







第1章 需求分析及实现思路
1.1 需求分析
主订单的应付金额【origin_total_amount】一般是由所有订单明细的商品单价*数量
汇总【sku_price*sku_num】组成。
但是由于优惠、运费等都是
以订单为单位
进行计算的,所以减掉优惠、加上运费会得到
一个最终实付金额【
final_total_amount】。
但问题在于如果是
以商品进行交易额分析
,就需要把优惠、运费分摊到购买的每个商品
中。
1.2 业务流程图
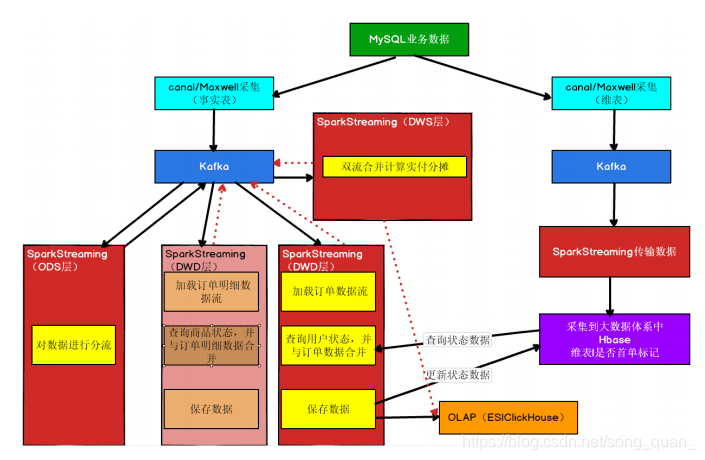
1.3 实现思路
1.3.1 功能 1:准备订单明细数据
前面我们已经将订单和用户、是否首单状态以及省份进行关联,并且将宽表保存到了
ES 中,但是订单表中缺少订单明细,通过订单明细我们才能与商品进行关联,所以我们需
要先准备订单明细数据,再让订单明细与商品进行关联。
1.3.2 功能 2:双流合并
所以除了订单事实表与维表进行合并形成宽表,还需要
订单事实表
与
订单明细事实表
进
行合并形成更大的宽表
1.3.3 功能 3:订单明细实付金额分摊
计算出订单中每一笔商品分摊后的实付金额
1.3.4 功能 4:将订单及明细保存到 ClickHouse
1.3.5 功能 5:发布数据接口(统计新增交易额)
从 ClickHouse 中,查询出订单和订单明细数据,并提供数据接口,方便其它使用者进
行统计分析。


















 1211
1211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











