









散列表概念
- 散列函数和散列地址:类似于函数y=f(x),给定一个x,能得到一个y。散列函数,给定一个关键字,可以得到一个地址。但有时不同的key可能得到相同的p,需要 处理冲突。 p=Hey(key)。
- 散列表:一个有限连续的地址空间,用以存储散列函数计算得到相应散列地址的数据记录。
散列表主要两个问题
散列函数的构造
- 数字分析法:事先必须明确知道左右的关键字每一位上各种数字的分布情况,选取随机的几位作为散列地址。
- 平方取中法:顾名思义,就是将关键字平方之后取中间的几位作为散列地址。
- 折叠法:将关键字分割成位数相同的几部分,最后一部分的位数可以不同,然后取这几部分的叠加和作为散列地址。
又可以分为两种:
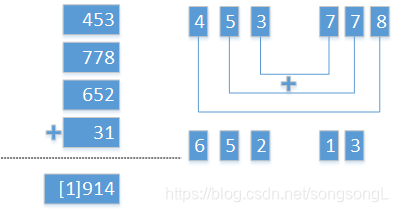
例如:key=45387765213,从左到右按3位分割,可以得到4部分:453,877,652,13 。
①移位叠加:

②边界叠加:
- 除留余数法:顾名思义,用关键字去除以不大于表长的数,然后取余数为散列地址。这是最常用的构造散列函数的方法。
处理冲突的方法
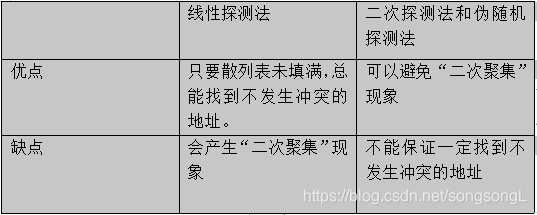
- 开放地址发:所谓开放地址,是指在寻找“下一个”空的散列地址时,原来的数组空间对所有的元素都是开放的。把寻找“下一个”位置的过程叫 探测。
Hi=(H(key)+di)%m
①线性探测法:di=1,2,3,…,m-1
②二次探测法:di=12,-12,22,-22,…,k2,-k2 (k<=m/2)
③伪随机探测法:di=伪随机生成数
- 链地址法:它和邻接表存储图有几分相似。把具有相同散列地址的记录放在同一个链表中,同时用一个数组存放各个链表的头指针。凡是散列地址为i的记录都已结点方式插入到以H[i]为头结点的单链表中。
散列表的查找
在散列表上进行查找的过程和创建散列表的过程基本一致。
-
给定关键字key,根据构造的散列函数计算H0=H(key)。
-
若单元H0为空,则所查元素不存在。
-
若单元H0中的关键字为key,则查找成功。
-
若单元H0中的关键字不为key,则按照所采用的处理冲突的方法继续查找。
①计算下一个散列地址Hi;
②若单元Hi为空,则所查元素不存在。
③若单元Hi中的关键字为key,则查找成功。
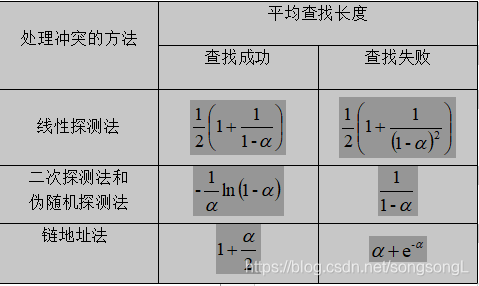
④若单元Hi中的关键字不为key,则继续。散列表的装填因子 α 定义为:

完整代码:
#include <stdio.h>
#include <stdlib.h>
#define m 12 //散列表表长
#define NULLKEY -1 //单元为空的标记
typedef struct //散列表结点类型
{
int *elem; //数据元素存储基地址,动态分配数组
int count; //当前数据元素个数
}HashTable;
int InitHashTable(HashTable *h) //初始化散列表
{
int i;
h->elem = (int *)malloc(sizeof(int) * m );
h->count=0;
if(h->elem == NULL)
{
printf("分配内存失败\n");
exit(-1);
}
for(i = 0; i < m; i++)
{
h->elem[i] = NULLKEY;
}
return 1;
}
int Hash(int key) //散列函数
{
return key % m; //除留余数法
}
void InsertHash(HashTable *h, int key) //将关键字插入散列表
{
int addr = Hash(key); //求散列地址
while(h->elem[addr] != NULLKEY) //如果不为空,则冲突
{
addr = (addr + 1) % m; //线性探测
}
h->elem[addr] = key; //直到有空位后插入关键字
h->count++;
}
int SearchHash(HashTable h, int key) //散列表查找关键字
{
int addr = Hash(key); //求散列地址
if(h.elem[addr]==NULLKEY) return -1; //如果为空,则元素不存在
else if(h.elem[addr] == key)
return addr; //如果单元中的关键字为key,则查找成功
else{
int i=0;
for(i=1;i<m;i++) {
addr = (addr + 1) % m; //线性探测
if(h.elem[addr] == NULLKEY)
return -1;
else if(h.elem[addr] == key)
return addr;
}
}
return -1;
}
int main()
{
int i=0;
HashTable h;
InitHashTable(&h); //初始化Hash表
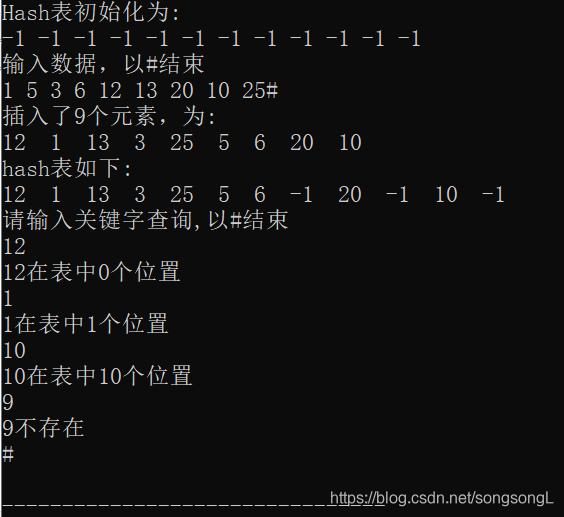
printf("Hash表初始化为:\n");
for(i = 0; i < m; i++)
{
printf("%d ", h.elem[i]);
}
printf("\n");
printf("输入数据,以#结束\n");
while(scanf("%d", &i))
{
if(i == '#') break;
InsertHash(&h,i);
if(h.count >= m)
{
printf("Hash表已满,自动退出插入\n");
break;
}
}
printf("插入了%d个元素,为:\n",h.count);
for(i = 0; i < m; i++)
{
if(h.elem[i]==-1) continue;
else printf("%d ", h.elem[i]);
}
printf("\n");
printf("hash表如下:\n");
for(i = 0; i < m; i++)
{
printf("%d ", h.elem[i]);
}
printf("\n");
printf("请输入关键字查询,以#结束\n");
int key;
scanf("%*[^\n]%*c"); //清空缓存区
while(scanf("%d",&key))
{
if(key == '#') break;
if(SearchHash(h, key)==-1)
printf("%d不存在\n",key);
else printf("%d在表中%d个位置\n",key,SearchHash(h, key));
}
return 0;
}
运行结果:














 6571
6571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









