







首先感谢敲代码的耗子,之前一直搞不懂登陆新浪微博的原理,看了他那篇文章之后,终于明白了基本原理。在这里主要是通过代码实现那篇文章的过程。
获取网页使用的包是requests,正则匹配用的是re,其他需要的还有base64、rsa、binascii。如果安装有pip,可以直接在cmd(linux在终端)中输入命令“pip install 包名”进行安装,包的安装方法有很多种,这里不详述。
另外,python3的代码,请看:http://bgods.cn/blog/post/29/
其实,过程的实现还是比较容易的。新浪微博登陆主要是post时提交表单的用户名与密码都是经过处理后才提交的。
##1.利用网页分析工具监控
我使用的是HttpAnalyzerStdV7工具对登陆过程进行监控(当然也可使用其他工具)。
首先打开新浪通行证http://login.sina.com.cn/
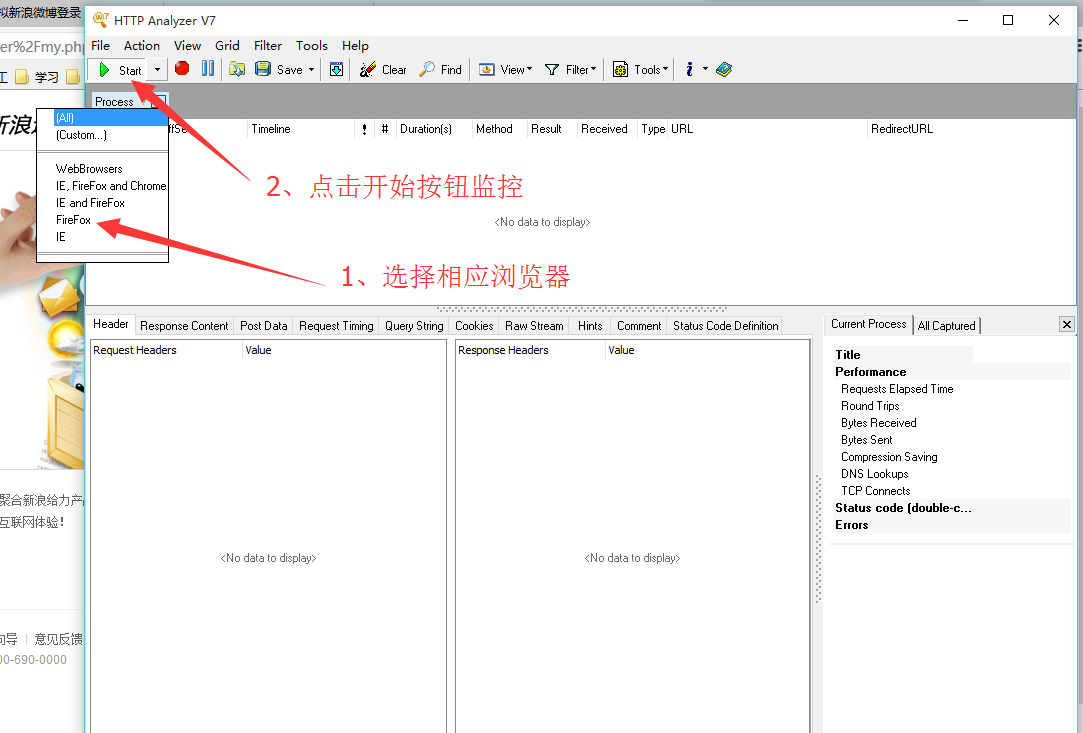
然后,打开HttpAnalyzerStdV7工具,并点击开始监控按钮
最后输入用户名和密码,登陆成功后回到HttpAnalyzerStdV7工具界面,点击”Post Data“,再找到post请求的url,就会看到一个用于最后登陆的要提交的表单,如下图:
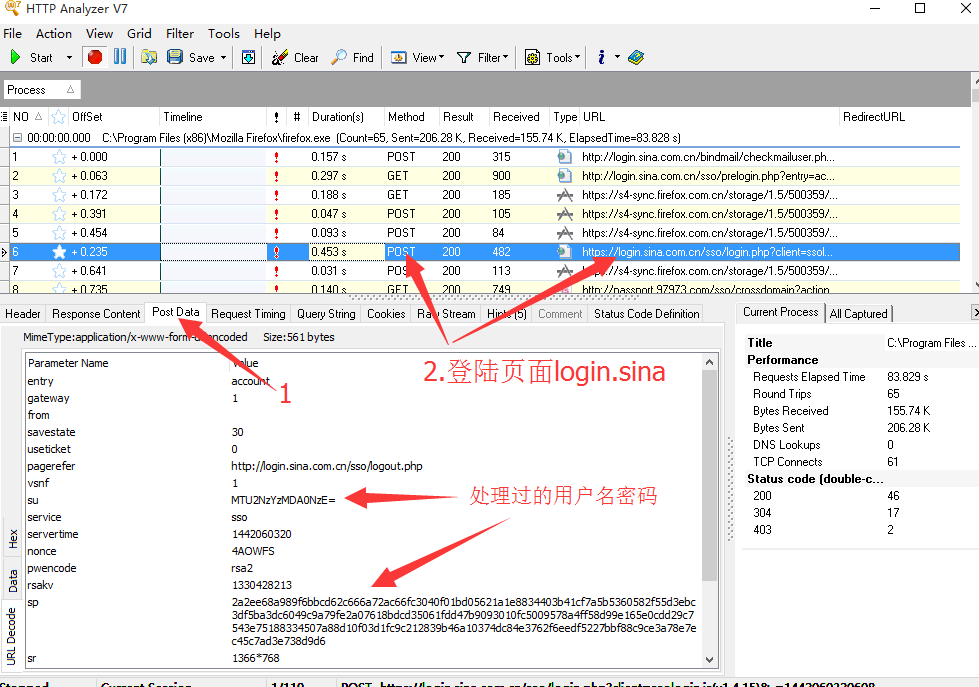
可以看到,最后通过post请求提交的表单中包含了用户名(su,sinauser缩写)、密码(sp,sinapassword缩写);
此外还有一些不知道的参数(servertime、nonce、rsakv),这些参数都是登陆必不可少的(再次感谢敲代码的耗子);
其他的还有参数,如savestate应该是cookies有效期,这些自己看着办。
2.get请求验证数据
其实,在发送post请求之前,浏览器会先向以下url(username是用户名)发送一个get请求,在get请求返回的数据中利用正则匹配提取servertime、nonce、pubkey、rsakv四个的值。过程如下:
url = 'http://login.sina.com.cn/sso/prelogin.php?entry=sso&callback=sinaSSOController.preloginCallBack&su=%s&rsakt=mod&client=ssologin.js(v1.4.4)%username'
html = requests.get(url).content
servertime = re.findall('"servertime":(.*?),',html,re.S)[0]
nonce = re.findall('"nonce":"(.*?)"',html,re.S)[0]
pubkey = re.findall('"pubkey":"(.*?)"',html,re.S)[0]
rsakv = re.findall('"rsakv":"(.*?)"',html,re.S)[0]
3.加密过程
在1中我们利用工具分析得知post提交的数据中用户名与密码都是经过加密处理的,所以我们必须先对用户名与密码进行加密才能发送post请求。
加密用户名:
username = base64.b64encode(username)
密码采用的是rsa算法加密方式:
rsaPublickey = int(pubkey, 16) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3129
3129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









