







k8s集群部署
| 192.168.145.153 | k8s-master | 环境初始化、docker、kubelet、kubeadm、执行kubeadm init |
|---|---|---|
| 192.168.145.154 | k8s-node1 | 环境初始化、dokcer、kubelet、kubeadm、执行kubeadm join |
| 192.168.145.155 | k8s-node2 | 环境初始化、dokcer、kubelet、kubeadm、执行kubeadm join |
一、环境初始化
1.配置主机间相互免密登录
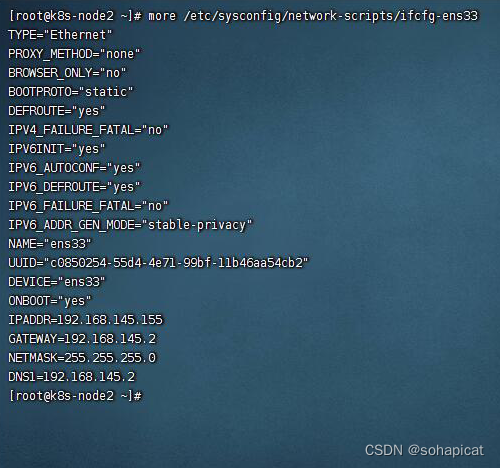
1.1 配置静态IP
vi /etc/sysconfig/network-scripts/ifcfg-ens33
#更改BOOTPROTO
BOOTPROTO="static"
#添加ip信息
IPADDR=192.168.145.153
GATEWAY=192.168.145.2
NETMASK=255.255.255.0
DNS1=192.168.145.2
需用reboot重启后生效。
1.2 设置主机名
使用hostnamectl set-hostname与bash修改主机名。
[root@k8s-master ~]# hostnamectl set-hostname k8s-master && bash
[root@k8s-node1 ~]# hostnamectl set-hostname k8s-node1 && bash
[root@k8s-node2 ~]# hostnamectl set-hostname k8s-node2 && bash
1.3 设置主机间通过主机名访问
vi /etc/hosts
#添加一下内容
192.168.145.153 k8s-master
192.168.145.154 k8s-node1
192.168.145.155 k8s-node2
1.4 配置主机间无密码登录
ssh-keygen
#遇到提示直接回车,不输入密码
#将生成的私钥文件拷贝到其它主机
ssh-copy-id k8s-master
ssh-copy-id k8s-node1
ssh-copy-id k8s-node2
2. 配置时间同步
yum install ntpdate -y
ntpdate time.windows.com
3. 关闭防火墙和交换分区
systemctl stop firewalld && systemctl disable firewalld
swapoff -a
vi /etc/fstab
#将swap分区注释掉
#/dev/mapper/centos-swap swap swap defaults 0 0
#如果是克隆的虚拟机,需要删除UUID
4. 关闭selinux
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
需重启后生效。
使用getenforce显示为Disabled则selinux已经关闭。
5. 修改内核参数
modprobe br_netfilter
echo "modprobe br_netfilter" >> /etc/profile
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sysctl -p /etc/sysctl.d/k8s.conf
sysctl:运行时配置内核参数
-p:从指定的文件加载系统参数,如不指定即从/etc/sysctl.conf 中加载
6. 关闭iptables
yum install iptables-services -y
service iptables stop && systemctl disable iptables
iptables -F
二、安装docker
yum install -y yum-utils device-mapper-persistent-data lvm2 wget net-tools nfs-utils lrzsz gcc gcc-c++ make cmake libxml2-devel openssl-devel curl curl-devel unzip sudo ntp libaio-devel wget vim ncurses-devel autoconf automake zlib-devel python-devel epel-release openssh-server socat ipvsadm conntrack ntpdate telnet
#安装阿里云镜像源
yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install -y docker-ce-cli-23.0.0
yum install containerd.io-1.6.6 -y
yum install -y docker-ce-23.0.0
#docker-ce-cli需和docker-ce版本一致
修改配置文件
mkdir -p /etc/docker/
vi /etc/docker/daemon.json
{
"registry-mirrors": ["https://ls3qk7tc.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
]
}
开启docker
systemctl enable docker && systemctl start docker
三、安装kubernetes
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
yum makecache
yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
四、服务器安装
1. Master
更改/etc/containerd/config.toml
(在node节点上也需做更改。)
containerd config default > /etc/containerd/config.toml
vi /etc/containerd/config.toml
···
#sandbox_image = "k8s.gcr.io/pause:3.6"
sandbox_image = "registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.9"
···
SystemdCgroup = true
···
config_path = "/etc/containerd/certs.d"
···
创建容器时会拉去沙盒镜像,默认使用的国外的镜像点。可以改为使用私有仓库代理或是使用国内代理镜像。
这里使用国内阿里云代理镜像:registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.9。
/etc/crictl.yaml
vi /etc/crictl.yaml
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 10
debug: false
/etc/containerd/certs.d/docker.io/hosts.toml
mkdir -p /etc/containerd/certs.d/docker.io
vi /etc/containerd/certs.d/docker.io/hosts.toml
[host."https://3vta0yzw.mirror.aliyuncs.com",host."https://registry.docker-cn.com"]
capabilities = ["pull","push"]
kubeadm.yaml
kubeadm config print init-defaults > kubeadm.yaml
vi kubeadm.yaml
···
localAPIEndpoint:
advertiseAddress: 1.2.3.4 #改为控制节点IP
···
nodeRegistration:
#criSocket: unix:///var/run/containerd/containerd.sock #不注释初始化会报错
imagePullPolicy: IfNotPresent
name: k8s-master #改为控制节点主机名
taints: null
···
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers #阿里云镜像仓库地址
kind: ClusterConfiguration
kubernetesVersion: 1.27.0 #k8s版本
···
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16
...
执行kubeadm init
systemctl enable kubelet
systemctl restart containerd.service
systemctl daemon-reload
systemctl restart docker
kubeadm init --config=kubeadm.yaml --ignore-preflight-errors=SystemVerification
初始化结果如下:
[init] Using Kubernetes version: v1.27.0
[preflight] Running pre-flight checks
[preflight] The system verification failed. Printing the output from the verification:
KERNEL_VERSION: 3.10.0-1160.el7.x86_64
OS: Linux
CGROUPS_CPU: enabled
CGROUPS_CPUACCT: enabled
CGROUPS_CPUSET: enabled
CGROUPS_DEVICES: enabled
CGROUPS_FREEZER: enabled
CGROUPS_MEMORY: enabled
CGROUPS_PIDS: enabled
CGROUPS_HUGETLB: enabled
CGROUPS_BLKIO: enabled
[WARNING SystemVerification]: failed to parse kernel config: unable to load kernel module: "configs", output: "modprobe: FATAL: Module configs not found.\n", err: exit status 1
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [k8s-master2 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.145.157]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [k8s-master2 localhost] and IPs [192.168.145.157 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [k8s-master2 localhost] and IPs [192.168.145.157 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 4.002187 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node k8s-master2 as control-plane by adding the labels: [node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node k8s-master2 as control-plane by adding the taints [node-role.kubernetes.io/control-plane:NoSchedule]
[bootstrap-token] Using token: abcdef.0123456789abcdef
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.145.153:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:734e14472a65662263c759b630e23dcfca6230fa24c6f707876f2cec0c498905
根据提示执行如下命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
[root@k8s-master2 ~]# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
namespace/kube-flannel created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds created
2. Node
更改/etc/containerd/config.toml
containerd config default > /etc/containerd/config.toml
vi /etc/containerd/config.toml
···
#sandbox_image = "k8s.gcr.io/pause:3.6"
sandbox_image = "registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.9"
···
SystemdCgroup = true
···
config_path = "/etc/containerd/certs.d"
···
开启相关服务。
systemctl enable kubelet
systemctl restart containerd.service
systemctl daemon-reload
systemctl restart docker
在master节点上使用kubeadm token create --print-join-command
获取join命令。
在节点使用获取的命令加入集群。
kubeadm join 192.168.145.153:6443 --token 6pf4on.t6hs9pjppnylnzha --discovery-token-ca-cert-hash sha256:2f88cbdb240054c9b54924cf899d5661c63b2eb8d055df7d358f9e49d6355b1f --ignore-preflight-errors=SystemVerification
在控制节点用kubectl get nodes查看节点状态。
[root@k8s-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane 24h v1.27.4
k8s-node1 Ready <none> 22h v1.27.4
k8s-node2 Ready <none> 22h v1.27.4
五、报错处理
1. ERROR CRI
官网文档中说明containerd默认禁止了CRI集成插件,需要到/etc/containerd/config.toml中将disabled_plugins 列表中cri删除,并重启containerd。
vi /etc/containerd/config.toml
···
disabled_plugins = []
···
systemctl restart containerd
2. join集群后节点notready
解决方法:将控制节点上/etc/cni/net.d 目录下的文件拷贝到有问题的节点上。
scp /etc/cni/net.d/* k8s-node1:/etc/cni/net.d/
scp /etc/cni/net.d/* k8s-node2:/etc/cni/net.d/















 6879
6879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









