







Pandas 学习笔记 - By [顾]
这是kaggle中pandas部分的前三章学习笔记(有借助ai生成习题巩固),小白一枚,欢迎大佬指错
第一章:Creating, Reading & Writing
核心概念
- DataFrame:带标签的二维表格(行索引+列索引)
- Series:带标签的一维数组(单列数据)
- 文件读写黄金法则:
- 读入时关注编码/分隔符/列类型
- 保存时禁用冗余索引(
index=False)
DataFrame vs Series对比
| 特性 | DataFrame | Series |
|---|---|---|
| 维度 | 二维 | 一维 |
| 索引 | 行索引 + 列名 | 单一索引 |
| 数据存储 | 支持多数据类型列支持多数据类型列支持多数据类型列支持多数据类型列 | 单一数据类型 |
| 应用场景 | 结构化数据表(如CSV) | 时间序列/单列数据 |
从字典创建 DataFrame
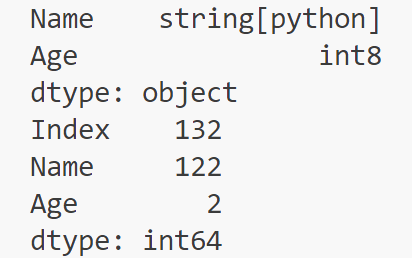
import pandas as pd
# 显式指定数据类型以优化内存
data = {
'Name': pd.Series(['Alice', 'Bob'], dtype='string'), # 使用string类型避免object开销
'Age': pd.Series([25, 30], dtype='int8') # 小整数用int8
}
df = pd.DataFrame(data)
# 查看数据类型和内存占用
print(df.dtypes)
print(df.memory_usage(deep=True))
添加行索引的 DataFrame
# 定义行索引(纵向标题)
df = pd.DataFrame(
{'Bob': ['I liked it.', 'It was awful.'],
'Sue': ['Pretty good.', 'Bland.']},
index=['Product A', 'Product B']
)

Series 的创建与使用
# 创建带名称和索引的 Series
ingredients = pd.Series(
['4 cups', '1 cup', '2 large', '1 can'],
index=['Flour', 'Milk', 'Eggs', 'Spam'],
name='Dinner'
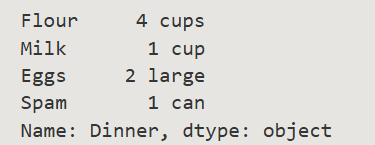
读取 CSV 文件
CSV 文件是一个用逗号分隔的值表
# 高效读取配置(指定列+数据类型)
dtype = {'points': 'int32', 'price': 'float32'}
usecols = ['country', 'points', 'price', 'variety']
wine_reviews = pd.read_csv(
"../data/winemag-data-130k-v2.csv",
dtype=dtype,
usecols=usecols,
engine='c' # 使用C引擎加速
) # 将数据读取到DataFrame
wine_reviews = pd.read_csv(
"../data/winemag-data-130k-v2.csv",
comment='#', # 忽略注释行
parse_dates=['date'], # 自动解析日期列
na_values=['N/A', '?'] # 自定义缺失值标识
)
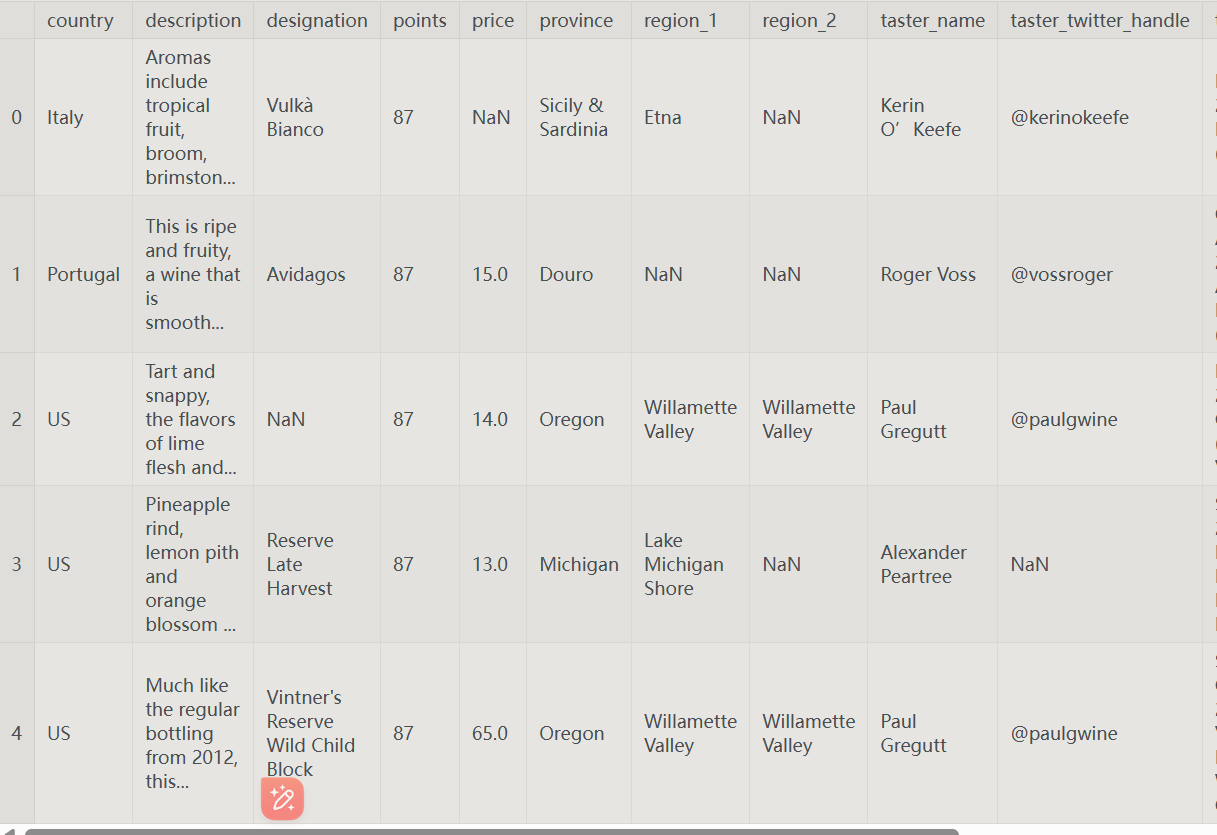
检查 DataFrame 的内容
我们可以用
head()命令检查DataFrame的内容,该命令获取前五行。
wine_reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv", index_col=0)
wine_reviews.head () # 为了使Pandas使用该列作为索引(而不是从头开始创造一个新的),我们可以指定idex_col
保存为 CSV 文件
# 中文兼容性配置
df = pd.DataFrame({
'姓名': ['张三', '李四', '王五'],
'年龄': [22, 25, 30],
'城市': ['北京', '上海', '广州']
})
df.to_csv(
'../output/people.csv',
index=False, # 禁用索引列
encoding='utf_8_sig', # 解决Excel中文乱码
date_format='%Y-%m-%d'
)
常用参数
| 参数 | 功能 | 示例值 | 默认值 |
|---|---|---|---|
path_or_buf | 文件路径或缓冲区 | ‘data/result.csv’ | None |
sep | 分隔符 | ‘\t’ (制表符) | ‘,’ |
index | 是否保留行索引 | True/False | True |
header | 是否保留列名 | True/False | True |
encoding | 文件编码 | ‘utf_8_sig’ (兼容中文) | ‘utf-8’ |
na_rep | 缺失值占位符 | ‘NULL’ | ‘’ |
自测问题清单
- 如何创建带中文列名的DataFrame?
- 读取CSV时如何处理包含特殊字符的列名?
- 保存数据时如何压缩文件?
参考答案
-
使用Unicode字符串定义列名
df = pd.DataFrame({u'姓名': ['张三', '李四']}) -
正则表达式筛选列名
import re df = pd.read_csv('data.csv', usecols=lambda col: re.match('^valid_', col)) -
压缩保存
df.to_csv('data.csv.gz', compression='gzip')
常见错误排查
| 错误类型 | 场景 | 解决方案 |
|---|---|---|
MemoryError | 读取大文件 | 分块读取 + 指定 dtype |
UnicodeDecodeError | 中文乱码 | encoding='utf_8_sig' |
KeyError | 列名拼写错误 | print(df.columns.tolist()) |
第二章:Indexing, Selecting & Assigning
核心概念对比
iloc[]:基于数值位置的索引(行、列均为数字)loc[]:基于标签的索引(行索引名、列名)at[]/iat[]:快速访问单个元素(标签/位置)query():用表达式筛选数据(类似SQL)
| 方法 | 选择类型 | 示例 | 适用场景 |
|---|---|---|---|
iloc[行, 列] | 位置索引 | df.iloc[0, 1] | 精确控制行列位置时 |
loc[行, 列] | 标签索引 | df.loc['row1', 'col2'] | 按业务标签筛选时 |
df[列名] | 列选择 | df['age'] | 快速提取单列/多列 |
query() | 条件表达式 | df.query("age > 20 & city == '北京'") | 复杂逻辑筛选时 |
基础索引操作
-
提取单列数据
# 等效方法:df.country 或 df['country'] country_data = reviews['country']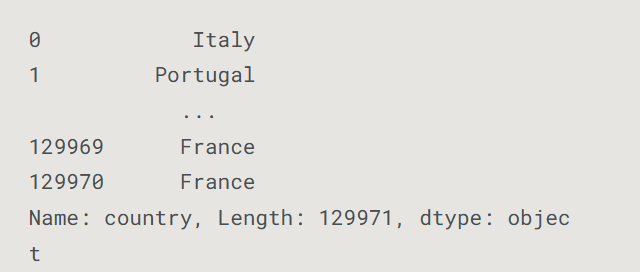
-
位置索引 (
iloc)# 获取首行所有数据(Series格式) first_row = reviews.iloc[0] # 选择前3行的前2列(左闭右开区间) subset = reviews.iloc[:3, :2] # 选择特定位置(第5行第3列) cell_value = reviews.iloc[4, 2] # 索引从0开始
-
标签索引 (
loc)# 选择索引为'Product A'的行,指定列 product_a = reviews.loc['Product A', ['taster_name', 'points']] # 筛选评分大于90的所有记录 high_ratings = reviews.loc[reviews['points'] > 90, :]
- 负数则是从末尾开始向前计数
- 条件1 且 条件2 , 使用(
&)- 条件1 或 条件2 , 使用(
|)iloc是前闭后开区间,而loc是闭区间
高级索引技巧
-
条件筛选组合
# 组合多个条件(注意括号优先级) france_premium = reviews.loc[ (reviews['country'] == 'France') & (reviews['price'].between(100, 500)) (reviews['points'] >= 95) ] # 使用位运算替代and/or(避免歧义) italy_or_spain = reviews.loc[ (reviews['country'] == 'Italy') | (reviews['country'] == 'Spain') ] -
快速元素访问
# 获取特定单元格的值(比loc/iloc更快) value_1 = reviews.at['Product A', 'price'] # 标签索引 value_2 = reviews.iat[4, 2] # 位置索引 # 修改单个元素(原地操作) reviews.iat[4, 2] = 98 # 第5行第3列设为98
索引操作优化
-
重置/设置索引
# 设置时间戳为索引(时间序列分析) reviews.set_index('timestamp', inplace=True) # 重置索引并保留原索引列 reset_df = reviews.reset_index(drop=False) -
多层索引 (MultiIndex)
# 创建国家-年份双层索引 reviews_multi = reviews.set_index(['country', 'year'], append=True) # 筛选意大利2020年数据 italy_2020 = reviews_multi.loc[(slice(None), 'Italy', 2020), :]
实用筛选方法
-
isin列表匹配# 筛选特定葡萄品种 selected_variety = reviews[reviews['variety'].isin(['Chardonnay', 'Cabernet'])] # 反向筛选(排除特定国家) excluded_countries = reviews[~reviews['country'].isin(['US', 'China'])] -
isnull/notnull缺失值处理# 检测价格缺失的记录(两种方式) missing_price = reviews[reviews['price'].isna()] missing_price = reviews.query("price != price") # NaN特性技巧 # 多重填充策略 reviews['price'] = reviews['price'].fillna({ 'France': reviews['price'].median(), 'Italy': reviews['price'].mean() })
常见错误与解决
| 错误现象 | 根本原因 | 解决方案 |
|---|---|---|
KeyError: 'column_name' | 列名拼写错误/包含空格 | 使用reviews.columns查看实际列名 |
SettingWithCopyWarning | 链式索引导致视图与副本混淆 | 使用.loc显式赋值 |
MemoryError | 未优化条件筛选导致全表复制 | 使用query()或分块处理 |
核心方法对比
| 方法 | 选择类型 | 示例 |
|---|---|---|
iloc[] | 位置索引 | df.iloc[0, 1] |
loc[] | 标签索引 | df.loc['row1', 'col2'] |
at[]/iat[] | 快速标量访问 | df.at['row1', 'col2'] |
自测问题
- 如何选择DataFrame的最后三行?
- 如何筛选出价格在50-100元之间的法国红酒?
loc和iloc在多层索引中的使用有何不同?
参考答案
-
位置索引选择末尾行
last_three = reviews.iloc[-3:] -
复合条件筛选
french_wines = reviews.loc[ (reviews['country'] == 'France') & (reviews['price'].between(50, 100)) ] -
多层索引使用差异
# loc需用元组指定层级 reviews_multi.loc[('Italy', 2020), :] # iloc按位置层级选择 reviews_multi.iloc[10:15, 2:5] # 第10-14行,第2-4列
第三章:Summary Functions & Maps
核心概念
- 摘要函数:快速生成数据统计摘要(如均值、唯一值等)
- 数据映射:通过函数转换数据(如标准化、类型转换等)
摘要函数详解
-
describe()- 统计摘要# 生成数值列的统计摘要(默认仅数值列) reviews.points.describe()
-
mean()- 计算均值# 计算评分列的均值 avg_points = reviews.points.mean() print(f"平均评分:{avg_points:.14f}")
-
unique()- 获取唯一值#查看唯一值的列表 reviews.taster_name.unique()
-
value_counts()- 频率统计#查看唯一值的列表以及在数据集中出现的频率 reviews.taster_name.value_counts()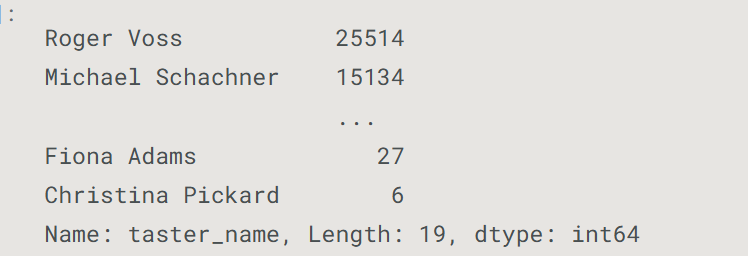
数据映射方法
-
map()- 单列映射# 创建一个示例的DataFrame,包含评分数据 data = {'points': [96, 88, 92, 84, 95, 78, 89]} reviews = pd.DataFrame(data) # 将评分转换为星级(1-5星) def points_to_stars(points): if points >= 95: return '⭐️⭐️⭐️⭐️⭐️' elif points >= 90: return '⭐️⭐️⭐️⭐️' elif points >= 85: return '⭐️⭐️⭐️' else: return '⭐️⭐️' reviews['stars'] = reviews.points.map(points_to_stars)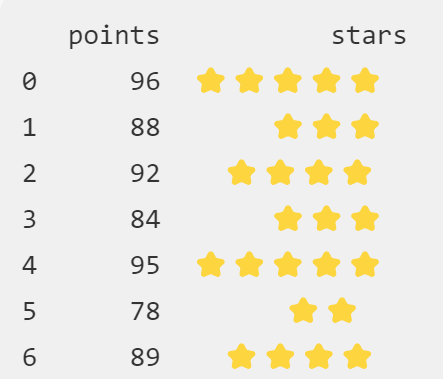
-
apply()- 多列/行操作# 计算价格与评分的比值(行级操作) reviews['value_ratio'] = reviews.apply( lambda row: row['points'] / row['price'], axis=1 ) # 列级操作:提取国家缩写 reviews['country_code'] = reviews['country'].apply( lambda x: x[:3].upper() if pd.notnull(x) else 'N/A' )
方法对比表
| 方法 | 应用层级 | 性能 | 适用场景 |
|---|---|---|---|
map() | 单列 | 快 | 简单标量转换(如类型转换) |
apply() | 行/列 | 较慢 | 复杂逻辑(涉及多列计算) |
applymap() | 元素级 | 最慢 | 全表统一格式转换(如字符串处理) |
性能优化技巧
向量化操作优先
# 避免apply,使用向量化计算(快10倍)
reviews['log_price'] = np.log(reviews['price'])
分类数据优化
# 将低基数列转换为category类型
reviews['country'] = reviews['country'].astype('category')
并行处理
# 使用swifter加速apply(需安装swifter)
import swifter
reviews['description_length'] = reviews['description'].swifter.apply(len)
常见错误排查
| 错误现象 | 原因分析 | 解决方案 |
|---|---|---|
AttributeError | 对空值调用字符串方法 | 先填充空值:fillna('') |
TypeError | 混合数据类型列操作 | 统一类型:astype(str) |
MemoryError | 大数据集使用apply | 改用向量化操作或分块处理 |
自测问题
- 如何统计每个国家葡萄酒的平均价格?
- 如何将
price列映射为"高价/中价/低价"三级分类? map和apply在性能上有何差异?什么场景下应避免使用apply?
参考答案
-
分组聚合
country_avg_price = reviews.groupby('country')['price'].mean().sort_values(ascending=False) -
分段映射
bins = [0, 50, 100, float('inf')] labels = ['低价', '中价', '高价'] reviews['price_tier'] = pd.cut(reviews['price'], bins=bins, labels=labels) -
性能差异
map适合单列简单转换(毫秒级)apply适合复杂逻辑但速度慢(秒级)- 处理10万+数据时优先使用向量化操作

















 108
108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









