







 物理拓扑通常,我们在客户端和服务器进行通信的时候,一般会使用okhttp、cronet、curl、ace、urlconnection等网络库帮助我们完成客户端和服务器之间的交互。如果站在网络库之上看,客户端和服务器之间就像一条直连的线路,两边直接可以通信。这是因为网络库和操作系统本身帮我们屏蔽了网络通信中最复杂的部分,真正让客户端有通信能力的是网卡,而客户端数据能到达服务器端是靠整个互联网上多个设备的接力和配合,这种接力和配合是在tcp/ip协议规范的基础上正常进行的。从物理实体上看..
物理拓扑通常,我们在客户端和服务器进行通信的时候,一般会使用okhttp、cronet、curl、ace、urlconnection等网络库帮助我们完成客户端和服务器之间的交互。如果站在网络库之上看,客户端和服务器之间就像一条直连的线路,两边直接可以通信。这是因为网络库和操作系统本身帮我们屏蔽了网络通信中最复杂的部分,真正让客户端有通信能力的是网卡,而客户端数据能到达服务器端是靠整个互联网上多个设备的接力和配合,这种接力和配合是在tcp/ip协议规范的基础上正常进行的。从物理实体上看..
物理拓扑
通常,我们在客户端和服务器进行通信的时候,一般会使用okhttp、cronet、curl、ace、urlconnection等网络库帮助我们完成客户端和服务器之间的交互。如果站在网络库之上看,客户端和服务器之间就像一条直连的线路,两边直接可以通信。
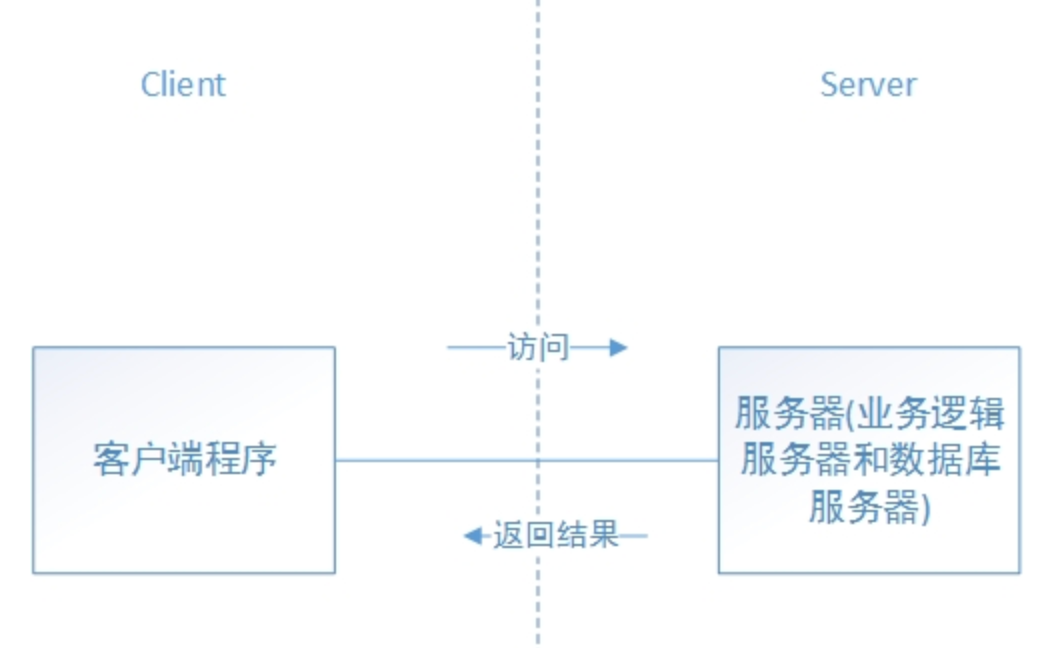
这是因为网络库和操作系统本身帮我们屏蔽了网络通信中最复杂的部分,真正让客户端有通信能力的是网卡,而客户端数据能到达服务器端是靠整个互联网上多个设备的接力和配合,这种接力和配合是在tcp/ip协议规范的基础上正常进行的。
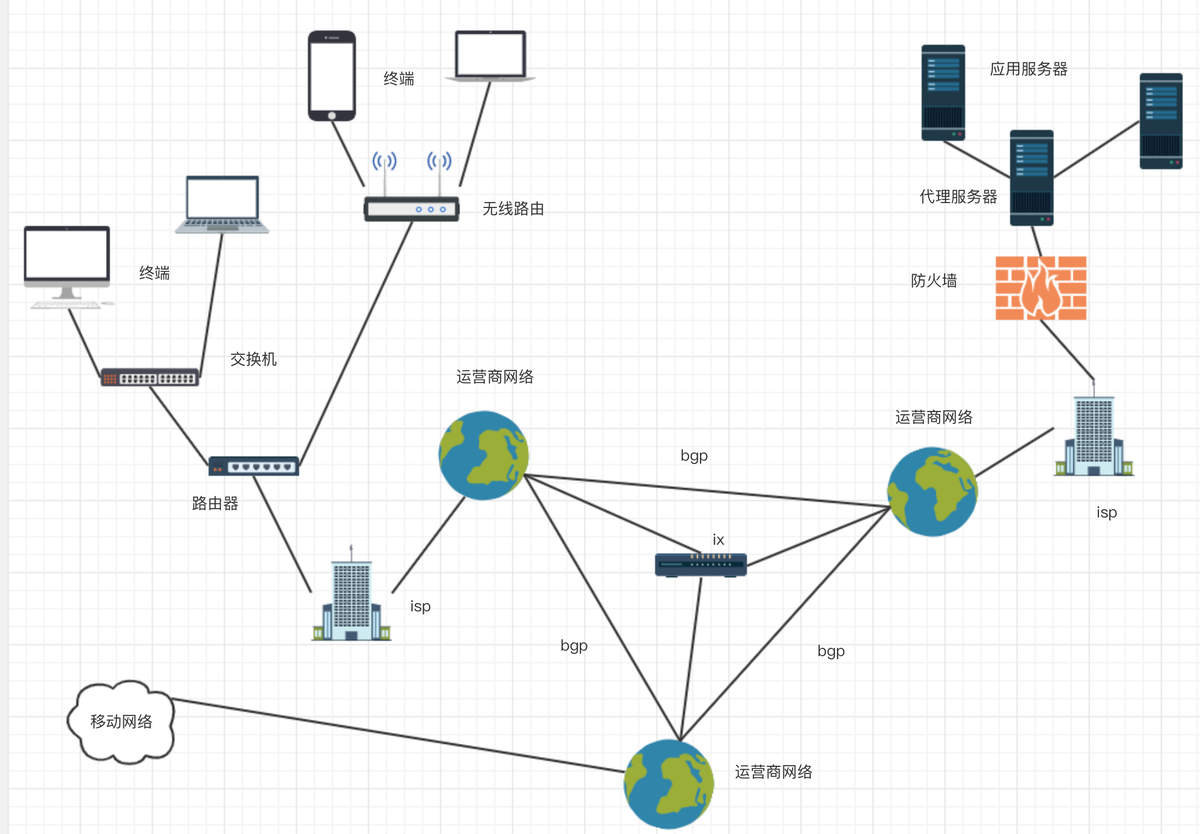
从物理实体上看,终端设备上的程序要连接到远程服务器,需要经历以下过程:
- 终端上的应用程序通过网络库将数据提交到os内核
- os内核通过网卡驱动程序将数据传给网卡
- 网卡将数据转为电信号,发送到交换机、集线器或者路由器
- 路由器将数据转发到网关
- 网关通过adsl、光线等将数据转到isp
- isp把数据转入骨干网
- 数据包在骨干网进行分组传输到达服务端isp
- 数据包经过isp到达服务器
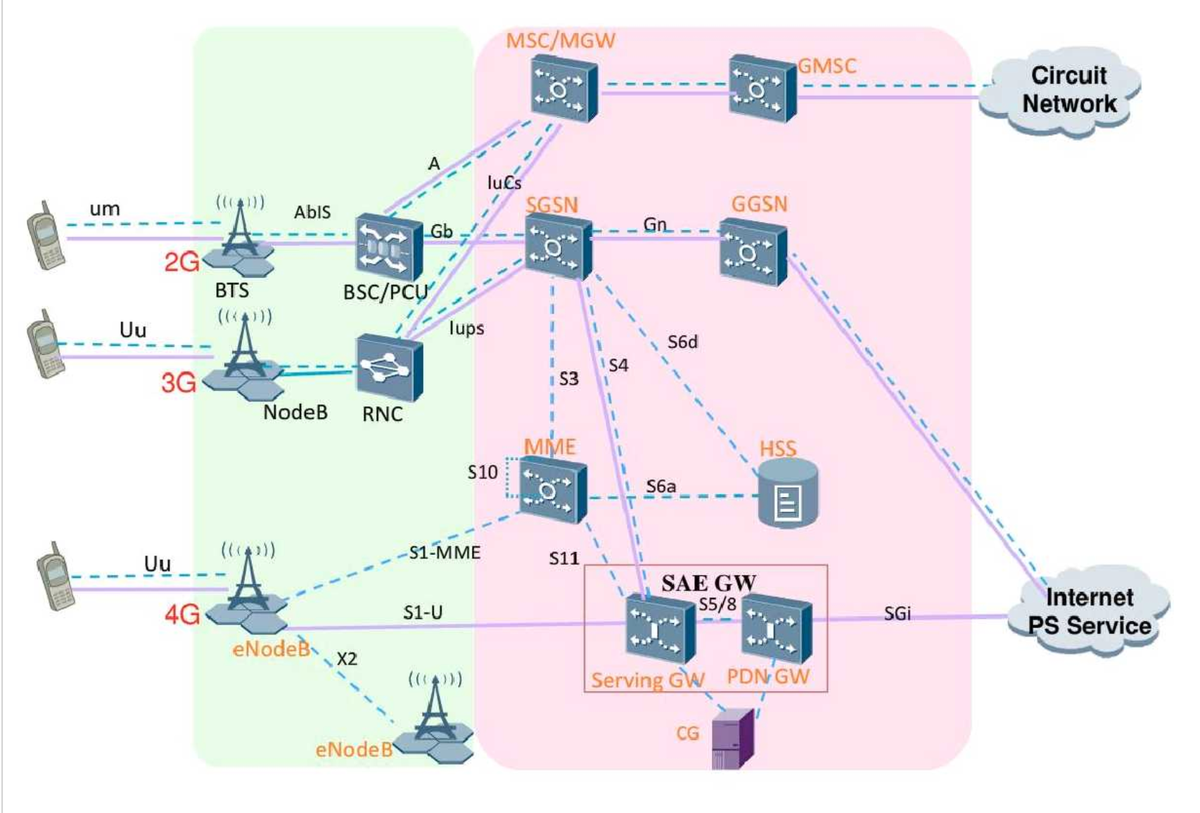
如果是移动网络,isp之前前的部分更为复杂,终端通基站接入后,数据包还需要经过不同的调制、编解码处理,最后进入互联网内部。
TCP/IP协议栈
TCP/IP协议族按照层次由上到下,层层包装。最上面的就是应用层了,这里面有http,ftp,等等我们熟悉的协议。而第二层则是传输层,著名的TCP和UDP协议就在这个层次(不要告诉我你没用过udp玩星际)。第三层是网络层,IP协议就在这里,它负责对数据加上IP地址和其他的数据(后面会讲到)以确定传输的目标。第四层是叫数据链路层,这个层次为待传送的数据加入一个以太网协议头,并进行CRC编码,为最后的数据传输做准备。再往下则是硬件层次了,负责网络的传输,这个层次的定义包括网线的制式,网卡的定义等等(这些我们就不用关心了,我们也不做网卡),所以有些书并不把这个层次放在tcp/ip协议族里面,因为它几乎和tcp/ip协议的编写者没有任何的关系。发送协议的主机从上自下将数据按照协议封装,而接收数据的主机则按照协议从得到的数据包解开,最后拿到需要的数据。这种结构非常有栈的味道,所以某些文章也把tcp/ip协议族称为tcp/ip协议栈。

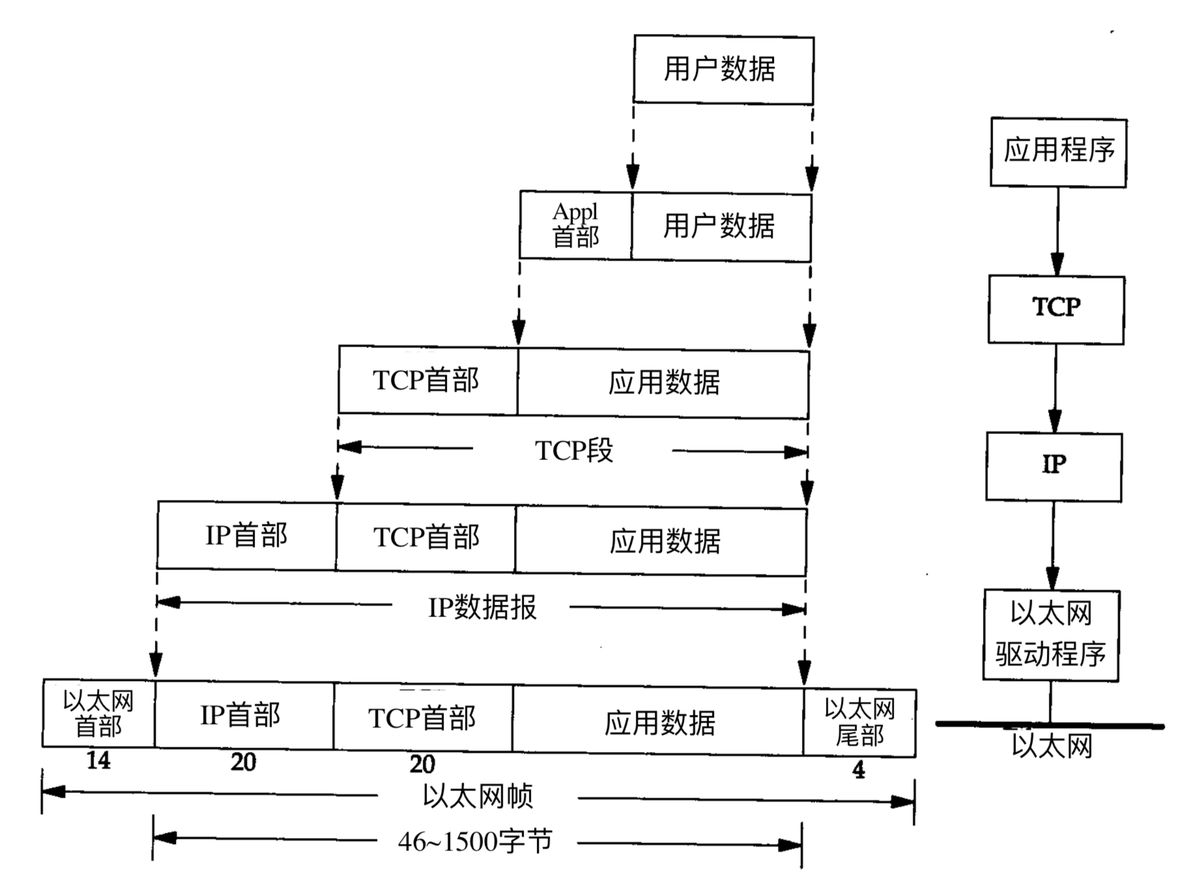
应用层数据格式比较多,有个媒体格式(mp4、3gp、webp等)、文本格式(json、html等)、二进制格式等。
传输层数据格式主要是tcp或者udp分组,传输层之间的通信主要通过端口号。
网络层数据格式主要是packet,不同进程之间的通信主要通过ip地址。
数据链路层数据主要以Frame的格式通信,Frame的大小一般通过MTU来定义,每个Frame通过物理地址MAC来标记发送地址和接收地址。
getprop | grep "mtu"
setprop dhcp.wlan0.mtu 1500客户端
通过netstat可以查看客户端目前的网络连接状态。
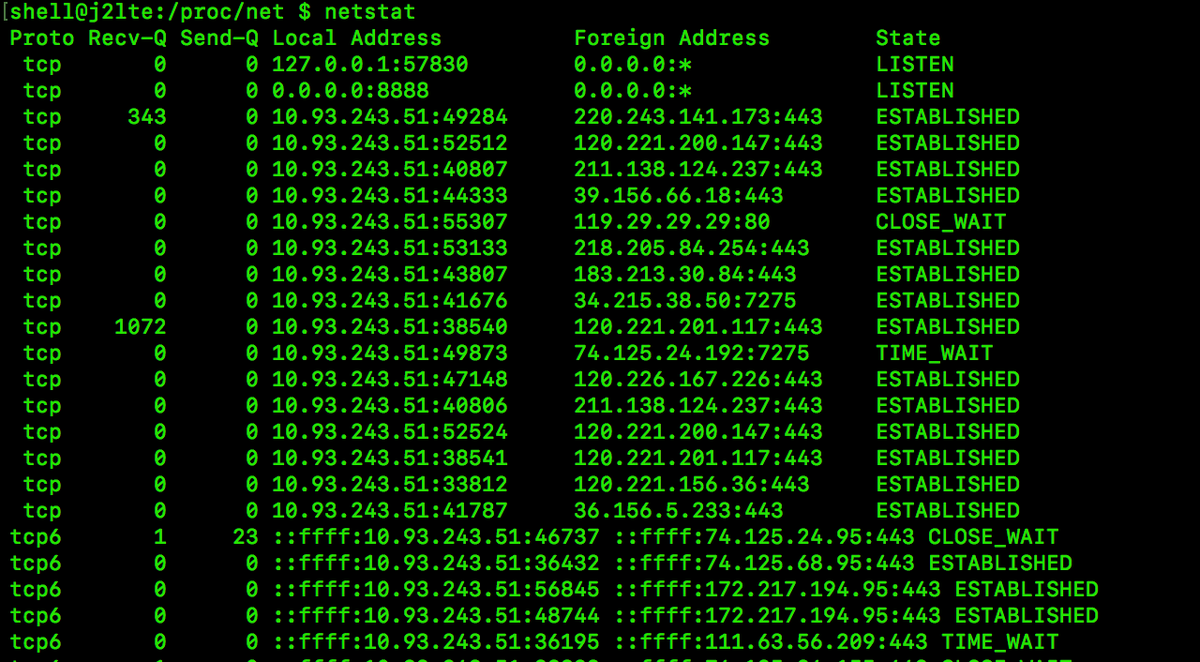
/proc/net下面也可以看出网络设备状态信息


终端上对网络的处理分为三层,一层是应用程序的处理,中间一层是os内核的处理,最底层是网卡驱动的处理。
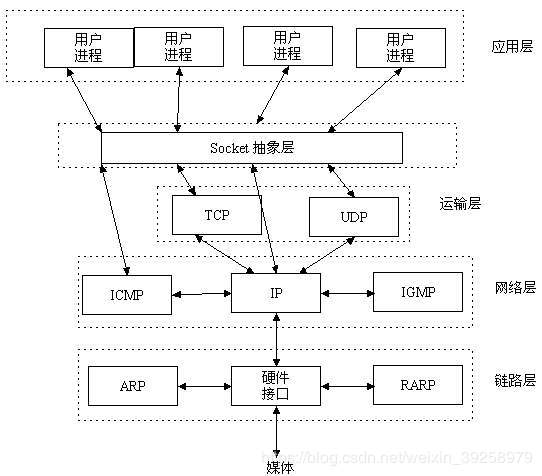
socket提供了接口控制协议参数
int getsockopt(int sockfd,int l 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2190
2190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











