







您好,我是 @马哥python说,一枚10年程序猿。
一、爬取目标
前些天我分享过一篇微博的爬虫:
马哥python说:【python爬虫案例】爬取微博任意搜索关键词的结果,以“唐山打人”为例
但我的学习群中的小伙伴频繁讨论微博评论的爬取,所以,我们再分享这篇微博评论的爬虫。
注意区分这两个爬虫:
上次:爬指定搜索关键词的搜索结果的博文数据
本次:爬单一微博的微博下方评论数据
二、展示爬取结果
首先,看下部分爬取数据:

爬取字段含:
微博id、评论页码、评论id、评论时间、评论点赞数、评论者IP归属地、评论者姓名、评论者id、评论者性别、评论者关注数、评论者粉丝数、评论内容。
三、爬虫代码
上次在文章中讲到,微博有3种访问方式,分别是:
PC端网页:https://weibo.com/
移动端:https://weibo.cn/
手机端:https://m.weibo.cn/
本次依然采用第3种访问方式爬取,即,通过手机端爬取。
打开张天爱的目标微博:https://m.weibo.cn/detail/4806418774099867
URL地址中的"4806418774099867"就是微博id了。
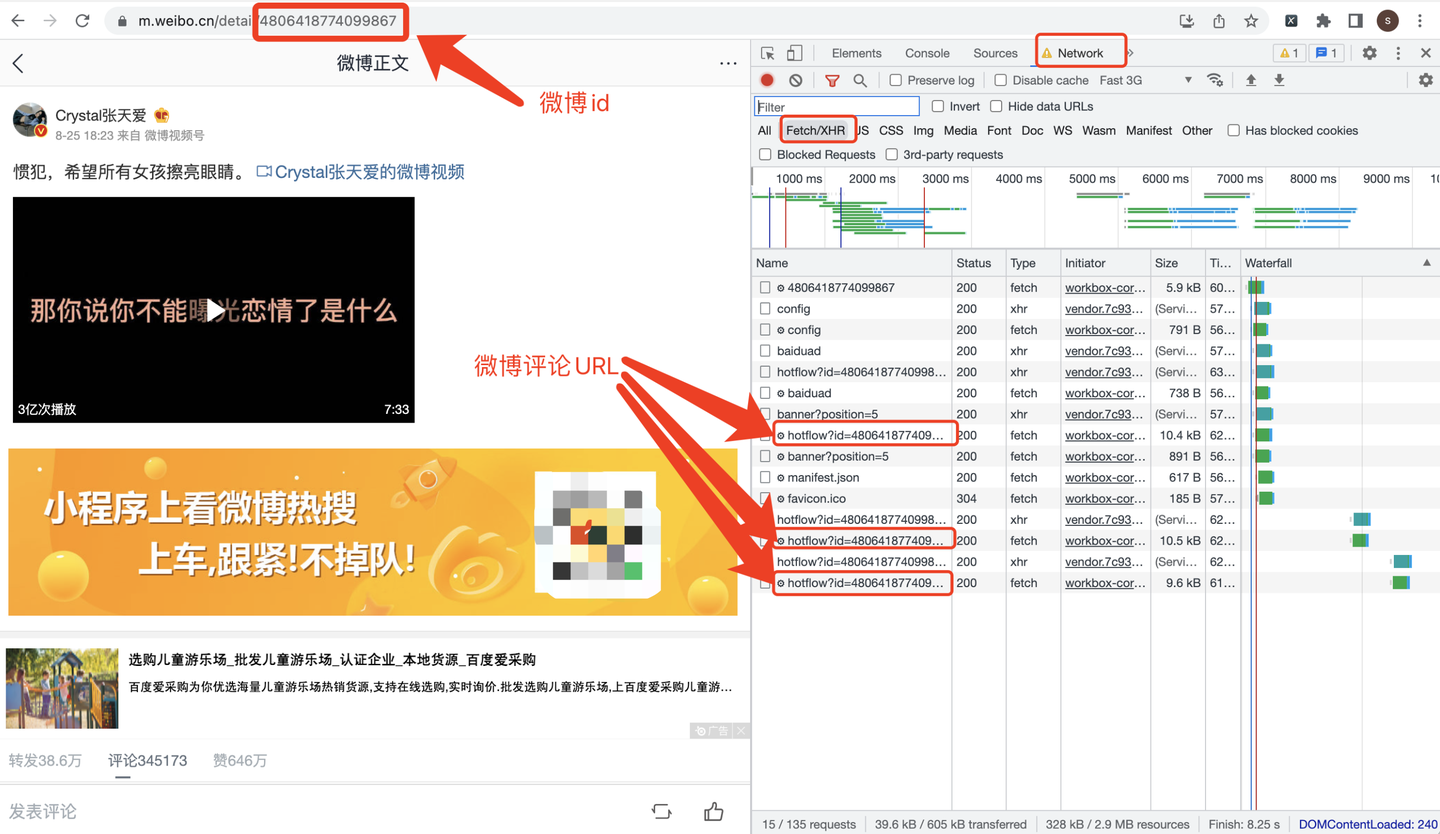
cookie从哪里获取呢?看截图:
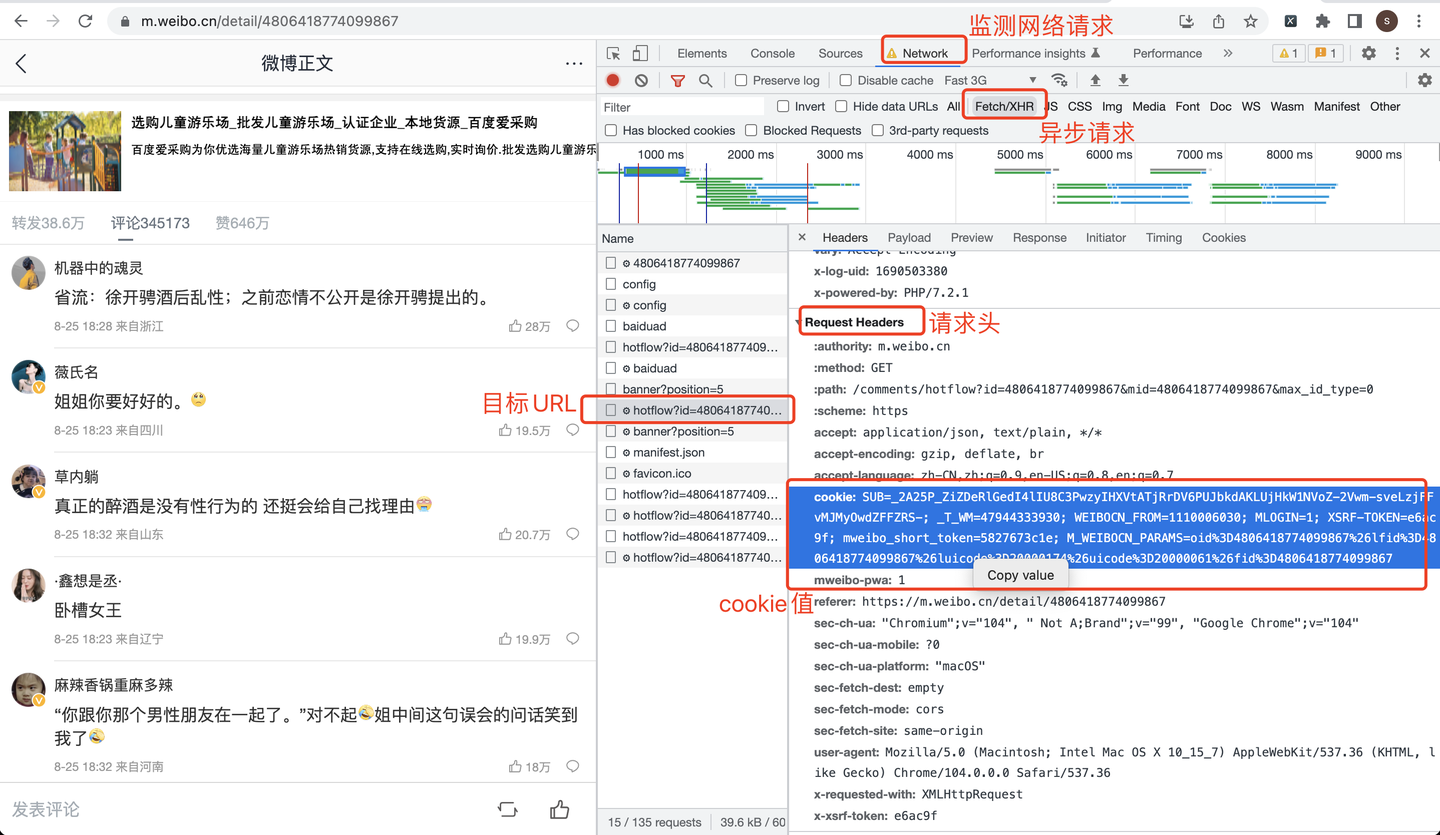
把微博id带入到Python爬虫代码中,下面展示部分爬虫代码。
关键逻辑来了!
关键逻辑来了!
关键逻辑来了!
重要的事情说三遍,外加敲黑板!!
关键逻辑:(非常关键!如果处理不好,就只能爬到第1页,很多小伙伴卡在这了)
max_id的处理:
if page == 1: # 第一页,没有max_id参数
url = 'https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id_type=0'.format(weibo_id, weibo_id)
else: # 非第一页,需要max_id参数
if max_id == '0': # 如果发现max_id为0,说明没有下一页了,break结束循环
print('max_id is 0, break now')
break
url = 'https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id_type=0&max_id={}'.format(weibo_id,
weibo_id,
max_id)
如果是第一页,不用传max_id参数。
如果非第一页,需要传max_id参数,它的值来自于上一页的r.json()[‘data’][‘max_id’]
下面,就是正常爬虫逻辑了。
首先,向微博页面发送请求:
r = requests.get(url, headers=headers) # 发送请求
print(r.status_code) # 查看响应码
print(r.json()) # 查看响应内容
下面,是解析数据的处理逻辑:
datas = r.json()['data']['data']
for data in datas:
page_list.append(page)
id_list.append(data['id'])
dr = re.compile(r'<[^>]+>', re.S) # 用正则表达式清洗评论数据
text2 = dr.sub('', data['text'])
text_list.append(text2) # 评论内容
time_list.append(trans_time(v_str=data['created_at'])) # 评论时间
like_count_list.append(data['like_count']) # 评论点赞数
source_list.append(data['source']) # 评论者IP归属地
user_name_list.append(data['user']['screen_name']) # 评论者姓名
user_id_list.append(data['user']['id']) # 评论者id
user_gender_list.append(tran_gender(data['user']['gender'])) # 评论者性别
follow_count_list.append(data['user']['follow_count']) # 评论者关注数
followers_count_list.append(data['user']['followers_count']) # 评论者粉丝数
最后,是保存数据的处理逻辑:
df = pd.DataFrame(
{
'微博id': [weibo_id] * len(time_list),
'评论页码': page_list,
'评论id': id_list,
'评论时间': time_list,
'评论点赞数': like_count_list,
'评论者IP归属地': source_list,
'评论者姓名': user_name_list,
'评论者id': user_id_list,
'评论者性别': user_gender_list,
'评论者关注数': follow_count_list,
'评论者粉丝数': followers_count_list,
'评论内容': text_list,
}
)
if os.path.exists(v_comment_file): # 如果文件存在,不再设置表头
header = False
else: # 否则,设置csv文件表头
header = True
# 保存csv文件
df.to_csv(v_comment_file, mode='a+', index=False, header=header, encoding='utf_8_sig')
print('结果保存成功:{}'.format(v_comment_file))
篇幅有限,请求头、cookie、循环页码、数据清洗等其他细节不再赘述。
四、同步视频
详细讲解源码:
【2023微博评论爬虫】详细讲解用python爬几千条微博评论数据!
五、获取完整源码
附完整源码:【2023微博评论爬虫】用python爬上千条微博评论,突破15页限制!
推荐阅读:
微博评论分析大屏:马哥python说:【技术流吃瓜】python大屏分析"张天爱"微博网友评论
爬微博搜索结果:马哥python说:【python爬虫案例】爬取微博任意搜索关键词的结果,以“唐山打人”为例
我是马哥python说 ,一名10年程序猿,持续分享python干货中!
















 1451
1451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











