







集合
数据保存问题
当编程时,可能需要数组保存大量的对象,但是问题在于:数组不能支持动态扩容,一旦初始化一个数组之后,它的长度是不可改变的;数组保存的数据类型单一;
集合引入
当数组的约束越来越明显之后,就使用集合容器来进行多数据存储:集合主要负责保存,乘装其他数据;Java所有的集合类都在java.util包下,包括大量的集合接口和集合的实现类;
集合和数组并不一样,数组既可以存储基本数据类型,也可以存储对象类型,而集合只能存储对象类型数据;
集合类型
Java集合分为Collection和Map两大类,它们是Java集合类的根接口;我们使用的集合类都是这两个接口的实现类;
集合接口的结构:

Map接口的结构:

Iterator()接口
Collection接口实现Iterator()接口,从而实现集合元素的迭代操作;

Iterator()其实是一种设计模式:迭代器(Iterator)模式,提供一个对象来顺序访问聚合对象的一系列数据,而不暴露聚合对象内部表示,迭代器模式是一种对象行为模式,其主要的优点是:
① 访问一个聚合对象的内容而无需暴露它的内部表示
② 遍历任务交给迭代器完成,简化了聚合类
③ 支持不同的方式遍历一个聚合对象,可以自定义迭代器的子类来实现新的迭代方
④ 不需要对原来的代码进行逻辑修改
⑤ 封装性好
缺点:增加了类的个数

Iterator()接口的4个抽象方法:
boolean hasNext(), E next(), remove(), forEachRemaing()
通过反复调用next()方法,可以逐个访问集合的每个元素,但是,如果到达了集合的末尾,next()会抛出一个NoSuchElementException的异常,所以在调用next()方法之前需要先调用hasNext()方法来确定是否还有下一个元素。如果集合还有可以进行访问的对象hasNext()方法会返回true,当hasNext()方法返回true时,再使用next()方法进行访问。




需要先next(),才能删除前一个元素,如果没有前一个元素,会报IllwgalStateException()异常
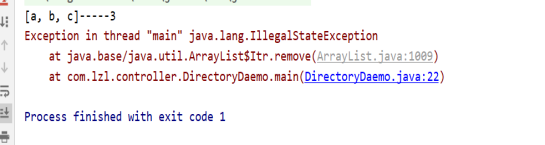
Collection集合接口提供了很多抽象方法:
| 方法 | 含义 |
|---|---|
| Iterator<E>() iterator | 返回用于访问集合各个元素的迭代器 |
| Int size() | 返回集合的元素个数 |
| Boolean isEmpty() | 如果集合没有元素,返回true |
| Boolean contains(Object obj) | 如果集合含有obj对象,返回true |
| Boolean containsAll(Collection<?> other) | 如果这个集合包含other集合的所有元素,返回true |
| Boolean add(E element) | 向集合添加新元素,如果添加成功返回true |
| Boolean addAll(Collection<? extends E> other) | 将另一个集合所有的元素加入到这个集合,成功则返回true |
| Boolean remove(Object obj) | 删除这个集合的obj对象 |
| Boolean removeAll(Collection<?> other) | 从这个集合删除other集合的所有对象,成功返回true |
| Default boolean removeIf(Predicate<? super E> filter) | 从这个集合删除filter返回true的所有元素,如果删除成功放回true |
| Void clean() | 从这个集合中删除所有的元素 |
| Object[] toArray() | 返回这个集合中的对象的数组 |
| <T> T[] toArray(T[] arrayToFill) | 返回这个集合的对象数组,如果arrayToFill够大,将整个集合的元素填充进去,其余补null,否则分配一个新的数组,其成员和arrayToFill的成员相同,长度是集合的长度,并填充集合元素 |
集合有两个基本接口:Collection和Map,可以用以下的方法在集合中插入元素:
Boolean add(E element)
如果是插入K-V类型数据使用
V put(K key,V value)
List是一个有序集合,元素会增加到容器的特定位置上,可以采用两种方式进行元素的访问:迭代器进行访问,根据索引下标进行访问(随机访问)。
List定义了多个随机访问的方法:
Void add(int index,E e);
E get(int index);
E set(int index, E element);
ListIterator接口是Iterator接口的子接口
ListIterator<E> listIterator();
List分成两类,一类为了支持有序集合能够快速的随机访问,因此List方法提供了整数索引来访问(顺序表),链表虽然也是有序的,但是随机访问很慢,所以更适合使用迭代器进行访问。
Set接口等同于Collection接口,不过方法更加的严谨。Set接口的add方法不允许添加相同的元素,使用的是equals()进行元素的比较,如果两个set包含相同的元素就认为它们相等,并不要求元素的顺序一致。
集合的具体类型
| 集合类型 | 特点 |
|---|---|
| ArrayList | 可以动态的增长和缩小一个索引序列 |
| LinkedList | 可以再任何位置高效的删除和添加一个有序序列 |
| ArrayDeque | 实现为一个循环数组的双端队列 |
| HashSet | 没有重复的无序集合 |
| TreeSet | 一个有序的Set |
| EnumSet | 一个包含枚举类型的集合 |
| LinkedHashSet | 一个可以记住元素插入次序的Set |
| PriorityQueue | 允许高效删除最小元素的一个集合 |
| HashMap | 存储键/值关联的一个数据结构 |
| TreeMap | 键有序的一个映射 |
| EnumMap | 键属于枚举的一个映射 |
| LinkedHashMap | 可以记住键/值项添加次序的一个映射 |
| WeakHashMap | 值不会在别处使用时会被垃圾回收的一个映射 |
| IdentifityHashMap | 用==而不用equals比较的一个映射 |
ArrayList的缺点就在于当需要删除一个元素或者添加一个元素时,需要整体移动集合元素,消耗很大;链表结构可以解决这个问题。数组是在连续的存储位置上存放对象的引用,而链表是将每一个对象存放到单独的一个链接(link)上,每个链接还存放着下一个链接的引用,在Java中,其实是双向链表,每一个链接还存放着前驱的引用

链表的缺点:链表不可以进行随机访问,当需要查找元素时,需要从第一个元素开始依次查找,没有捷径可走。
Vector 是一个顺序表结构的list,基本和ArrayList相同。但是有一点,Vector的每一个方法放屁使用了synchronized关键字进行修饰,是线程同步的,线程安全的;ArrayList是异步的,线程不安全的。
HashSet是使用一个散列表(HashTable)。散列表为每一个对象计算出一个整数,称为散列码(HashCode)。更准确的说,不同的对象将产生不同的散列码。
在Java中,散列表用链表+数组的方式实现,每个列表称为桶(bucket)。如果想查找表中对象的位置,首先需要计算其散列码,然后与桶的余数取余,所得到的结果就是保存这个数据的索引。
在Java8的新特性中,桶满时会变成平衡二叉树。
HashSet() 构造一个空集合
HashSet(Collection<? extends E> elements) 构造一个set,将集合的元素全部都添加到set内
HashSet(int initialCapacity) 构造一个空的Set,并指定容量
HashSet(int initialCapacity, float loadFactor) 构造一个空set,但是指定容量和填充因子(0~1d的小数,默认是0.75)
TreeSet 和 HashSet十分相似,但它是一个有序集合。
队列和双端队列
队列(queue)的优势在于它可以高效地在尾部添加元素,删除头部元素。
双端队列(Deuqe)允许在头部和尾部都高效的增删元素。
Boolean add(E element) 添加元素
Boolean offer(E element) 如果队列没有满,将这个元素插入到队列中,并返回true。如果队列已满,会抛出IllegalStateException
Boolean remove() 删除头部元素
E poll() 假设队列不为空,删除并返回这个队列对头的元素,如果队列为空,会抛出异常或者返回null。
E element() 返回这个队列的元素,但不删除
E peek() 如果队列不为空,返回这个队列的元素,但不删除,如果队列为空,会抛出异常或者返回null。
ArrayDeque(int initialCapacity) 用初始值为16或者设定的值构建一个无限定双端队列
Priority queue() 优先队列
优先队列可以随意插入元素,但是会通过顺序进行检索,也就是说无论是怎么插入,调用remove()方法时,都是删除尾部按照顺序排序好的元素
Map
Set是一个集合,允许你快速查找现有的元素,但是要查找一个元素,需要查找所需要的查找的那个元素的副本。而不是常见的查找。通常,我们要知道某个关键信息,都是采用一种映射(map)的方式,通过键-值,来一一对应。
Java类提供了两种通用的实现类:HashMap和 TreeMap。这两个类都是实现了Map接口。

V get(Object key) 获取键关联的值,返回键关联的值,如果没有这个对象,返回null
Default V getOrDefault(Object key,V defaultValue) 返回与这个键相对应的值,如果没有返回默认的value
V put(K key , V value) 将关联的键值对存储到map内,如果这个键已存在,则覆盖原来的value
Boolean containsKey(Object key) 如果有这个键,返回true
Boolean containsValue(Object value) 如果有这个值,返回true
HashMap()
HashMap(int initialCapacity) 设置初始长度
HashMap(int initialCapacity, float loadFactor) 设置初始长度和扩容时的装填因子(0.0~1.0,默认是0.75)
TreeMap() 为实现Comparable接口的键构建一个treeMap
TreeMap(Comparator <? super K> c) 构造一个树映射,并指定一个比较器对键进行排序
集合并不认为映射是一个集合。(其他数据结构认为键/值是一个集合,或者是按照索引进行排序的集合)。不过,可以得到map的视图(view),这样将键值对看成一个整体,就可以实现collection接口。
Set keySet();
Collection values();
Set<Map.Entry<K,V>> entrySet();
因为map的key其实就是一个带有值得Set集合,所以可以将所有的key转化成一个Set
Values其实就是一个无序的集合,所以可以通过将所有的values放在一个collection内
Entry<K,V> 是将一对k,v看成一个整体。并可以转化成Set集合
LinkedHashMap() 类似于LinkedHashSet ,底层实现是一个双向循环链表,方便插入元素,查询时,需要遍历全部元素。
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











