






这里首先介绍什么是cdc
CDC是Change Data Capture(变更数据捕获)的简称。其核⼼原理是监测并捕获数据库的变动(增删改等),将 这些变更按发⽣的顺序捕获,当然也可以写⼊到消息队列中供其他服务消费
cdc捕获数据
实现CDC即捕获数据库的变更数据有两种机制:CDC主要分为基于查询和基于Binlog两种方式,这两种之间的区别:
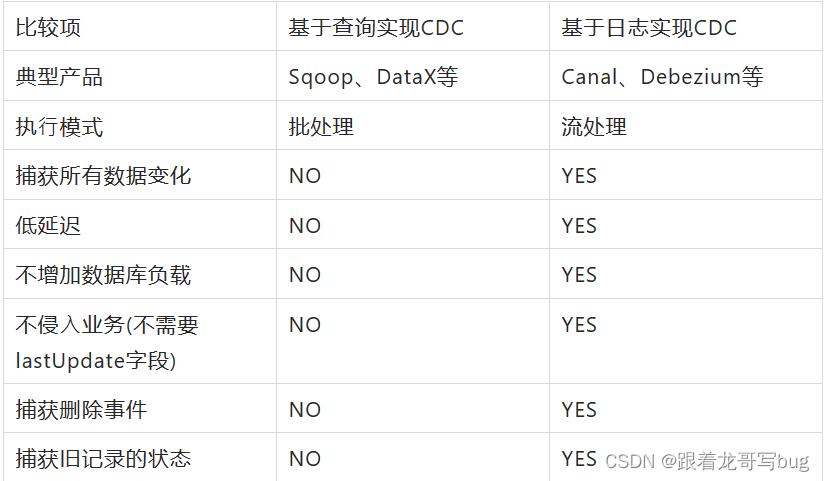
根据图1可以看到基于cdc可以实现无需入侵业务,业务解耦,无需更改业务模型
基于cdc的工具debezium
Debezium 可以解决数据抽取及转换工作。它可以对接 MySQL、SQL Server、Oracle、MongoDB 等多种SQL及NoSQL数据库,把这些数据库的数据持续以统一的格式发送到 Kafka 的主题,供下游进行实时消费。flink正是集成了debezium实现了cdc的功能
flinkcdc在实战时带来的优势
传统业务逻辑中,一般由第三方采集工具将数据从数据库中的取出,然后将数据输出到消息中间件(例如:kafka)。再由flink消费kafka中的数据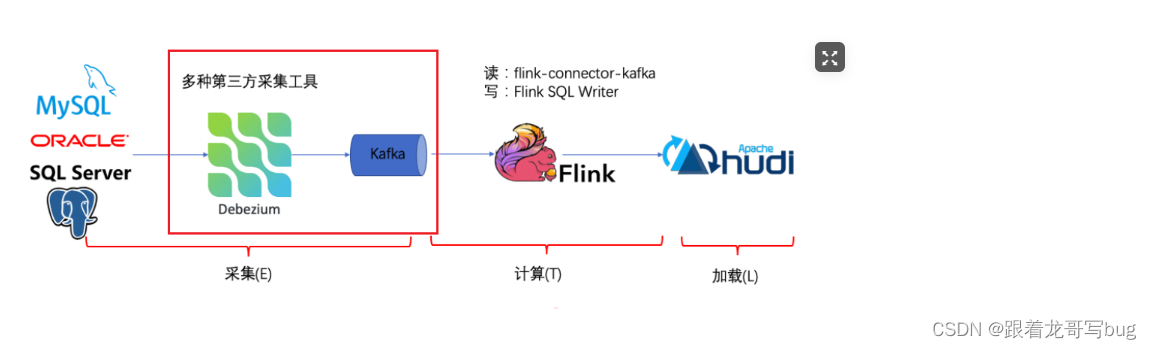
Flink CDC的基本理念就是去替换上图中红色线框内的采集组件和消息队列,从⽽简化传输链路,降低维护成本。同时更少的组件使系统整体架构更稳定。
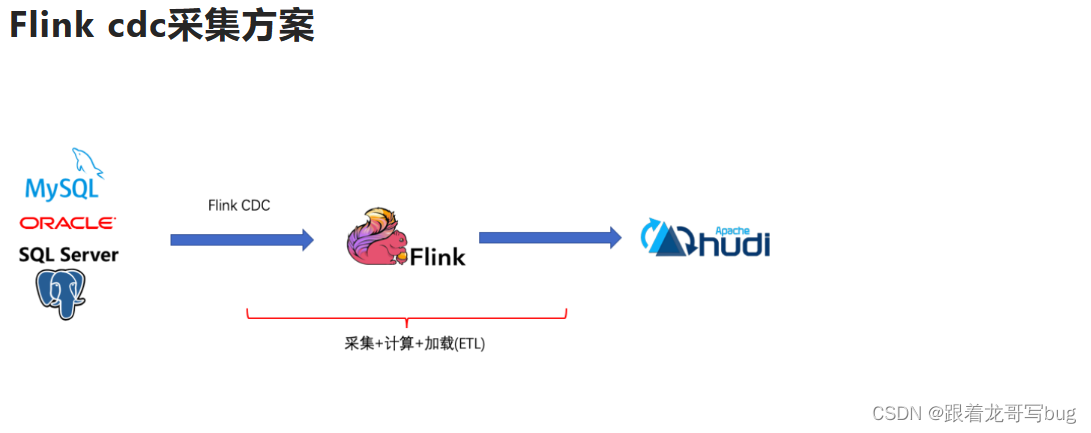
flinkcdc支持多种数据库
Flink CDC使用(数据采集CDC方案比较)-阿里云开发者社区 (aliyun.com)
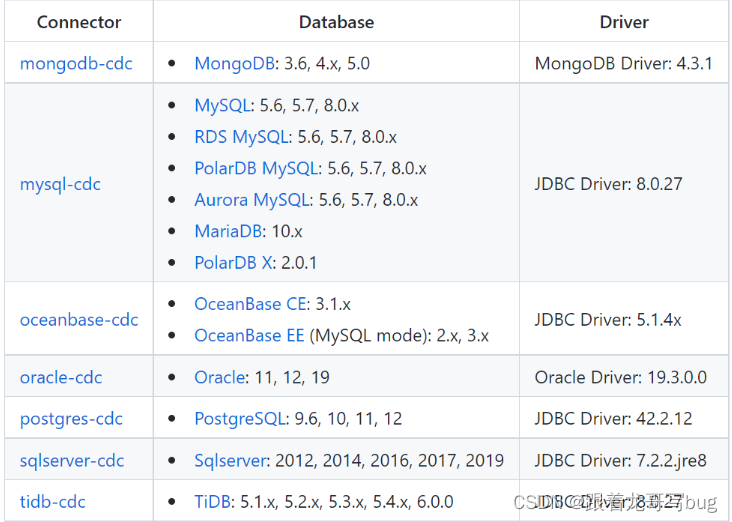
我们以mysql为例:
配置启动模块参数-scan.startup.mode:
initial: 在第一次启动时读取数据库中全量数据,然后读取 binlog 数据。这个模式可以得到所有数据。initial 是默认的启动模式。latest-offset:只读取binlog中的数据。不在读取原始数据
flink-cdc-connectors/mysql-cdc.md at master ·Ververica/flink-CDC-connectors (github.com)
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("ip")
.port(p)
.databaseList("config") // set captured database, If you need to synchronize the whole database, Please set tableList to ".*".
.tableList("config.table_process") // set captured table
.username("root")
.password("aaaaaa")
.deserializer(new JsonDebeziumDeserializationSchema()) // converts SourceRecord to JSON String
.build();
return
env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")读取到flink中进行操作
总结
flinkcdc提供了低延时的流式处理平台,降低了数据的传输造成的时间和效率的浪费,且降低了集群的风险,集群搭建更加简单,可以直接采集数据而不通过kafka,直接进行运算















 8024
8024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









