









前言
在《ELK接入微服务工程》章节中实现了通过ELK对微服务日志收集查询管理工作,那么对于大型系统,特别是微服务设计下的分布式系统,我们的日志来源非常之多,如果直接通过logstash收集输出至elasticsearch很有可能会导致elasticsearch奔溃,如何进行有效的流量控制显得很重要,消息队列能够很好的解决此顾虑。Kafka具有很好的分布式扩容能力,且在高并发场景下优势明显,故本章将基于Kafka与ELK整合,部署架构如下:
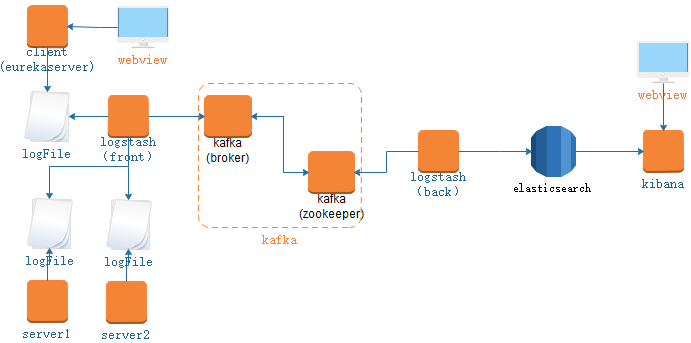
本章概要
1、准备工作;
2、前置Logstash配置;
3、后置Logstash配置;
4、启动各组件服务验证;
准备工作
本次组件如下:

其中logstash-front与logstash-back对应上面的部署架构图。
前置Logstash配置
切换至D:\ELK\logstash-front-5.3.0\bin目录,修改logstash.conf配置如下:
input {
file {
path => "D:/learnworkspace/springcloud-netfilx-demo/springcloud-eureka-register/log/*.log"
}
stdin { }
}
filter {
}
output {
kafka{
topic_id => "syslog"
bootstrap_servers => "127.0.0.1:9092"
batch_size => 5
compression_type => "snappy"
}
stdout { codec => rubydebug }
}
参数说明
:
- bootstrap_servers, :validate => :string, :default => 'localhost:9092'
kafka的地址
- topic_id, :validate => :string, :required => true
主题
- compression_type, :validate => ["none", "gzip", "snappy", "lz4"], :default => "none"
消息的压缩模式,默认是 none,可以有 gzip 和 snappy (暂时还未测试开启压缩与不开启的性能,数据传输大小等对比)。
- acks, :validate => ["0", "1", "all"], :default => "1"
消息的确认模式:
可以设置为 0: 生产者不等待 broker 的回应,只管发送.会有最低能的延迟和最差的保证性(在服务器失败后会导致信息丢失)
可以设置为 1: 生产者会收到 leader 的回应在 leader 写入之后.(在当前 leader 服务器为复制前失败可能会导致信息丢失)
可以设置为all: 生产者会收到 leader 的回应在全部拷贝完成之后。
- send_buffer_bytes, :validate => :number, :default => 131072
socket 的缓存大小设置,其实就是缓冲区的大小
- key_serializer, :validate => :string, :default => 'org.apache.kafka.common.serialization.StringSerializer'
- value_serializer, :validate => :string, :default => 'org.apache.kafka.common.serialization.StringSerializer'
消息体的系列化处理类,转化为字节流进行传输
- batch_size, :validate => :number, :default => 16384
异步模式下,每次发送的最大消息数
后置Logstash配置
切换至D:\ELK\logstash-back-5.3.0\bin目录,修改logstash.conf配置如下:
input {
kafka {
codec => "plain"
group_id => "logstash1"
auto_offset_reset => "earliest"
topics => ["syslog"]
bootstrap_servers => "127.0.0.1:9092"
consumer_threads => 5 # number (optional), default: 1
decorate_events => true # boolean (optional), default: false
}
stdin { }
}
filter {
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
}
stdout { codec => rubydebug }
}
参数说明:
- group_id, :validate => :string, :default => "logstash"
消费者分组,可以通过组 ID 去指定,不同的组之间消费是相互不受影响的,相互隔离。
- topics
指定消费话题,也是必填项目,指定消费某个 topic ,这个其实就是订阅某个主题,然后去消费。
- decorate_events :validate => :boolean, :default => false
在输出消息的时候会输出自身的信息包括:消费消息的大小, topic 来源以及 consumer 的 group 信息。
- request_timeout_ms
指定时间内没有消息到达就抛出异常,一般不需要改。
NOTE:
想要使用多个 logstash 端协同消费同一个 topic 的话,那么需要把两个或是多个 logstash 消费端配置成相同的 group_id 和 topics , 但是前提是要把 相应的 topic 分多个 partitions (区) ,多个消费者消费是无法保证消息的消费顺序性的。
- 这里解释下,为什么要分多个 partitions(区) , kafka 的消息模型是对 topic 分区以达到分布式效果。每个 topic 下的不同的 partitions (区) 只能有一个 Owner 去消费。所以只有多个分区后才能启动多个消费者,对应不同的区去消费。其中协调消费部分是由 server 端协调而成。不必使用者考虑太多。
- 从而会导致整个topic的消息消费是无序的,每个partitions(区)内部是有序的 。如果一定要保证消息的顺序,那就用一个 partition 。 kafka 的每个 partition 只能同时被同一个 group 中的一个 consumer 消费 。
启动各组件服务验证
1、elasticsearch 服务启动完成,通过访问
localhost:9200
验证如下:

2、启动前置logstash:

3、启动后置logstash:

NOTE:
目前我采用的是logstash5,其与logstash2的配置项有较大的差异,如果参考老版本的配置,启动会出现如下异常说明,正是版本不匹配造成:

解决方案分析
,找到如下目录文件
D:\ELK\logstash-back-5.3.0\vendor\bundle\jruby\1.9\gems\logstash-input-kafka-5.1.6\lib\logstash\inputs下的kafka.rb文件
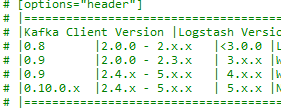
可以看到其版本的对应关系,同时也可以看到所有配置项参数的详细说明与默认配置。
同理out插件路径如下:
D:\ELK\logstash-back-5.3.0\vendor\bundle\jruby\1.9\gems\logstash-output-kafka-5.1.5\lib\logstash\outputs下的kafka.rb文件
4、启动zookeeper:
zookeeper-server-start ..\..\config\zookeeper.properties

5、启动kafka:
kafka-server-start.bat ..\..\config\server.properties

6、启动Kibana
..\kibana-5.3.0-windows-x86\bin\kibana.bat
7、启动eurekaserver服务
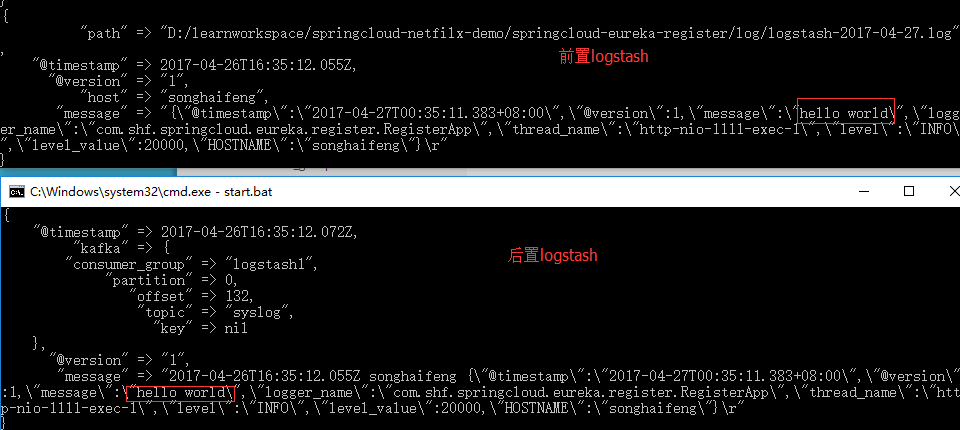
9、首先观察前置logstash控制台和后置logstash控制台,可以看到其均采集到了步骤8中产生的日志项:
10、继续观察kibana中查询结果
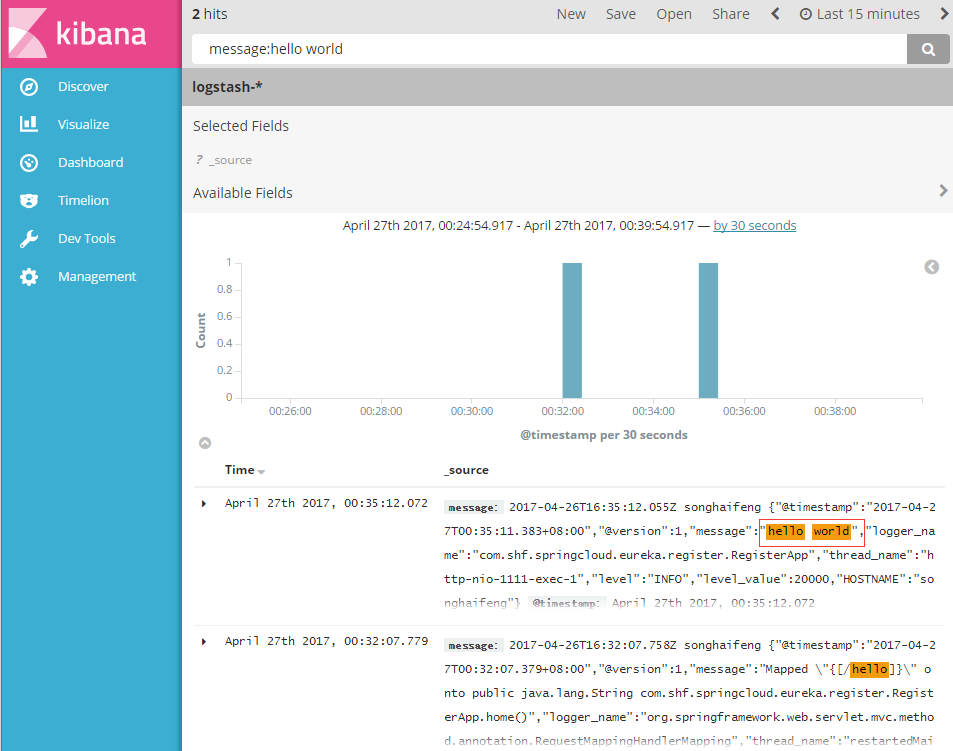
总结:
通过上述几个小节的配置和服务验证,ELK与Kafka集成完成。
扩展
logstash-kafka 插件输入和输出默认 codec 为 json 格式,在输入和输出的时候注意下编码格式。
1、首先来看下基于上述配置,我们采集到的日志内容,如下图:

可以看到消息传递过程中 logstash 默认会为消息编码内加入相应的时间戳和 hostname 等信息。如果不想要以上信息(一般做消息转发的情况下),可以使用以下配置:
output {
kafka{
topic_id => "syslog"
bootstrap_servers => "127.0.0.1:9092"
batch_size => 5
compression_type => "snappy"
codec => plain {
format => "%{message}"
}
}
stdout { codec => rubydebug }
}
此时我们的日志项将变为如下内容(舍掉了message后的时间戳和hostname):

2、在实际业务应用中,我们每个节点均需要保证高可用集群实现,大致应用的流程图:
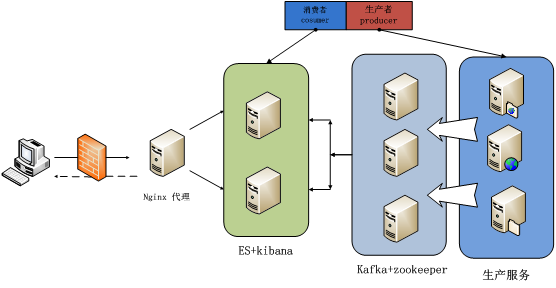
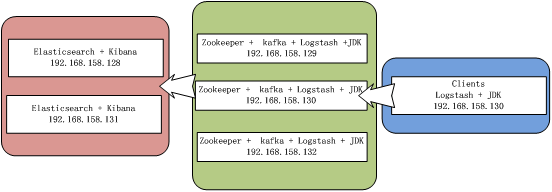
关于部署的网络拓补图:















 3490
3490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









