







 本文介绍了在MATLAB中进行情感语音识别的特征提取过程。从读取*.txt和*.wav语音文件开始,讨论了wavread()与audioread()函数的区别,并强调了预处理操作的重要性,包括端点检测、预加重和加窗分帧。推荐的预处理参数为帧长256,帧移128。最后,提到了特征提取阶段,建议参考张雪英教授的书籍以获取传统声学特征。
本文介绍了在MATLAB中进行情感语音识别的特征提取过程。从读取*.txt和*.wav语音文件开始,讨论了wavread()与audioread()函数的区别,并强调了预处理操作的重要性,包括端点检测、预加重和加窗分帧。推荐的预处理参数为帧长256,帧移128。最后,提到了特征提取阶段,建议参考张雪英教授的书籍以获取传统声学特征。
1、首先是读取语音:
首先要知道语音信号常见的有:*.txt文本文件和*.wav语音文件;
为什么会有*.txt文件?
这个很好理解,对于*.wav可以理解为以为时间信号,经过采样之后就变成了离散的点,即为*.txt文件存放的一堆数字。接下来,看一下读取语音信号的两种方式:(注意这里使用的是MATLAB代码)
Example1:(*.txt--即把采样点读取出来)
fid=fopen('happy.txt','rt'); %打开文件
Example2:(*.wav)
[y,fs,nbits]=wavread('happy.wav');注意:wavread()该函数是适用于MATLAB2010版本,后期的版本就需要使用audioread(),(注意:由于2017年10月左右,matlab的大量陈旧老版本失效,后期的都是使用:audioread()来完成的。)但是这个函数的输出只有两个,见Example3。
Example3:(*.wav)
[y, fs]=audioread('happy.wav');注意:关于比特率在*.wav文件的属性中的详细信息中是可以看到的。可见MATLAB的不断更新的是为更简便、更快。
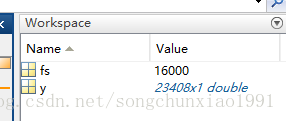
输出参数中:y表示的是采样点,fs表示的是采样频率
2、然后就是预处理操作(端点检测-预加重-加窗分帧)
这里有两个制胜函数:
①epdByVolZcr.m
function [epInSampleIndex, epInFrameIndex, soundSegment, zeroOneVec, volume] = epdByVolZcr(y, fs, nbits, epdParam, plotOpt)
% epdByVol: EPD based on volume only
% Usage: [epInSampleIndex, epInFrameIndex, soundSegment, zeroOneVec, volume] = epdByVol(y, fs, nbits, epdParam, plotOpt)
% epInSampleIndex: two-element end-points in sample index
% epInFrameIndex: two-element end-points in frame index
% soundSegment: resulting sound segments
% zeroOneVec: zero-one vector for each frame
% volume: volume
% y: input audio signals
% fs: sampling rate
% epdParam: parameters for EPD
% plotOpt: 0 for silence operation, 1 for plotting
%
% Example:
% waveFile='SingaporeIsAFinePlace.wav';
% [y, fs, nbits]=wavReadInt(waveFile);
% epdParam=epdParamSet(fs);
% p 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









