







许松原创,转载请注明出处。
《Linux内核分析》MOOC课程 http://mooc.study.163.com/course/USTC-1000029000
引子:
在Linux中,我们可以使用下面这段代码来创建新的进程:
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int pid;
pid = fork();
if(pid < 0)
{
printf("Fork Failed!\n");
exit(-1);
}
else if(pid == 0)
{
printf("This is Child Process!\n");
}
else
{
printf("This is Parent Process!\n");
wait(NULL);
printf("Child Complete!\n");
}
return 0;
}代码执行结果如图:

结果发现代码中if语句的两个分支都执行了!这与我们对 if 语句的认知是不符合的。为什么会出现这种情况呢?
前面的课程中曾经提到:“Linux在创建新的子进程时,会首先复制父进程的资源,然后再将两个进程区分开来”。于是我们可以此作出一个猜测:
当父进程执行fork语句的时候,父进程的代码段以及当前的eip被复制到了子进程中。当fork语句区分完毕两个进程之后,父进程代码段中的fork返回到父进程(返回值>0),子进程代码段中的fork返回到子进程(返回值=0)。接着两个进程都开始执行if语句。于是,同样的if语句在两个不同进程的被以不同的方式进行执行,从而输出图中的结果。那么事实是否如此呢?接下来,我们将对fork这一系统调用的过程进行跟踪,以分析Linux是如何创建一个新进程的。
函数跟踪——fork:
通过查系统调用表我们可以找到fork对应的内核调用应该是sys_fork。然而,在这里的注释部分(63~87行),有这么几句话:
This is how fork() was meant to be done
...
Under Linux, vfork and fork are just special cases of clone.本次实验中,当在kernel中将断点设置在sys_fork上时,gdb是无法对fork调用进行跟踪的(这里的内核编译运行是在qemu模拟下的x86结构,可以查找到kernel/fork.c的1704行是有一个预编译条件的,内核编译时如果打开了这个条件,就可以直接对sys_fork进行断点了。而且这里最后调用了之前课程中看到过的do_fork来完成fork工作):
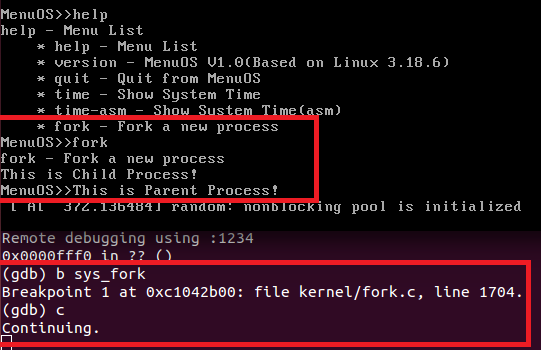
这促使我们转向系统调用clone对应的内核调用:sys_clone(这并不是说sys_fork无效,而是我们通过其他的路径来完成一样的工作罢了)。很幸运,gdb在这里停下来了:
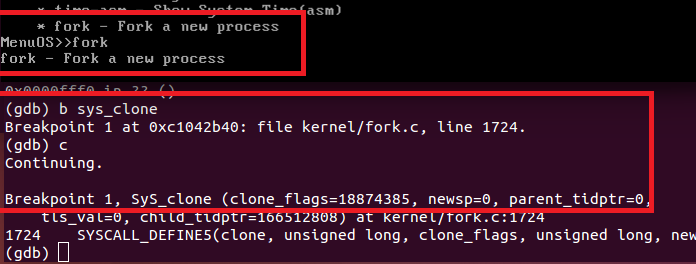
kernel/fork.c的1724行的函数同样调用了do_fork(与sys_fork几乎一样):
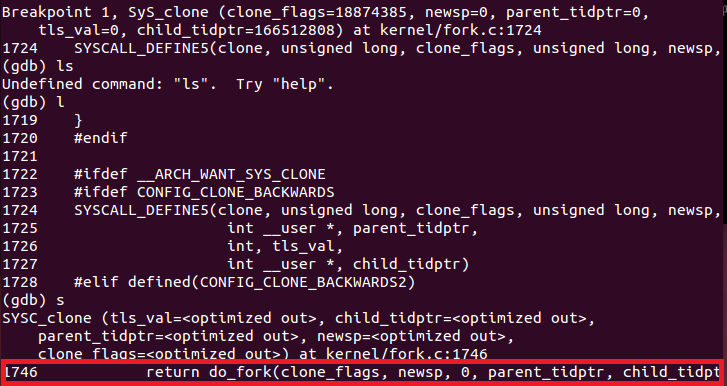
下面是do_fork的简化代码,只保留了关键部分,完整代码请参看这里第1623行:
long do_fork(clone_flags,stack_start,stack_size,parent_tidptr,child_tidptr)
{
struct task_struct *p;
long nr
...
p = copy_process(clone_flags,stack_start,stack_size,parent_tidptr,child_tidptr,NULL,trace); // !!!
if(!IS_ERR(p)) // 检查p的值是否合法
{
struct completion vfork;
struct pid *pid;
...
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid); // 这里将struct pid 转化成一个 int 类型的值了
...
}
else
{
nr = PTR_ERR(p); // 显然这里是得到错误的进程标识符
}
return nr;
}从do_fork中可以看到,与复制相关的函数只有copy_process了,那么就进入这个函数看一看。完整代码在这里第1182行:
struct task_struct *copy_process(
clone_flags,stack_start,stack_size,parent_tidptr,child_tidptr,pid,trace)
{
int retval;
struct task_struct* p; //这里的p就是新进程的task_struct
...
p = dup_task_struct(current);// 这里的current是一个宏,用来获取当前进程的task_struct
if (!p)
goto fork_out;
...
/* Perform scheduler related setup. Assign this task to a CPU. */
retval = sched_fork(clone_flags, p);
...
/* copy all the process information */
shm_init_task(p);上面代码中的dup_task_struct函数分配了一个task_struct对象给新的进程,以便于后续对父进程资源的复制。
下面的代码省去了每一次copy之后对retval的检错过程,这一系列的copy动作将当前进程的资源复制到新进程的task_struct中了:
retval = copy_semundo(clone_flags, p);
retval = copy_files(clone_flags, p);
retval = copy_fs(clone_flags, p);
retval = copy_sighand(clone_flags, p);
retval = copy_signal(clone_flags, p);
retval = copy_mm(clone_flags, p);
retval = copy_namespaces(clone_flags, p);
retval = copy_io(clone_flags, p);到此为止,我们有了新进程运行需要的资源,那么如何令新进程开始运行呢?这就需要另外一个copy函数:
retval = copy_thread(clone_flags, stack_start, stack_size, p);在执行完毕copy_thread之后,do_fork设置了新进程与当前进程之间的父子关系,以及处理完毕中断以及锁的问题之后,返回新进程的task:
...
/* CLONE_PARENT re-uses the old parent */
if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) {
p->real_parent = current->real_parent;
p->parent_exec_id = current->parent_exec_id;
}
else
{
p->real_parent = current;
p->parent_exec_id = current->self_exec_id;
}
...
return p;
}我们回到copy_thread上来:
int copy_thread(unsigned long clone_flags, unsigned long sp,unsigned long arg, struct task_struct *p)
{
struct pt_regs *childregs = task_pt_regs(p);
struct task_struct *tsk;
int err;
p->thread.sp = (unsigned long) childregs;
p->thread.sp0 = (unsigned long) (childregs+1);
memset(p->thread.ptrace_bps, 0, sizeof(p->thread.ptrace_bps));
if (unlikely(p->flags & PF_KTHREAD)) {
/* kernel thread */
...
return 0;
}
*childregs = *current_pt_regs();
childregs->ax = 0;
if (sp)
childregs->sp = sp;
p->thread.ip = (unsigned long) ret_from_fork;
task_user_gs(p) = get_user_gs(current_pt_regs());
...
return err;
}首先看到的是结构体pt_regs。这个结构体可以用来保存寄存器的值。task_pt_regs定义为宏,该宏用来从获取一个进程的pt_regs结构体指针:
#define task_pt_regs(tsk) ((struct pt_regs *)(tsk)->thread.sp0 - 1)接下来,新进程的sp被指向寄存器组结构体。
然后判断新的进程是否是一个内核进程,如果是,就执行if语句块。这里我们略过这些,但是应当注意到其中出现了thread.ip字样。
接着复制当前进程的pt_regs结构(新进程的堆栈也被设置好了),并将其中的ax(或者eax)赋值为0(这是因为当系统调用返回时,结果保存在ax(eax)中,这样当fork正确执行并返回的时候,其结果为0——这正好与引子部分的代码相应和)。
然后是最为关键的一步,这一步设置了新进程的执行流起点:
p->thread.ip = (unsigned long) ret_from_fork;在ret_from_fork中发现了 jmp syscall_exit 语句,通过上一课我们知道这意味着在执行ret_from_fork之后系统调用就应该恢复现场了。恢复现场的时候不可避免会通过恢复ip来继续执行程序,这也就解释了为什么程序能够继续执行ret_from_fork后面的语句。
fork的前一部分是由父进程执行的,从ret_from_fork中开始个进程开始独立执行后面的部分,最后分别对fork调用的返回值进行判断,从而执行不同的if-else分支。
总结:
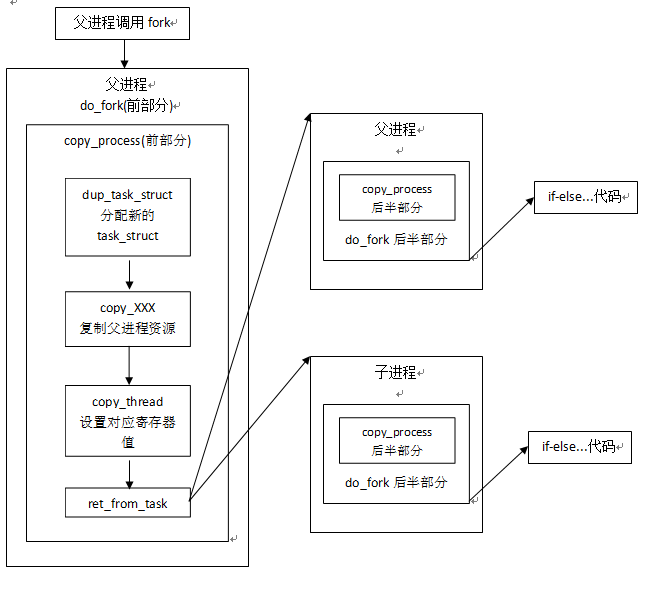
通过上述分析,我们验证了引子部分对fork执行过程的猜想,即:复制、区分、执行。整个fork的执行过程大致可以用下面的流程图表示:















 475
475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









