(0, son - 2);
return 0;
}
else if (son < 2)return 1;
else
{
link += son - 1;
return 0;
}
}
int main()
{
while (~scanf("%d%lld%lld", &n,&X,&Y))
{
for (int i = 1; i <= n; ++i)a[i].clear();
for (int i = 1; i < n; ++i)
{
int x, y;
scanf("%d%d", &x, &y);
a[x].push_back(y);
a[y].push_back(x);
}
if (X <= Y)
{
link = 0;
dfs(1, -1);
}
else
{
link = n - 1;
for (int i = 1; i <= n; ++i)if (a[i].size() == n - 1)link = n - 2;
}
LL ans = link*Y + (n - 1 - link)*X;
printf("%lld\n", ans);
}
return 0;
}
/*
【trick&&吐槽】
1,不要忘记dfs虽然是从树根展开,然而积累却是从树叶开始的。
2,要明确问题的性质,对问题做合理的转化。
【题意】
有n(3<=n<=1e5)个点,位于一个完全图中,每两个点之间的距离都为y。
然后给你一棵n个点的生成树,该生成树上的n-1条边的权值都为x。
问你,我们如何遍历这n个点,每个点遍历且仅遍历一次,使得走过的总路程尽可能小。
【类型】
贪心 dfs
【分析】
首先,题目并没有告诉你x和y的大小关系。
1,如果y<=x(非树边更优)
1,如果存在一个点的所有临边,都在树上,那答案便是(n-2)*y+x
2,否则答案就是(n-1)*y
证明:
这个的证明可以通过树的二分图性质来证明。
树是一个二分图,我们可以把点染色成为奇点和偶点。
然后,所有的树边都在这个二分图中间。
那么,我们只要先走完二分图一侧的点,再走完二分图另外一侧的点,两侧之间选一条非树边连接即可。
唯一一个两侧之间不存在非树边的情形是,二分图一侧的点集点数只为1.也就是我们判定的星图(或叫做菊花图2333)
2,如果x<y(树边更优)
我们尽量走树边,不走非树边。
然后这道题就等价为——我们要看看这棵树可以划分成多少棵不同的链。
(链的数量-1)*y+(n-链的数量)*x就是答案
============================================
于是问题就变成了:
我们如何找出一棵树的最小链划分?
匈牙利算法?复杂度O(nm)
HK算法?复杂度O(sqrt(n)*m)。似乎可行?
不,就算时间复杂度看似有戏了。然而我们怎么建图连边还是需要考虑的。
周贤杰向我提供了一种想法,我们做一个dfs,把相邻边做黑白染色。
然后再二分匹配,匹配数比n-2少几,就多出几条树外边。
然而,我们当然不要尝试1e9复杂度的做法。这种情形下的正解是贪心。
我们如何贪心呢?应该结合下面两组数据来思考。
第一组数据:
1
2-6
3-7
4
5
答案是2
第二组数据:
1
2-6
3
4-7
5
答案是3
不要忘记,dfs的完成其实是自下而上的。
如果是个单链树,额外链数肯定是0
如果出现分叉:
1,分叉数为2,我们使得2个分叉单独成1个额外链即可。并且不向上贡献分叉数。
2,分叉数超过2,我们可以保留一个分叉,向上延展贡献分叉数。剩下的其他分叉都要成单独的额外链。
这样一直处理到根节点。
根节点的分叉数不论是1亦或是2,我们都不需要额外链。
超过2的每条分叉,我们才需要用额外链覆盖。
这样的弹贪心是正确到无压力AC的。
【时间复杂度&&优化】
O(n)
//以下为暴力对拍程序
int w[20][20];
pair<int, int>edge[20];
int f[20];
int c[20];
int ANS;
int find(int x)
{
return f[x] == x ? x : f[x] = find(f[x]);
}
bool random()
{
n = rand() % 6 + 2;
X = rand() % 10 + 1;
Y = rand() % 10 + 1;
for (int i = 1; i <= n; ++i)f[i] = i;
for (int i = 1; i <= n; ++i)
{
for (int j = 1; j <= n; ++j)w[i][j] = Y;
}
for (int i = 1; i < n;++i)
{
int x = rand() % n+1;
int y = rand() % n+1;
while (find(x)==find(y))
{
x = rand() % n + 1;
y = rand() % n + 1;
}
f[find(y)] = find(x);
w[x][y] = w[y][x] = X;
edge[i] = MP(x, y);
}
for (int i = 1; i <= n; ++i)c[i] = i;
ANS = 1e9;
do {
int tmp = 0;
for (int i = 1; i < n; ++i)tmp += w[c[i]][c[i + 1]];
gmin(ANS, tmp);
} while (next_permutation(c + 1, c + n + 1));
return 1;
}
*/













 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









