









获取淘宝MM的所有用户主页的图片。以下是代码(包含注释),运行环境是win、python2.7.10:
#coding:GBK
import requests
import json,re
from lxml import etree
import urllib
import os
def get_totalpage():
'''获取所有页面总数'''
url = "http://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8&q=&viewFlag=A&sortType=default&searchStyle=&searchRegion=city%3A&searchFansNum=¤tPage=1&pageSize=100"
html = requests.post(url).content.decode('gbk')
html = json.loads(html)['data']
totalPage = html['totalPage']
return totalPage
def get_info(page):
'''获取前page页MM的数据:包括姓名、uid、主页url(其他所在城市、身高、体重、粉丝等这里就不提取了)'''
totalPage=get_totalpage()
if page>totalPage or type(page)!=int or type(totalPage)!=int:
print u'请输入1~'+str(totalPage)+u'的整数'
else:
print u'检测到总共有'+str(totalPage)+u'页'
print u'---------------------------'
realName = []
userId = []
userurl = []
for p in range(1,page+1):
url = 'http://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8&q=&viewFlag=A&sortType=default&searchStyle=&searchRegion=city%3A&searchFansNum=¤tPage='+str(p)+'&pageSize=100'
html = requests.post(url).content.decode('gbk')
html = json.loads(html)['data']['searchDOList']
for data in html:
Name = data['realName'] #真实姓名
Id = data['userId'] #用户ID
url = 'https://mm.taobao.com/self/aiShow.htm?userId='+str(Id) #个人主页
realName.append(Name)
userId.append(Id)
userurl.append(url)
print str(p)+'/'+str(totalPage),u'获取成功......'
return userId,realName,userurl
def get_img(url):
'''返回包含淘宝MM主页的所有图片url的一个列表'''
html = requests.get(url).content.decode('GBK')
html = etree.HTML(html)
src = html.xpath('//div[@class="mm-aixiu-content"]//img/@src')
img = []
for i in src:
jpg = 'https:'+i
if re.findall('(.*?).jpg',jpg)!=[]:
img.append(jpg)
img = list(set(img)) #去除重复url地址
return img
#----------------------------------------------------------------------------------
print u'''
* * * * * * * * * * *
* 名称:获取淘宝MM图片
* 作者:song
* 版本:1.0
* * * * * * * * * * *
'''
totalpage = get_totalpage() #获取总页数(我写这个爬虫时有399页,每页有100个用户,差不多有39900个用户)
uid,uname,url = get_info(totalpage) #获取所有页面的个人信息(主要是获取个人主页url、用户名)
#遍历列表url,获取所有用户图片
for i in range(len(url)):
img = get_img(url[i])
#判断文件夹是否存在,如果不存在则新建一个文件夹
path = 'D:/taobao/'+uname[i]+'/'
if os.path.exists(path)!=True:
os.makedirs(path)
#下载图片到刚刚创建的目录(我这里指定到D:/taobao/下,每一个人单独一个文件夹)
for j in range(len(img)):
urllib.urlretrieve(img[j],path+str(j+1)+'.jpg')
print uname[i],str(j+1)+'/'+str(len(img)),img[j]
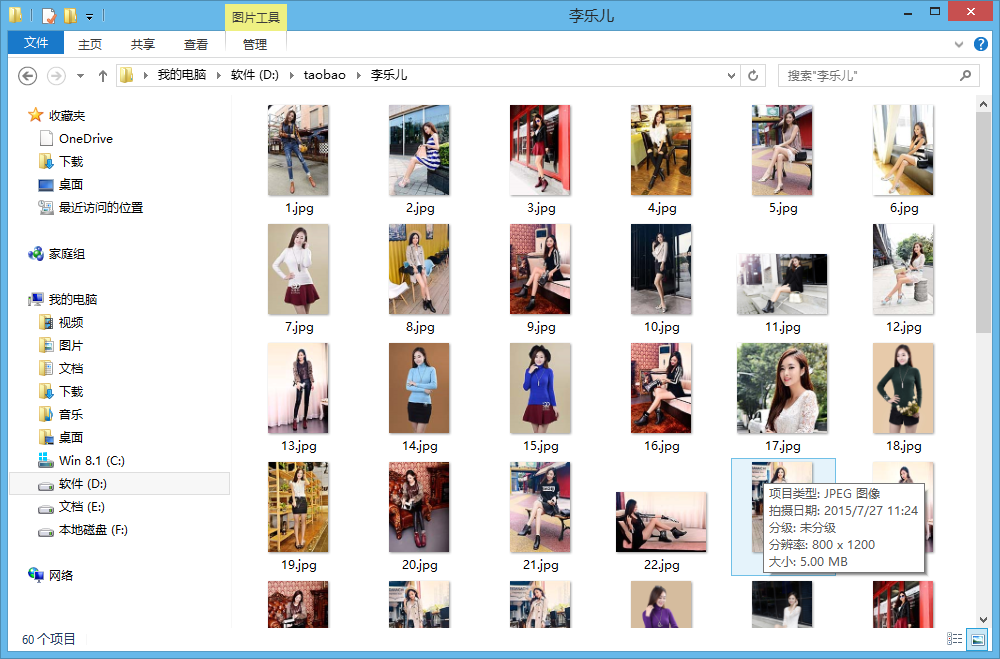
以下是部分下载的图片:
欢迎访问我的个人站点:http://bgods.cn/
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









