







许松原创,转载请注明出处
《Linux内核分析》MOOC课程 http://mooc.study.163.com/course/USTC-1000029000
引
这是本次线上课程的最后一周,本次课程将会分析schedule()函数的执行过程,并结合之前所学来理解Linux进程调度以及切换的过程。
分析
借用上一次课程的实验,打上断点:
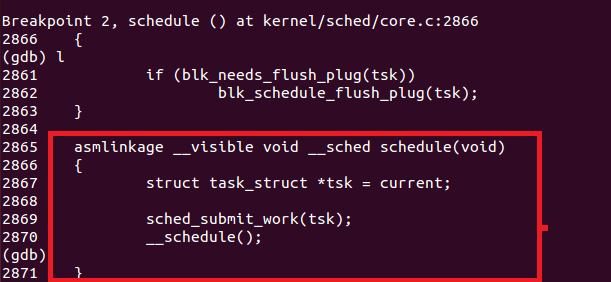
schedule()函数首先调用了sched_submit_work(),这个函数主要是用来避免死锁的:进程如果需要进入休眠状态,那么就应当将它的IO请求挂到队列中,否则进程将会占用IO(休眠进程占用IO会使得其他需要IO的进程无法获得IO而等待,如果休眠进程一直处于休眠状态,很自然就发生死锁了)。
真正的调度发生在__schedule()函数调用中:
运行队列链表把处于TASK_RUNNING状态的所有进程组织在一起,所以我们在函数的开头就可以看到两个task_struct类型的变量:prev和next。switch_count记录了进程上下文切换的次数;rq则是CPU的运行进程队列。
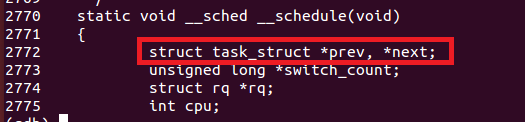
首先,函数获取当前工作的CPU,然后获取该CPU的运行进程队列并进一步获取当前运行的进程,将其赋值给prev。
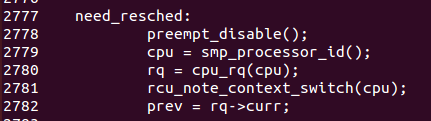
在对当前进程的状态进行设置之后(主要是信号量的设置以便针对进程的不同状态进行处理),接下来的工作是决定哪一个进程将会作为切换进程:
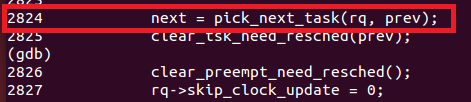
pick_next_task函数的描述是:* Pick up the highest-prio task。而这个函数内部使用上一节课中提到过的方法(函数指针)来通过不同的策略选择正确的候选进程:
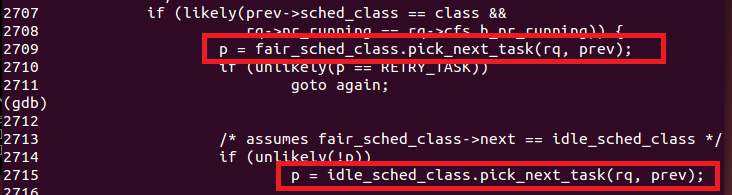
现在我们有了想要切换的进程next。由于我们已知进程切换的过程关键在于进程上下文之间的切换,因此我们跳过之后的一系列的安全性检查步骤,来到下面的语句:
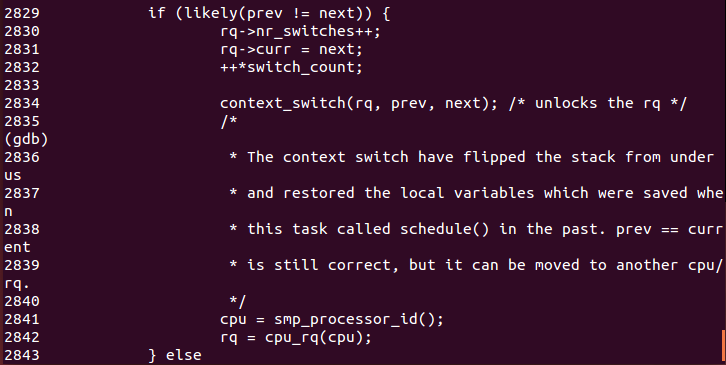
可以看到,在对当前进程和将要切换进程的查重之后更新相关计数,并将运行队列中的当前进程设置为next,调用contex_switch()进行进程上下文的切换。
同样,我们跳过contex_switch()中内存方面的设置,来到switch_to函数:

switch_to()函数后面的barrier是用来防止编译器以及CPU对指令做出优化(这两位有可能会对代码的指令执行顺序作出更改,虽然目的是为了使得程序更高效,但是可能会导致程序执行的过程与期望不符从而导致错误),以便程序能够按照我们希望的运行起来(通过前面的学习我们知道内核在处理上下文切换的时候对寄存器中值的正确性要求极高,而一旦指令执行顺序被改,寄存器的值就有可能不正确,从而导致系统崩溃)。
#define switch_to(prev, next, last) \
do { \
/* \
* Context-switching clobbers all registers, so we clobber \
* them explicitly, via unused output variables. \
* (EAX and EBP is not listed because EBP is saved/restored \
* explicitly for wchan access and EAX is the return value of \
* __switch_to()) \
*/ \
unsigned long ebx, ecx, edx, esi, edi; \
\
asm volatile("pushfl\n\t" /* save flags */ \
"pushl %%ebp\n\t" /* save EBP */ \
"movl %%esp,%[prev_sp]\n\t" /* save ESP */ \
"movl %[next_sp],%%esp\n\t" /* restore ESP */ \
"movl $1f,%[prev_ip]\n\t" /* save EIP */ \
"pushl %[next_ip]\n\t" /* restore EIP */ \
__switch_canary \
"jmp __switch_to\n" /* regparm call */ \
"1:\t" \
"popl %%ebp\n\t" /* restore EBP */ \
"popfl\n" /* restore flags */ \
\
/* output parameters */ \
: [prev_sp] "=m" (prev->thread.sp), \
[prev_ip] "=m" (prev->thread.ip), \
"=a" (last), \
\
/* clobbered output registers: */ \
"=b" (ebx), "=c" (ecx), "=d" (edx), \
"=S" (esi), "=D" (edi) \
\
__switch_canary_oparam \
\
/* input parameters: */ \
: [next_sp] "m" (next->thread.sp), \
[next_ip] "m" (next->thread.ip), \
\
/* regparm parameters for __switch_to(): */ \
[prev] "a" (prev), \
[next] "d" (next) \
\
__switch_canary_iparam \
\
: /* reloaded segment registers */ \
"memory"); \
} while (0)对于该段宏的分析可以看到:
传入参数:next进程的sp与ip传给next_sp与next_ip
输出参数:prev_sp与prev_ip传给prev的task_struct
这段汇编代码首先保存当前ESP到prev的task_struct中,然后把next的sp放到ESP中,从而建立新进程的内核堆栈。然后将后面 “1:\t”的地址保存到EIP中(这一点参见第二课) ,再将next的ip压栈。
后面的jmp __switch_to则是一个非call的函数调用,这种类型的函数调用不会对堆栈造成影响,当返回的时候,pop stack正好会把之前压栈的next_ip出栈到EIP,从而使得CPU运行新的进程。而__switch_to本身则是将next进程运行需要的一系列资源比如IO、局部存储等设置好,当函数“返回”的时候确保next进程可以正确执行。
当这个宏执行完毕的时候,由于prev的值被存储在寄存器eax中,而这个eax最后又被赋值给last,从而使得新进程能够得到到前面的进程的task_struct。新进程接着这个宏将整个schedule函数执行完毕。
总结
综上述,Linux中进程切换的一般步骤为:
- 检测当前进程的状态,挂起当前进程的IO请求以防止死锁;
- 获取当前运行CPU,以及它的可运行进程队列;
- 从进程队列中获取当前进程的task_struct,并通过进程调度算法(操作系统课程长谈的那些)来从队列中选择一个合适的进程作为待调入进程;
- 检测待调入进程的状态以确保其正确性;
- 使用switch_to宏来进行当前进程与待调入进程的切换(期间完成新进程的进程资源准备工作);
- 新的进程完成schedule函数,结束整个进程切换过程。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









