







在C的时代,还没有字符串类型,我们通过字符数组,或者char* 来处理 “字符串”。
通过在字符串的最后加上一个‘\0’, 来表示字符串的结束。所以没有字符串类型之前,我们总是在处理完字符串之后加个‘\0’,或者数字0(因为‘\0’对应的ASCII码值是0,注意字符‘0’对应的ASCII码值是0x30)
到了C++有了类型string,到了MFC有了 CString, 但是本质还是 char*。
所以我们在转换的时候,就是通过char*进行中转,按照这个思路,我们就能很好理解这个转换的过程。
在此之前,我们还得理解一个概念:
什么是指向常量的指针?其实就是指针指向的一个常量,指针指向的地址中的值不可变。
因为字符串本身规定就是不可变的,所以大多情况下,我们都是用 一个指向常量的指针
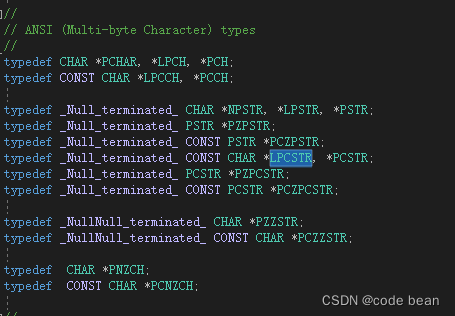
管理字符串。如:const char* a1; 这就是一个指向常量的指针,对应MFC中的LPCSTR
其中的这个C就是const的意思,这里我们可以看下MFC中的定义,下次就不怕,也不蒙B了:
好的,言归正传,看看标准C++中的字符串:
cout << "----------string转const char *----------------" << endl;
const char* a1;
string s1 = "asdf";
a1 = s1.c_str(); //应为字符串是不可变的,所以需要一个指向常量的指针,c_str:c中的字符串。
cout << a1 << endl;
cout << "-------------string转char *---------------" << endl;
//--这里相当于对了一个步骤,将const char * 转成 char *
//--于是就请了const_cast这个玩意帮忙,是个模板,看来想去掉const就找他就行!
char *a2 = const_cast<char *>(s1.c_str()) ;
cout << a2 << endl;
cout << "----------char*转string----------------" << endl;
string s2 = a2; //直接赋值即可!(高端的直接兼容低端的)
cout << s2 << endl;
cout << "----------char*与const char * 的互换----------------" << endl;
char* aa = "asdf";
const char* cc = aa; // 会报一个警告
aa = const_cast<char *>(cc);
cout << cc << " " << aa << endl;以上这段代码,介绍了string到char*的相互转换,以及如何去掉const。
接下来,再看看MFC中的CString:
首先,想将char* 或者 const char* 转成 CString,是直接可以赋值的(和转成string是一样的)
因为所有的字符串底层逻辑都是char*,它可以直接变成其他“字符串类型”。
既然如此,那么string转CString不就是找 char* 打个桥就可以了?
如:string -> CString (这种方式在Unicode模式和多字节模式下通用)
string str = "123123123123";
CString mfcstr;
mfcstr = CString(str.c_str()); 首先将string变成const char* 然后,通过const char*构造CString,就完成可这次转换。
再看:CString -> string, CString转string的时候需要考虑一个问题,就是MFC允许两种编码格式的编程,一种是多字节一种是Unicode,Unicode自己搞了个宽字符TCHAR,意图是兼容多国语言。所以如果你用Unicode char* 就不再是底层逻辑了,底层变成TCHAR*了。所以,这也是MFC搞死人的地方。
现在建议直接选多字节,有了UTF8的出现,多字节也能支持中文了。
这里简单的讲一下,字符串的历史,帮助大家加深理解:
由于计算机是美国人发明的,因此最早只有127个字母被编码到计算机中,也就是大小写英文字母、数字和一些符号,这个编码表称为ASCII编码。
例如:大写字母A的编码是65,小写字母z的编码时122。
要处理中文,显然一个字节是不够的,至少需要两个字节,且不能和ASCII编码冲突,所以我国制定了GB2312编码,用于把中文编进去。
可以想象,全世界上有上百种语言,日本把日文编写到Shift_JIS里,韩国把韩文编写到Euc-kr里,各国有各国的标准,就不可避免出现冲突,结果就是,在多语言混合的文本中就会显示乱码。
在此背景下,Unicode应运而生,Unicode把所有语言都统一到一套编码里,这样就不会有乱码问题了。
Unicode标准在不断发展,最常用的是用两个字节表示一个字符(如果要用到非常生僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
下面看看ASCII编码和Unicode编码的区别:ASCII编码时1个字节,二Unicode编码通常是两个字节。
那么新的问题就出现了:如果统一成Unicode编码,乱码问题从此消失了,但是写的文本基本上全部是英文时,用Unicode编码比ASCII编码多一倍存储空间,在存储和传输上十分不划算。
本着节约的精神,又出现了把Unicode编码转化成为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1~6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4~6个字节。如果你要传输的文本包含大量英文字母,用UTF-8编码就会节省空间。
各编码方式的比较
由上表可知,UTF-8编码有一个额外的好处,就是ASCII编码实际上可看成是UTF-8编码的一部分,所以只支持ASCII编码的大量历史遗留软件可在UTF-8编码下继续使用。
GetBuffer和GetString目前(VS2022下测试)我发现不管在Unicode还是多字节环境下都只能返回TCHAR*了,没法返回char*了。
但是我又发现了一种,兼容Unicode和多字节的转换方式: CW2A。
CString mfcstr = "456487894564啊士大夫十大";
str = CW2A(mfcstr);
那么MFC的字符串转换小结就是:
str = CW2A(mfcstr); // CString -> string
mfcstr = CString(str.c_str()); // string -> CString
它们都兼容,Unicode和多字节环境下的转换!!!
那么字符串处理我就看标准C++, MFC那一套处理方式我就懒得看了,会转换就行了。
C++字符串这里推荐文章:
C++ string类(C++字符串)完全攻略 (biancheng.net) http://c.biancheng.net/view/400.html好了,喜欢就点个赞吧~~~
http://c.biancheng.net/view/400.html好了,喜欢就点个赞吧~~~


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











