







1. 技术详情

CDC 的实现方式主要有两种,分别是基于查询和基于日志:
基于查询:查询后插入、更新到数据库即可,无须数据库的特殊配置以及账号权限。它的实时性基于查询频率决定,只能通过提高查询频率来保证实时性,而这必然会对 DB 造成巨大压力。此外,因为是基于查询,所以它无法捕获两次查询之间数据的变更记录,也就无法保证数据的一致性。
基于日志:通过实时消费数据的变更日志实现,因此实时性很高。而且不会对 DB 造成很大的影响,也能够保证数据的一致性,因为数据库会将所有数据的变动记录在变更日志中。通过对日志的消费,即可明确知道数据的变化过程。它的缺点是实现相对复杂,因为不同数据库的变动日志实现不一样,格式、开启方式以及特殊权限都不一样,需要针对每一种数据库做相应的适配开发
-
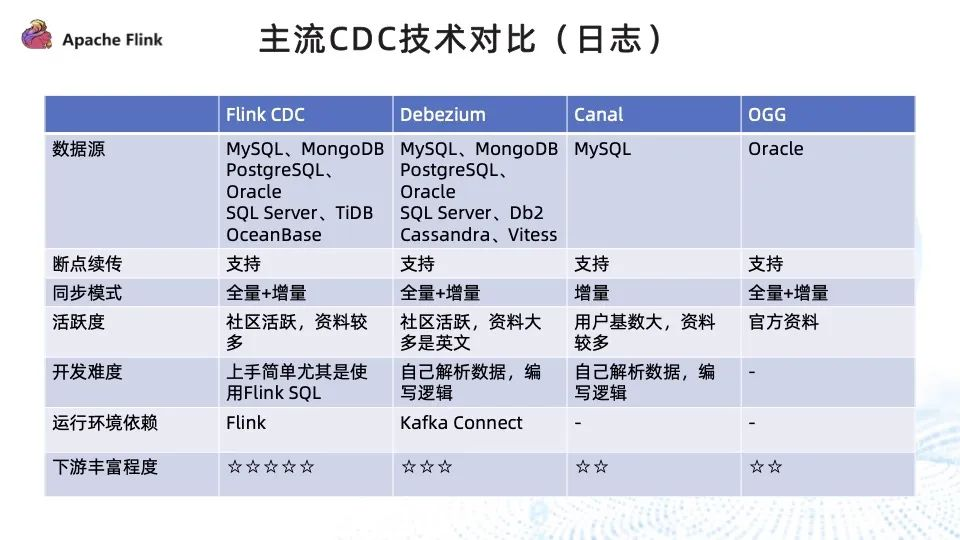
数据源:Flink CDC 除了对传统的关系型数据库做到了很好的支持外,对文档型、NewSQL(TiDB、OceanBase) 等当下流行的数据库都能够支持;Debezium 对数据库的支持相对没有那么广泛,但是对主流的关系型数据库都做到了很好的支撑;Canal 和 OGG 只支持单一的数据源。
-
断点续传:四种技术都能够支持。
-
同步模式:除了 Canal 只支持增量,其他技术均支持全量 + 增量的方式。而全量 + 增量的方式意味着第一次上线时全量到增量的切换过程全部可以通过 CDC 技术实现,无须人为地通过全量的任务加上增量的 job 去实现全量 + 增量数据的读取。
-
活跃度:Flink CDC 拥有非常活跃的社区,资料丰富,官方也提供了详尽的教程以及快速上手教程;Debezium 社区也相当活跃,但资料大多是英文的;Canal 的用户基数特别大,资料也相对较多,但社区活跃度一般;OGG 是 Oracle 的大数据套件,需要付费,只有官方资料。
-
开发难度:Flink CDC 依靠 Flink SQL 和 Flink DataStream 两种开发模式,尤其是 Flink SQL,通过非常简单的 SQL 即可完成数据同步任务的开发,开发上手尤为简单;Debezium 需要自己解析采集到的数据变更日志进行单独处理,Canal 亦是如此。
-
运行环境依赖:Flink CDC 是以 Flink 作为引擎,Debezium通常是将 Kafka connector 作为运行容器;而 Canal 和 OGG 都是单独运行。
-
下游丰富程度:Flink CDC 依靠 Flink 非常活跃的周边以及丰富的生态,能够打通丰富的下游,对普通的关系型数据库以及大数据存储引擎 Iceberg、ClickHouse、Hudi 等都做了很好的支持;Debezium 有 Kafka JDBC connector, 支持 MySQL 、Oracle 、SqlServer;Canal 只能直接消费数据或将其输出到 MQ 中进行下游的消费;OGG 因为是官方套件,下游丰富程度不佳
现有数据同步方式
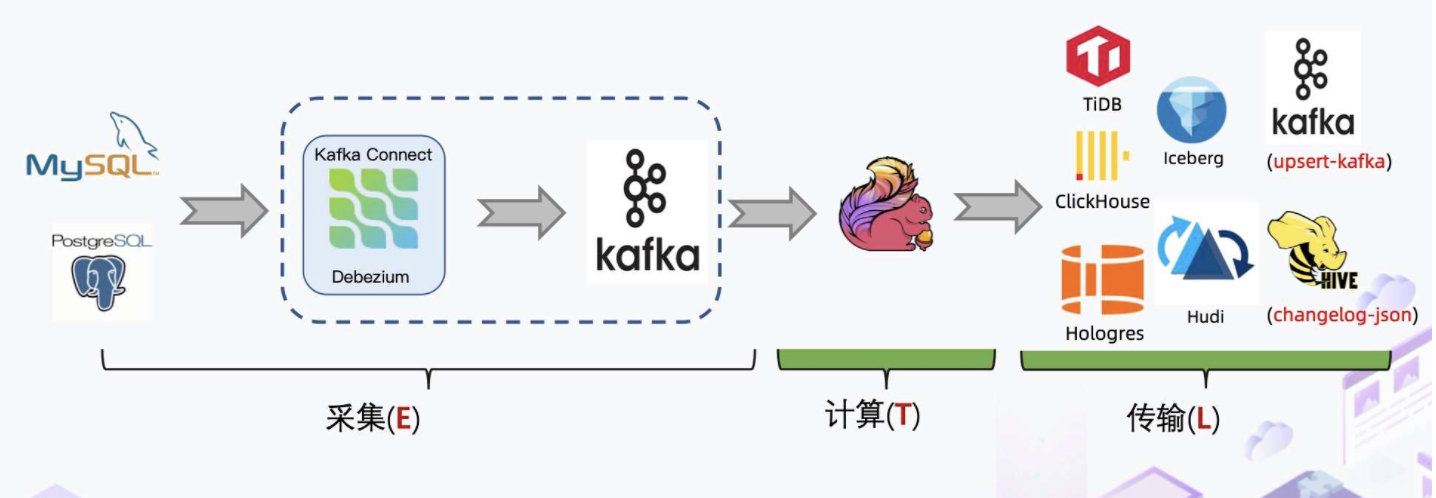
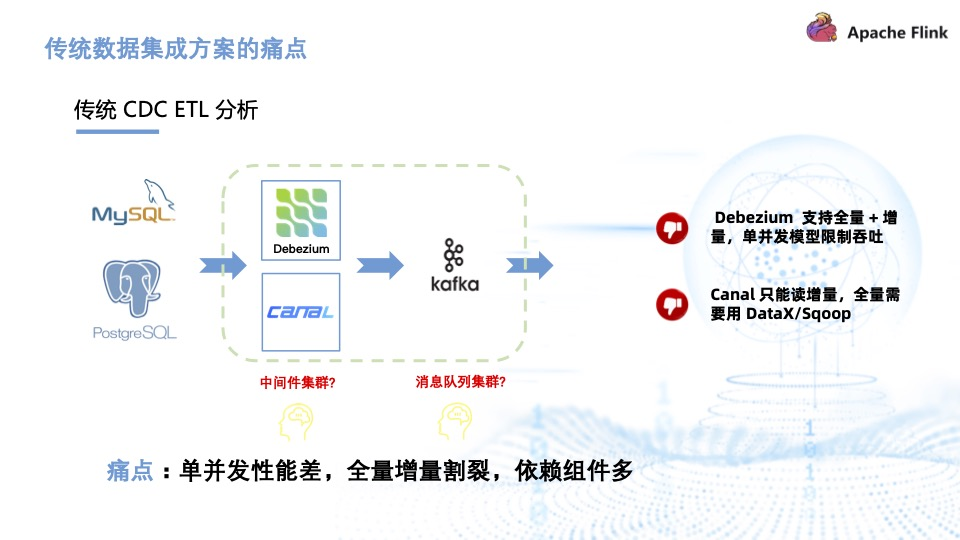
传统 CDC ETL 分析里引入了很多组件比如 Debezium、Canal,都需要部署和维护, Kafka 消息队列集群也需要维护。Debezium 的缺陷在于它虽然支持全量加增量,但它的单并发模型无法很好地应对海量数据场景。而 Canal 只能读增量,需要 DataX 与 Sqoop 配合才能读取全量,相当于需要两条链路,需要维护的组件也增加。因此,传统 CDC ETL 分析的痛点是单并发性能差,全量增量割裂,依赖的组件较多
新的同步方式
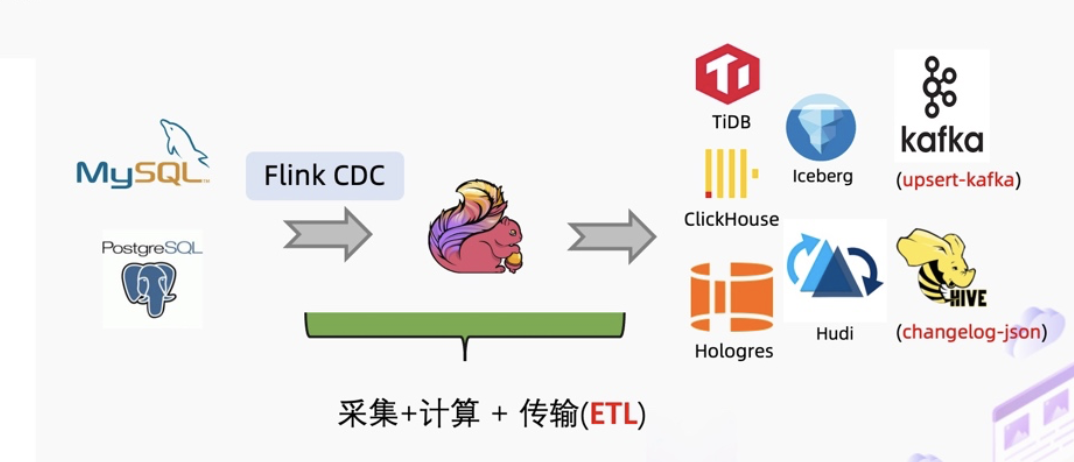
Flink CDC 2.0 在 MySQL CDC 上实现了增量快照读取算法,在最新的 2.2 版本里 Flink CDC 社区将增量快照算法抽象成框架,使得其他数据源也能复用增量快照算法。
增量快照算法解决了全增量一体化同步里的一些痛点。比如 Debezium 早期版本在实现全增量一体化同步时会使用锁,并且且是单并发模型,失败重做机制,无法在全量阶段实现断点续传。增量快照算法使用了无锁算法,对业务库非常友好;支持了并发读取,解决了海量数据的处理问题;支持了断点续传,避免失败重做,能够极大地提高数据同步的效率与用户体验
SQLserver的CDC
当前版本的 SqlServer CDC ,存在的问题有以下三个
-
快照过程中锁表:锁表操作对于 DBA 和在线应用都是不可忍受的, DBA 无法接受数据库被夯住,同时也会影响在线应用。
-
快照过程中不能 checkpoint:不能 checkpoint 就意味着快照过程中一旦失败,只能重新开始跑快照过程,这对于大表非常不友好。
-
快照过程只支持单并发:千万级、上亿级的大表,在单并发的情况下需要同步十几甚至几十个小时,极大束缚了 SqlServer CDC 的应用场景。
参考文档:
Flink CDC 2.0 正式发布,详解核心改进-阿里云开发者社区Apache Flink学习网
-
2.2 版本新增 OceanBase,PolarDB-X,SqlServer,TiDB 四种数据源接入,均支持全量和增量一体化同步。 至此,Flink CDC 已支持 12 种数据源。
-
Flink CDC 兼容 Flink 1.13 和 Flink 1.14 两个大版本,2.2 版本的所有 Connector 都支持跑在 Flink 1.13.* 或 Flink 1.14.* 的集群上。
-
提供增量快照读取框架,方便其他连接器接入,其他连接器采用该框架后,便可以提供无锁算法,并发读取,断点续传等功能。
-
MySQL CDC 支持动态加表,该功能可以在无需重新读取已有表的基础上,增加需要监控的表,添加的表会自动先同步该表的全量数据再无缝切换到同步增量数据。
-
MongoDB CDC 支持正则表达式过滤集合,该功能可以让用户在作业中指定所需监控的库名和集合名,用户可以用一个作业中监控多个数据库或多个集合
演示: SqlServer CDC 导入 Elasticsearch — CDC Connectors for Apache Flink® documentation
3. 用法用例
flinkSQL
CREATE TABLE `Data_Input` (
id BIGINT,
actor VARCHAR,
alias VARCHAR,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc', -- 可选 'mysql-cdc' 和 'postgres-cdc'
'hostname' = '*.*.*.*', -- 数据库的 IP
'port' = '3306', -- 数据库的访问端口
'username' = 'debezium', -- 数据库访问的用户名(需要提供 SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT, SELECT, RELOAD 权限)
'password' = '****', -- 数据库访问的密码
'database-name' = 'YourData', -- 需要同步的数据库
'table-name' = 'YourTable' -- 需要同步的数据表名
);
CREATE TABLE `Data_Output` (
id BIGINT,
actor VARCHAR,
alias VARCHAR,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = '******', -- 请替换为您的实际 PostgreSQL 连接参数
'table-name' = 'MyTable', -- 需要写入的数据表
'username' = 'user', -- 数据库访问的用户名(需要提供 INSERT 权限)
'password' = 'helloworld' -- 数据库访问的密码
);
INSERT INTO `Data_Output` SELECT * FROM `Data_Input`;DataStream API
// 数据配置 sqlserver
SourceFunction<String> sourceFunction = SqlServerSource.<String>builder()
.hostname(dbInfo.get("host"))
.port(Integer.valueOf(dbInfo.get("port")))
.database(dbInfo.get("db")) // monitor sqlserver database
.tableList(dbInfo.get("tableList")) // monitor products table
.username(dbInfo.get("userName"))
.password(dbInfo.get("passWord"))
.debeziumProperties(debeziumProperties)
.deserializer(new JsonDebeziumDeserializationSchema()) // converts SourceRecord to JSON String
.build();
// 环境配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
CheckpointConfig config = env.getCheckpointConfig();
config.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.enableCheckpointing(checkPointInterval);
env.setParallelism(parallelism);
DataStream<String> stream = env.addSource(sourceFunction);
// 微批次写入
SingleOutputStreamOperator<DataEvent> outputStream = stream.map(new Transition());
ProcessWindowFunction<DataEvent, ArrayList<DataEvent>, String, TimeWindow> processWindowFunction = new ProcessWindowFunction<DataEvent, ArrayList<DataEvent>, String, TimeWindow>() {
@Override
public void process(String s, Context context, Iterable<DataEvent> elements, Collector<ArrayList<DataEvent>> out) throws Exception {
ArrayList<DataEvent> dataList = new ArrayList<>();
for (DataEvent e : elements) {
dataList.add(e);
}
if (dataList.size() > 0) {
logger.info(s + " 窗口数据 " + dataList.size() + " 条");
out.collect(dataList);
}
}
};
SingleOutputStreamOperator<ArrayList<DataEvent>> batchProcess = outputStream.keyBy((KeySelector<DataEvent, String>) value -> value.key)
.window(TumblingProcessingTimeWindows.of(Time.seconds(timeWindow)))
.process(processWindowFunction);
SinkToHologresOdsBatch sinkToHologresOdsBatch = new SinkToHologresOdsBatch();
sinkToHologresOdsBatch.open();
batchProcess.addSink(sinkToHologresOdsBatch);
env.execute(taskName);4. QA
Q1 需要开启 SqlServer 自己的 CDC 吗?
SqlServer CDC 的功能就是基于 SqlServer 数据库自己的 CDC 特性实现的
Q2 物化视图通过什么方式去刷新定时任务触发器?
通过 Flink CDC 将需要生成物化视图的 SQL 放在 Flink 里运行,通过原表的变动触发计算,然后同步到物化视图表里。
Q3 SqlServer CDC 在消费 transaction log 时有瓶颈吗?
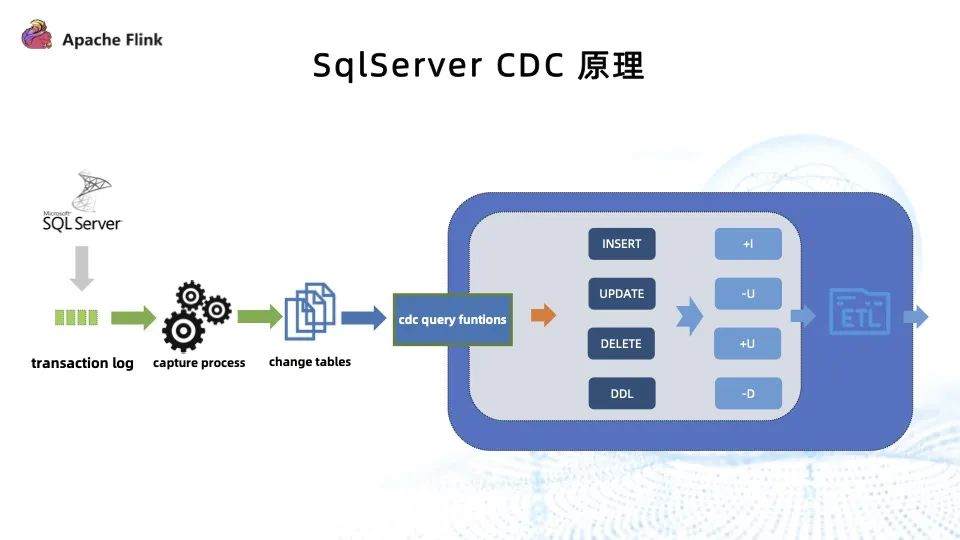
SqlServer 并没有直接消费 log,其原理是 SqlServer capture process 去匹配 log 内哪些表开启了 CDC ,然后将这些表从日志里捞到开启 CDC 表的变更数据,再转插到 change table 里,最后通过开启 CDC 之后数据库生成的 CDC query function 获取到数据的变更。
Q4 Flink CDC 高可用如何保障同步任务过多或密集处理方案?
Flink 的高可用依赖于 Flink 特性比如 checkpoint 等来保证。同步任务过多或处理方案密集的情况,建议使用多套 Flink 下游集群,然后根据同步的实时性区分对待,将任务发布到相应的集群中。
Q5 中间需要 Kafka 吗?
取决于同步任务或数仓架构是否需要将中间数据做 Kafka 落地。
Q6 个数据库中有多张表,可以放到一个任务里运行吗?
取决于开发方式。如果是 SQL 的开发方式,要实现一次性写多表只能通过多个任务。但 Flink CDC 提供了另外一种比较高阶的开发方式 DataStream ,可以将多表放到一个任务里运行
Q7 Flink CDC 支持读取 Oracle 从库的日志吗?
目前还无法实现。
Q8 通过 CDC 同步后两个端的数据质量如何监控,如何比对?
目前只能通过定时抽样来做数据质量的检查,数据质量问题一直是业内比较棘手的问题。
Q9 如果采集增删表,SqlServer CDC 需要重启吗?
SqlServer CDC 目前不支持动态加表的功能
Q10 同步任务会影响系统性能吗?
基于 CDC 做同步任务肯定会影响系统性能,尤其是快照过程对数据库会有影响,进而影响应用系统。将来会做限流、对所有 connector 做并发无锁的实现,都是为了扩大 CDC 的应用场景以及易用性。
Q11 全量和增量的 savepoint 怎么处理?
(未通过并发无锁框架实现的连接器)全量过程中不可以触发 savepoint,增量过程中如果需要停机发布,可通过 savepoint 恢复任务
Q12 MySQL 上亿大表全量和增量如何衔接?
并发无锁实现一致性快照,完成全量和增量的切换
同步实践
FlinkCDC实时同步SQLserver数据到Hologres
-
使用jdbc sink单条数据入库约70毫秒,存在大量变更时候数据积压严重
-
解决方案:通过滚动窗口(1-3s),实现微批次同步,在满足时间到达1s或者数据条数1000条任意条件时执行一次事务提交
-
-
批量插入大量数据,在消费部分数据后,存在后续无法消费情况。例如:操作10万条数据,出现消费7万数据,后续不再消费。
















 499
499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











